
Az anyajegyek adatait tartalmazó adathalmazunk első körben készen áll arra, hogy felhasználjuk tanulásra. Elkészítettem pár osztályozó algoritmus modelljét, amiket majd összehasonlítási alapként fogok használni a további finomhangolás és egyebek után. A folyamat végén majd valamikor végül a legjobban működő modellt fogjuk kiválasztani, amiből elkészül a web service.
Tanulás
Hogyan is nézett ki eddig a kísérletünk? Valahogy így:
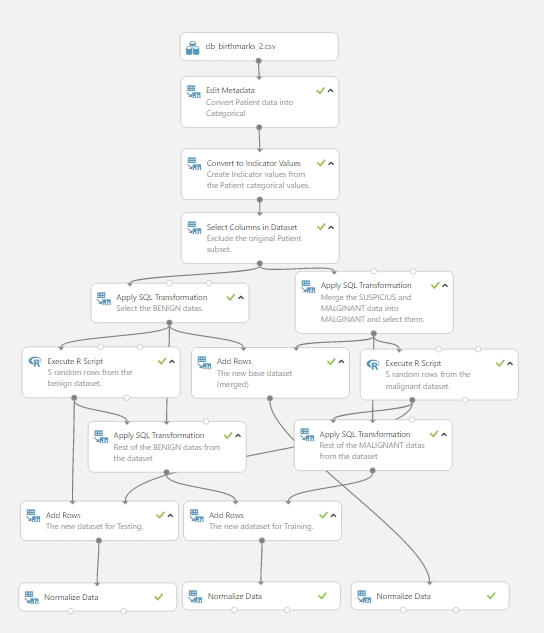
Itt ugyebár csak szemléltettem a korábbi bejegyzésben, hogy kell egy kis normalizálás az adatokon, ez szép és jó, azonban ennyire lebontani felesleges ezt a lépést, így egy kicsit most átalakítottam a “fát”, és a normalizálást korábban hajtottam végre, ugyanazokkal a beállításokkal. Ezek után a kísérlet így néz ki:
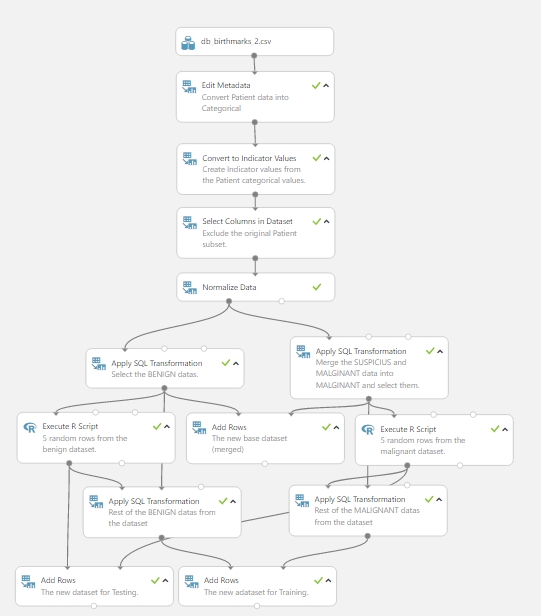
Theát, vissza a tanuláshoz…. Először is, ki kellett válogatnom, hogy mi lesz feature. Első körben a Filter Based Feature Selection modult használtam (majd később előjön a már előre válogatott lista is, amit néhány bejegyzéssel korábban írtam). Ehhez behúztam a munkaterületre a Feature Selection menüből a Filter Based Feature Selection modult, és a bemenetéhez hozzá kapcsoltam a tanító adathalmazomhoz. A tulajdonságoknál megadtam, hogy jelenleg a Mutual information alapján keressen nekem featuret, majd a column selector segítségével megadtam, hogy a Diagnosis oszlop az ami a címke jelen esetben és végül a Number of desired features szám az 8-at kapott (korábban említettem, hogy általában 10% körül szokott lenni a featureök száma az adathalmazban szereplő oszlopokhoz képest, ez lefele kerekítve jelen esetben 8-t jelentett).
