
Mivel a jelenlegi adathalmaz elég kicsinek mondható, így nem olyan egyszerű olyan kísérletet összeállítani ami hozza az elvárt precizitást, megbízható eredményt szolgáltat (fontos néhány alkalmazás tekintetében, hogy a felhasználó mit kap vissza válaszként), ugyanakkor nagy mértékben csökkenti a magolás bekövetkezését. Ezért megnézzük a tanulás eredményét abban az esetben, ha az adatokat egy kicsit felturbózzuk (mármint példányszámban).
SMOTE
Ehhez van a már korábban röviden ismertetett SMOTE module. Mit takar pontosan a neve: Synthetic Minority Oversampling Technique, ami lényegében egy statisztikai technika arra, hogy az alacsony példányszámmal rendelkező eseteket növeljük az adathalmazban, természetesen arányosan a már meglévő példányszámokkal. Lényegében megpróbálja kiegyenlíteni valamelyest az adathalmazt, ez akkor hasznos, ha az az osztály mondjuk amit analizálni akarunk egy kicsit alul-reprezentált. Ilyen eset számos ok miatt előfordulhat, mondjuk azok az adatok amelyekkel reprezentálni akarjuk az osztályunkat nagyon ritkának mondhatóak vagy egyszerűen csak nehéz hozzájutni nagyobb mennyiségű valid adathoz. Ez a modul nem csak egyszerűen fogja és duplikálja az adatokat, hanem újakat hoz létre.
Hogyan működik? Mint fentebb írtam, a bemenetre adott adathalmazból készít új példányokat. Az új példányokat úgy készíti, hogy mintát vesz minden egyes célosztály adataiból és annak a legközelebbi szomszédaiból és ezeknek a kombinációiból készül az új példány. Az egész bemeneti adathalmazt nézi, de csak a kisebbségben előforduló eseteket növeli. Például ha van egy adathalmazunk amiben van két osztály, az első 1% az adatoknak a második 99% az adatoknak, akkor simán meg tudjuk duplázni az 1% adathalmazunkat úgy, hogy a másik osztály adathalmaza érintetlen marad a példányszámokat tekintve. Nos szerintem ennyire elragozva már érthető, hogy mit is akarok most csinálni….
beillesztés a kísérletbe…
Alapesetben a tanításra szánt adathalmazomban volt 48 példány a BENIGN esetre és 10 példány a MALIGNANT esetre.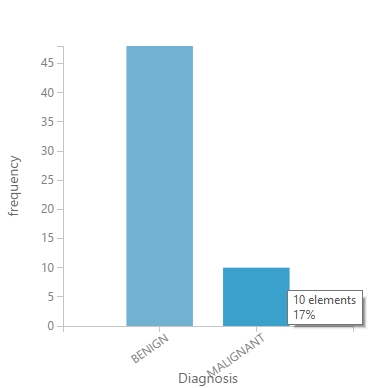
Miután bekapcsoltam a smote modult a kísérletbe a következő eredmények születtek, 100, 200, 300, 400 és 500 százalékos értékeket megadva:
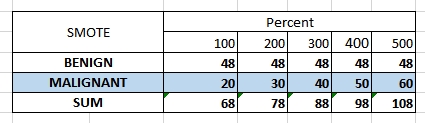
Jól látszik, hogy hogyan változnak az egyes értékek mentén a példányok előfordulás számai. Ugyanakkor azt is megjegyezném itt, hogy ez a modul SOHA nem fog hozzányúlni az alap bemeneti adathalmaz szerint kisebbségben lévő osztály példányszámához. Látszik is a fenti táblázatban, hogy 400 és 500 százalékos esetekben már átléptük az 50%-os részvételi arányt és a BENIGN címkéjű példányok száma nem váltott.
A táblázatot nézve én olyan 200-300 közötti értéket gondolok jónak, azért ennyi adatból nagyságrendekkel több példányt előállítani sem szerencsés azt gondolom, ugyanakkor egy közel 40-50% körüli részesedés már bőven elegendő a kísérletünkhöz.
