
Mivel a jelenlegi adathalmaz elég kicsinek mondható, így nem olyan egyszerű olyan kísérletet összeállítani ami hozza az elvárt precizitást, megbízható eredményt szolgáltat (fontos néhány alkalmazás tekintetében, hogy a felhasználó mit kap vissza válaszként), ugyanakkor nagy mértékben csökkenti a magolás bekövetkezését. Ezért megnézzük a tanulás eredményét abban az esetben, ha az adatokat egy kicsit felturbózzuk (mármint példányszámban).
Birthmarks data #6 – SMOTE training
Reply
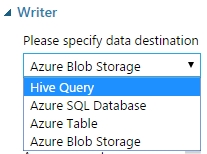 Az aktuális adathalmazunkat, vagy eredményeinket, részeredményeinket (lényegében bármit) el tudunk menteni a Writer modul segítségével. A modul a Data Input and Output csoportosítás alatt található. A modul segítségével írható Hive Query, Azure SQL Databse, Azure Table és Azure BLOB Storage.
Az aktuális adathalmazunkat, vagy eredményeinket, részeredményeinket (lényegében bármit) el tudunk menteni a Writer modul segítségével. A modul a Data Input and Output csoportosítás alatt található. A modul segítségével írható Hive Query, Azure SQL Databse, Azure Table és Azure BLOB Storage.