Egy kicsit közelebbről a FBFS modul (korábban egy régi bejegyzésben már beszéltünk nagy vonalakban arról hogy mit is csinál ez pontosan, de most nézzük konkrétan erre az esetre):
- Alapvetően számszerűsítve meghatározza nekünk, hogy a bemenetre kötött adathalmaz mely oszlopai szolgálnak a legnagyobb “prediktív erővel”. A modulnak két kimenete van, a bal oldalin az új adathalmazunkat kapjuk meg, a leválogatott feature elemek szerint szűre, azaz csak azok az oszlopok szerepelnek már az adathalmazban amik megfeleltek az elvárásoknak. A jobb oldali kimeneten megkapjuk a teljes oszlop listát, azonban az adatok helyet csupán egyetlen sort kapunk, melyben minden egyes oszlophoz meg van adva a kiszámított “prediktív erő”, amely alapján akár mi manuálisan is ki tudjuk gyűjteni azokat a feature-ket amikre szükségünk lesz.
- Mit is csinál a Mutual Information? Jelen esetben azt méri, hogy a címkéhez viszonyítva (ami itt a Diagnosis) az egyes változók mennyivel járulnak hozzá a pontatlansághoz (ennek a pozitív kihatású értéket adja vissza számszerűen a végén). Rengetek fajtája létezik, mert rengeteg helyen használható. Az algoritmus rendszerint nagyon hasznos a feature meghatározásban, mert maximalizálja a közös információértéket elég nagy dimenzióban.
- Értelemszerűen a modellnek szükséges egy olyan inputot megadni amiben egynél több oszlop van, ugyanakkor ez a megoldás nagy oszlopszámú adathalmazra a legjobb.