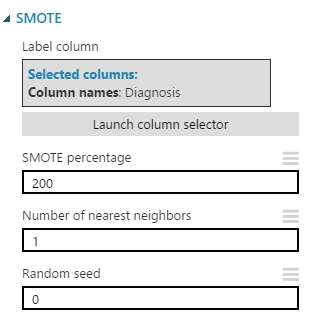
Na de hogyan is használjuk ezt a modult? Miután hozzáadtam a munkaterülethez, a bemenetére egyszerűen bekötöttem a tanításra kiválogatott adathalmazomat. A modul tulajdonságainál, a már jó ismert column selector segítségével ki kell választani, hogy az adathalmazban melyik oszlop képviseli az osztálycímkéket. A SMOTE percentage input mezőnél egyértelműen megadtam, hogy akkor 200 as értékkel (százalékkal) szeretném növelni a kisebbségi osztályok példányszámát. A Number of nearest neighbors input mezőbe azt a számot adtam meg, ami meghatározza, hogy hány szomszédot vegyen alapul amikor kombinálja a modul az új példányokat. Végül a Random Seed input mezőbe azt a számot kellett megadnom, ami a nevéből adódóan is jön, ami a mintaválasztást befolyásolja, ha ide nem adok meg csak egy 0-át akkor a rendszer alapértelmezettként a rendszeridőt fogja használni. Megjegyezném azt is, hogy ha a szomszédsági számnál kis értéket adunk meg, akkor az új példányok jobban fognak hasonlítani az eredeti halmazra, ha nagyobb számot akkor egy értelemszerűen több mintát felhasználva fog meghatározni egy új példányt ami azt eredményezi, hogy nem lesz túl nagy hasonlóság az eredeti adathalmazoz. Az beállítások a következők lettek:
Kiértékelés…
Nos miután meglett a felfejlesztett adathalmazom, kíváncsi voltam, hogy ugyanazokat a tanuálsi algoritmusokat használva a beépített Filter based feature selection modult felhasználva milyen eredményeket kapok és mennyivel lesz rosszabb vagy jobb a tanulás (itt egy link az előző bejegyzéshez). Ehhez megismételtem minden lépést az előző bejegyzésemből, bekötöttem a megfelelő modulokat a kísérletbe, az eredményeket hozzáadtam a korábban ismertetett R scripthez hogy kinyerjem egy táblázatba az adatokat (természetesen ehhez bővítettem a scriptben szereplő adathalmazhoz tartozó fejlécet is), és a végeredmény a következő lett: 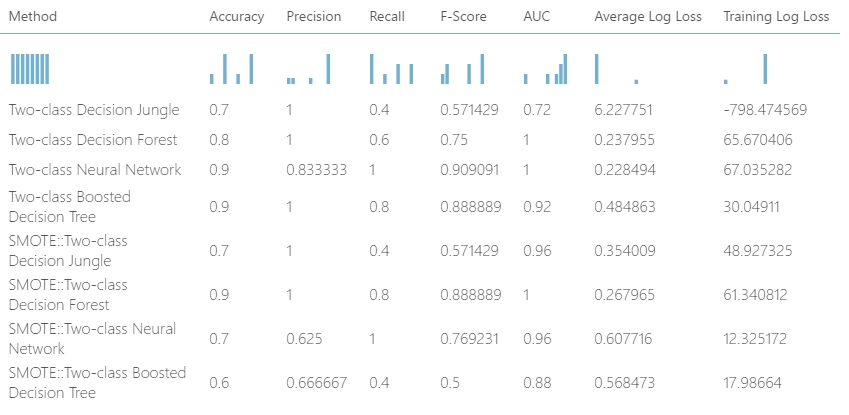
A legtöbb algoritmus beállítás maradt az alapértelmezetten, illetve ugyanarra az értékere lettek állítva mint az előző esetben létrehozott példák.
Azért jó lenne tudni mit jelentenek röviden ezek az értékek, milyen jellemzőkre hatnak (íme a fontosabbak):
- ROC és AUC: általános teljesítmény
- Precision: relevancia
- Recall: alaposság
- Accuracy: korrektség
Egy ilyen helyzetben mint ez is, azaz kétosztályos tanulás, nagyon segítőkész tud lenni a ROC és az AUC értékek vizsgálata, amikor el kell dönteni, hogy melyik algoritmust fogjuk használni. Itt egy kis segítség, hogy az adott értékhatároknak mire kellene rávezetnie:
- 9-1: gyanúsan jó, úgy értem elég gyanús
- 8-9: rendben van, de kezd gyanús felé hajlani
- 7-8: megfelelő modell
- 5-6: értéktelen modell
- ….