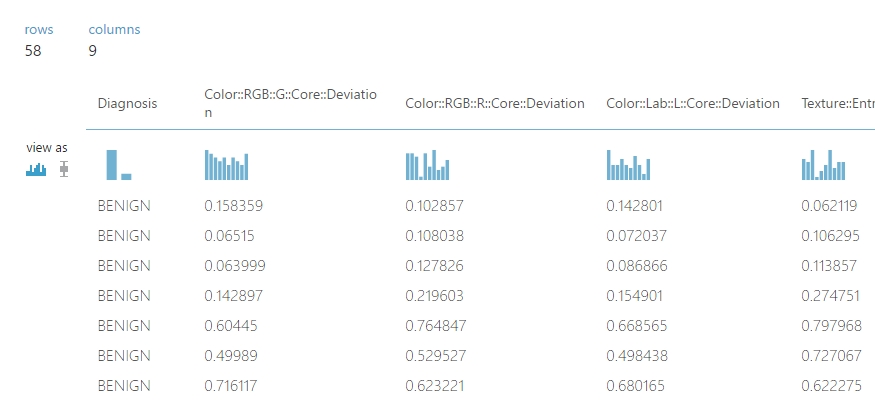
A végeredmény jelen esetben nálam ez lett (amint látható a képen, 8+1 (a címke oszlop) feature található az új adathalmazban, ahogyan szerewtük volna):
Osztályozó algoritmusok hozzáadása
Két osztályos tanulásról van szó, tehát a következő listából kellett választanom:
Ezek nyilván nem sokat mondanak ebben az állapotban. Gondolkodás is progress… van egy ügyes cheat sheet ehhez (letölthető ezen a linken de ezt már szintén tárgyaltuk az algoritmus választó bejegyzésben):
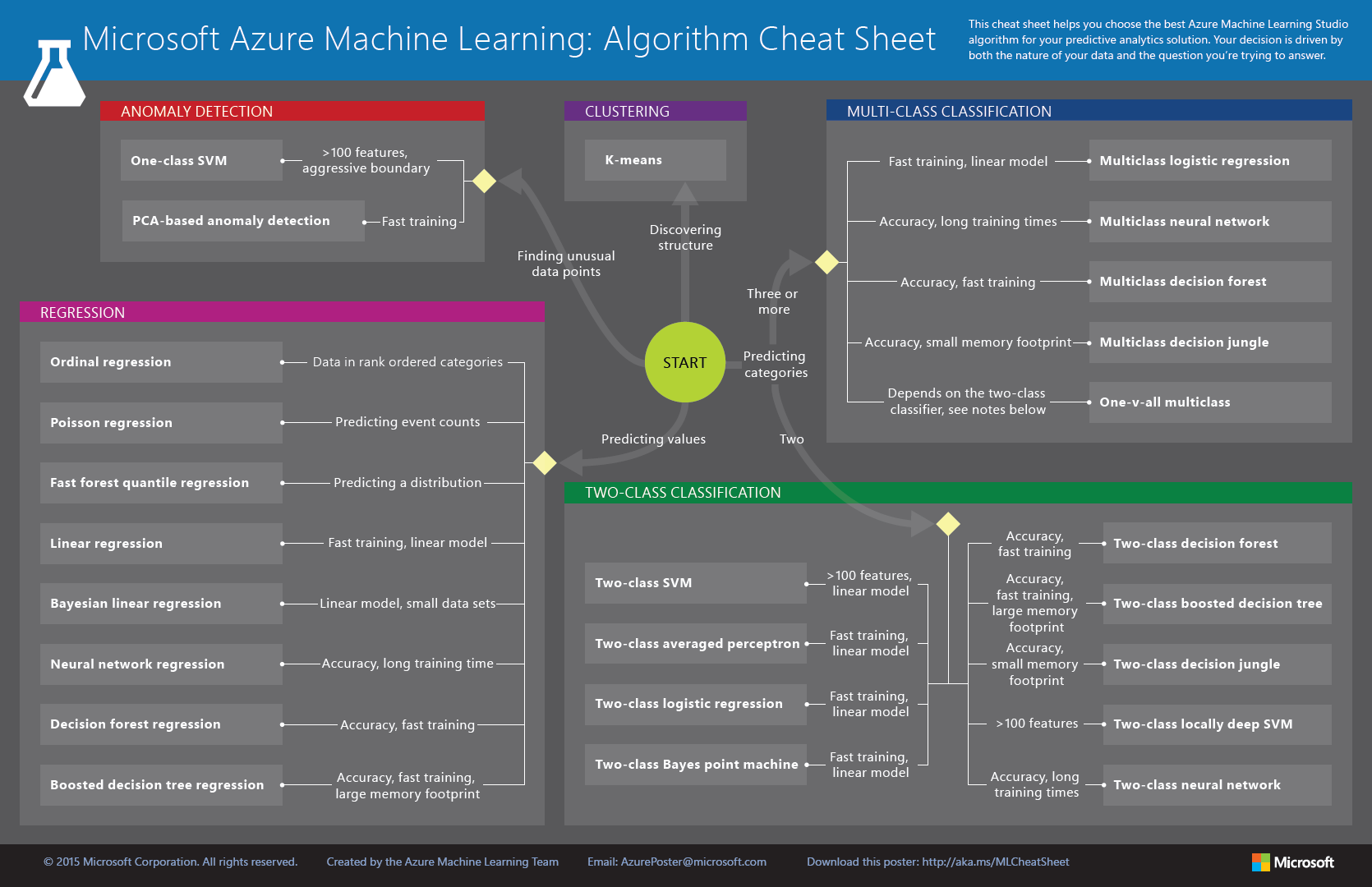
Ez segített mint egy kisgyereknek, hogy merre menjek, de persze döntéseket hozni kellett itt is. Start -> Predicting categories -> Two -> (itt kellett dönteni, hogy mit szeretnénk, és mi az ami rendelkezésünkre áll az adatokat tekintve, van-e több mint 100 feature a listánkban, gyorsaság kell, pontosság vagy esetleg kicsi tárigény…) én itt elsősorban a populárisabb elsőnek mindenkinek az eszébe jutó algoritmusokat választottam, de mindjárt látható lesz, hogy többet is felpakoltam, hogy legyen viszonyítási alap. Tehát ilyen algoritmusokat néztem meg: Two-class decision jungle, Two-class decision forest, Two-class boosted decision tree és Two-class neural network. Az SVM-et is kipróbáltam, de annak igazán jelentős szerepet akkor mertem volna tulajdonítani, ha valóban lenne több mint 100 darab kiválogatott feature a listában, de ehhez nyilván egy gigantikusabb adathalmazra lenne szükség.
Egy példán megmutatom, hogyan raktam össze egy tanító részt, a többit hasonló módon simán meg lehet csinálni (Megjegyzem, itt még nincs további manipuláció, csupán a feature listával dolgozunk, nincs sweep, nincs semmi más).
Fogtam a Two-class Decision Forest modult, behúztam a munkaterületre, behúztam egy Train Model modult is aminek a bal oldali bemenetére bekötöttem az előbb behúzott TDF modul kimenetét. Majd egy Score Model modult is hozzáadtam a kísérlethez, aminek a bal oldali bemenetére rákötöttem a Train Model kimenetét, a jobb oldali bemenetére pedig a tesztelésre szánt adathalmazomat (amin nem végeztem feature szelekciót, mert nem szükséges (tapasztalataim szerint), csak azokat az adatokat fogja felhasználni amik szerepelnek a szelektáltak között). Majd a Train Model tulajdonságainál a column selector használatával kijelöltem, hogy a label column az nem más mint a Diagnosis oszlop.
Ahol több mindent be kellett állítani, az maga az algoritmus modult volt.
- Resampling method: azaz hogy mi alapján építsen fel egy fát amit a döntéshez használ? van Bagging és Replicate lehetőség. Az első esetben random mintavételezést csinál az eredeti adathalmazból adatcseréléssel, amíg kapunk egy ugyanakkora fát mint az eredeti, és ebben végzi el az algoritmus a csodát. A második esetben nem csinál semmi mintavételezést és nincs random fa, hanem pontosan az eredeti felállás szerint használja az adatokat, de maga a végső választás az itt is random marad amikor ki kell választani hogy melyik node legyen használva a fában. Én hagytam az alapbeállításokon, azaz a Bagging.
- Create a trainer mode: azt mondjuk meg, hogy hogyan akarjuk kiképezni a modellt. Single prameter, ha tudjuk, hogy pontosan mely paramétereket fogjuk felhasználni, akkor ezt kell választani, viszont ha nem vagyunk biztosak a megfelelő paraméter választásban, akkor a Parameter Range használatos, ahol meghatározhatjuk az optimális paramétereket, több változó segítségével és használhatjuk a Tune Model Hyperparameters modult az optimális konfigurációhoz. A rendszer egy csomó kombinációt fog kipróbálni, hogy meg tudja mondani mi a leginkább hatásos paraméter kombináció a rendszerüknek. Mivel itt tudtam, hogy mit szeretnék, így a Single parameter opciót válaztottam.
- Number of decision trees: értelemszerűen azt adhatjuk meg, hogy mennyi döntési fa generálódjon a művelet során. természetesen minél több fát adunk meg annál jobb lefedettséget érünk el, azonban ez a feldolgozási idő növekedésével fog járni. jelen esetben a 6-t választottam.
- Maximum depth of the decision tree: a generált fák maximum mélysége. Óvatosan kell itt is a számot meghatározni, ugyanis a nagyobb mélység jótékony a pontosságra nézve, ugyanakkor nagyon nagy hatással van a túlillesztésre ill. a futásidőre. Itt a az alap érték a 32, és jelenleg ezen is hagytam, mert a fák számát csökkentettem, ugyanakkor az adathalmazom nem egy hatalmas, így talán egy kicsit kompenzálva vannak a negatív hatások.
- Number of random splits per node: annak a száma, hogy faépítés közben a hány vágást használjunk a node-hoz. Ezt nem bántottam, 128.