Ezek alapján nem túl jó a helyzet, ami biztos, hogy a SMOTE vonalon kell tovább gondolkozni. Az ugyanis pozitív hatással volt az eredményekre (ezt további kísérletezésekkel is ellenőriztem…). Ezért minden elérhető kétosztályos algoritmusra megnéztem, hogy milyen eredmények jönnek ki. A végeredmény a következő lett:
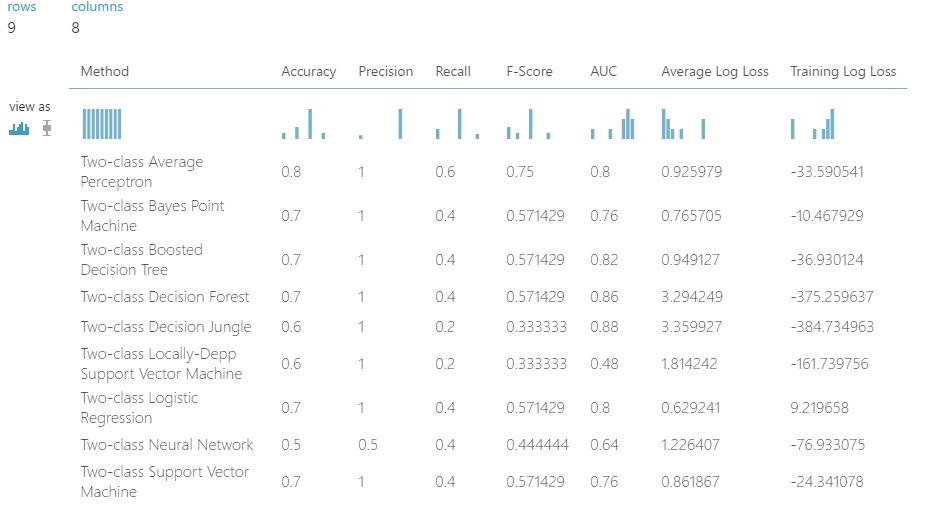
Nos akkor értelmezés… A további munkához értelmetlen lenne minden egyes algoritmust felhasználni, így kettőt választottam ki. Hogyan? Ehhez nézzük meg a látható jellemzőket kicsit közelebbről mint az előbb:
- Accuracy: nyilván ez a legegyértelműbb teljesítményt kifejező mérőszám. Egyszerűen megadja a helyesen megjósolt példányok arányát. Ha csak ezt az értéket akarjuk alapul használni a döntéshez, akkor csak abban helyzetben kimondottan jó ez az arány, amikor az adataink majdnem szimmetrikusak, vagy szimmetrikusak (ilyen a valóságban azért nem sűrűn jellemző).
- Precisioin: a helyes pozitív megfigyelések arányát adja meg. A képlet formulája amely megadja az értéket a következő: True Positives / (True Positives + False Positives). Ehhez nem árt ha értjük, hogy mit jelentenek ezek a kifejezések.
- Recall: ezt másnéven, vagy más környezetben úgy is meg lehet találni, hogy érzékenység vagy True Positive Rate. Lényegében a helyesen megjósolt pozitív példányok arányát adja meg. A képlet ami megadja az értéket: True Positives / (True Positives + False Negatives).
- F-Score: ez az érték a Precision és a Recall súlyozott átlagaként áll elő. Figyelembe veszi a False Positives és False Negatives értékeket is. Ez az érték sokszor hasznosabb mint az Accuracy, főleg ha az adathalmazunk egyenetlen. Akkor működik a legjobban ha a False Positives és False Negatives értékek költségei közel azonosak. Lényeg az ez a formula, amit használ: 2 * (Recall * Precision) / (recall + Precision).
- AUC: ez a rövidítése az “Area Under Curve”-nek, lényegében a ROC (ami a False és True Positive Rate értékek függvénykirajzolása) görbe alatti területének a mérete. Ennek az értéknek soha nem szabadna 0.5 alá mennie (értelemszerűen ez egy 0 és 1 közé eső érték), ott valami nagyon nem stimmel akkor. Ennek az alapján a legjobb és legkönnyebb meghatározni azt, hogy melyik algoritmus lesz a nyerő, ha nem egyértelmű akkor jön a többi értéknek a vizsgálata.
Szóval összegezve, a ROC plot és az AUC érték vizsgálata jó ahhoz, hogy összehasonlítsunk több modellt az adathalmaz felett. Az a model aminek az AUC értéke közel 1 és a ROC plot-ban a kirajzolt vonal közelebb van a felső határhoz, annak igen jó teljesítmény értéke van.
Ezek alapján, választott modelljeim: a Two-Class Decision Forest (amire a pontosság és a gyors képzés a jellemző, és persze a fa szerkezet) a másik pedig egy lineáris modell, ami a Two-Class Average Perceptron. A neurális hálókat azért nem választottam,. mert annak ezekhez képest hosszabb a tanítási ideje, az SVM modellek pedig azért estek ki. mert leginkább akkor ajánlatos őket használni, amikor több mint 100 Feature áll a rendelkezésünkre. Ezekkel fogom a továbbiakban folytatni…