- Minimum number of samples per leaf node: azt a minimum a esetszámot jelöli, ami szükséges ahhoz, hogy egy levelet készítsünk a fában. Mivel kevés adatom van ezért hagytam 1-n.
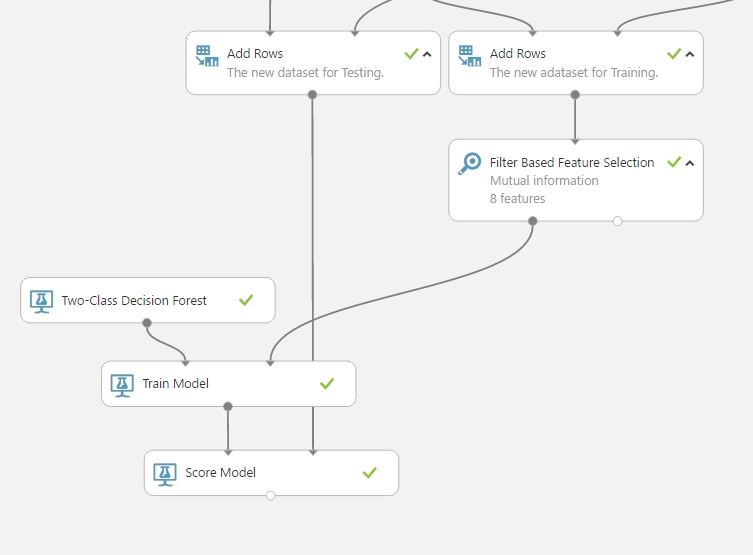
És ennyi, több állítgatásra és modulra nincs szükség ahhoz, hogy egyszerűen az eddig dolgozott adatokból kinyerjünk végre valami prediktív információt. Így nézett ki nálam a munkaterület:
A futtatás után a következő eredményt kapjuk, amit a Scorte Model kimenetén a Visualize segítségével tekinthetünk meg:
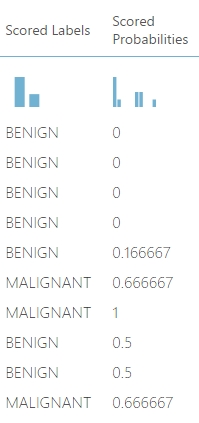
Alapértelmezésben egy ilyen modellben a probalilities-nek 0.5-nél (0 és 1 az intervallumunk amit használ) nagyobbnak kell lennie ahhoz, hogy ne az első hanem a második osztályba tegye, azaz az egyenlőség nem számít (ezt ízért írom, mert az első 5 adatnak BENIGN a második 5 darabnak pedig MALIGNANT osztályúnak kellene lennie).
A fentebb említett 3 másik algoritmussal kiegészítve így néz ki a kísérlet (a többi algoritmusnál többé kevésbé az alap beállításokat használtam, mert majd az alap eredmények értelmezése után szerettem volna finomítani, hogy megtaláljam a legjobb választást):
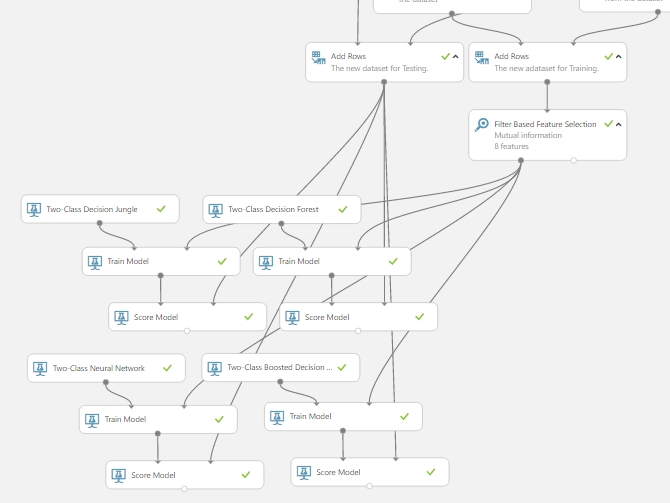
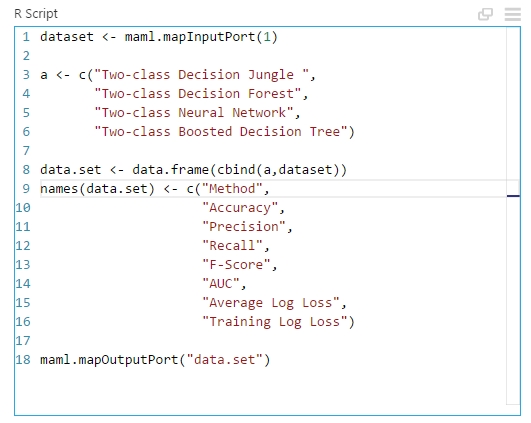
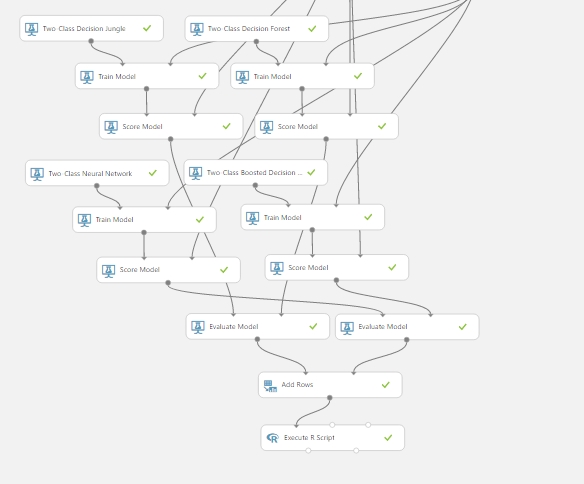
Ennek a kiértékelésére készítettem egy összesített táblázatot, amihez szükségem volt az Evaulate Model modullra (ami ugye kiértékeli a modellünket), néhány Add Rows modulra (ami az egyes adathalmazokat egymás alá fűzi, vagyis az adathalmazok sorait) és végül egy Execute R script modulra. Hogy mit is kezdtem ezekkel? Fogtam kettő darab kiértékelő modult, és rákötöttem a 4 darab Score Model kimenetet, majd a kiértékelő modulok kimeneteit összefőztem, hogy nagy adathalmazt kapjak az egyes kiképző modellek kiértékeléseiből. Majd egy R script segítségével készítettem egy összesítő táblázatot az algoritmusok neveivel és az adott értékekkel. Az ehhez használt R kód a következő (lényegében csak az adatokat fűztem egybe…):
Majd végül az eredmény a következő lett:
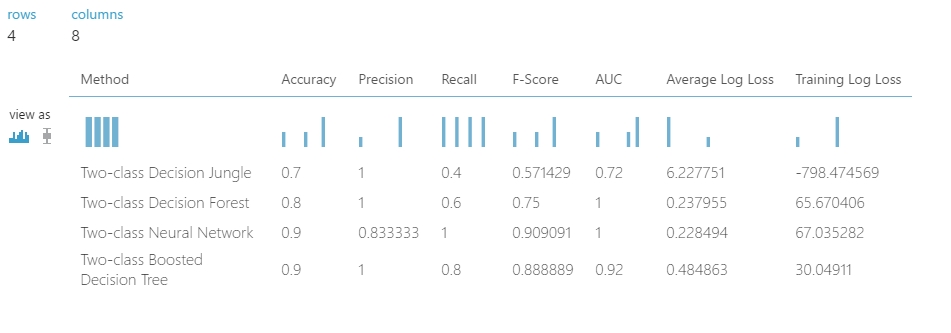
A táblázatban remekül látszik minden olyan információ amire szükségünk lehet ahhoz, hogy finomítsuk az egyes algoritmusok paramétereit vagy kiválasszuk azt amelyre szükségünk lehet. Ennek az értelmezését egy következő bejegyzéshez meghagyom… 😀