
Ezidáig csak olyan adathalmazokat használtunk, amikben lebegőpontos/egész számok, binárisok, osztálycímkék voltak. Most próbáljunk ki valami mást!
Komplett szövegeket is feldolgozhatunk, majd következtetéseket vonhatunk le belőlük. Egy beépített adathalmazt, a Wikipedia 500 SP Dataset-et használtam, amiben a cégek Wikipedia oldalán található összegző leírás, illetve a cég kategóriája található meg.
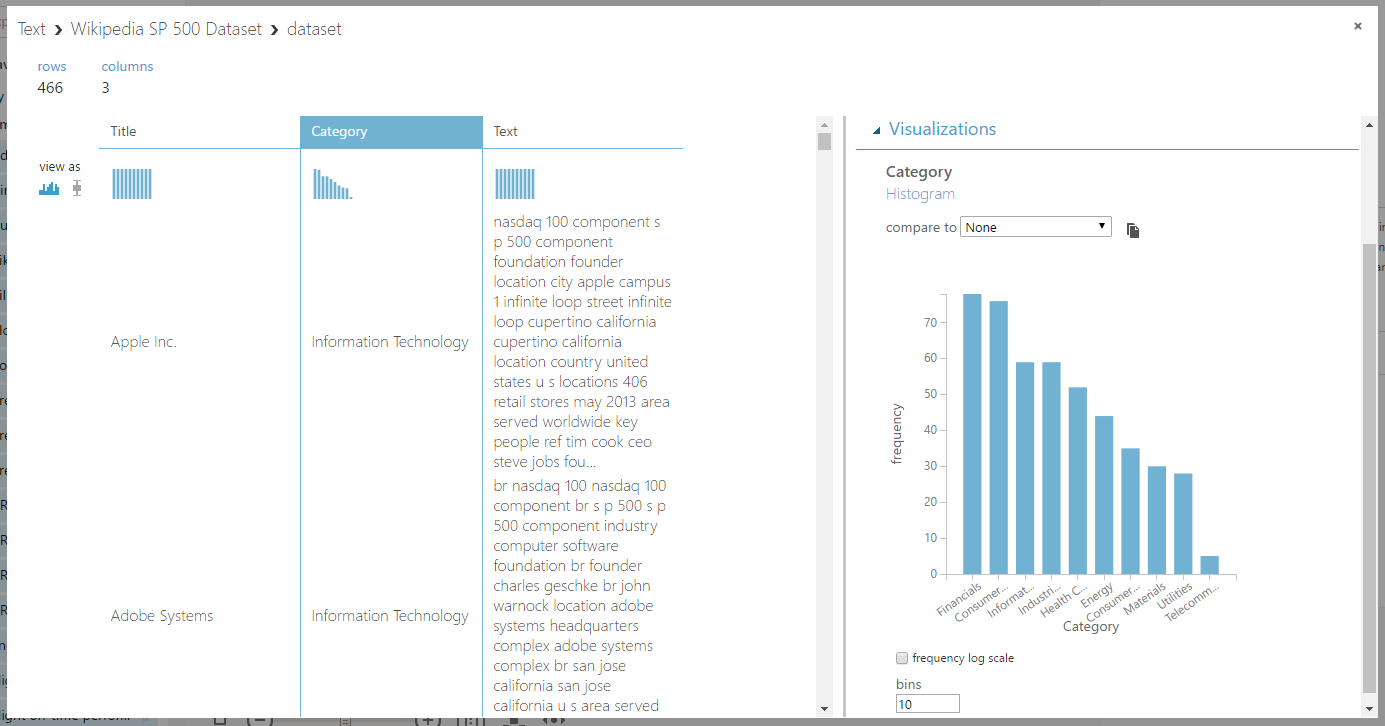
A leírással önmagában nem tudunk mit kezdeni, hiszen a gép számára csak egy oszlop, aminek minden sora egyedi. Ezt a Feature Hashing modullal tudjuk áthidalni.
A megadott szövegből rengeteg egész típusú oszlopot készít, amit már fel tudunk használni egy tanuló algoritmushoz. Először is ki kell választani az oszlopot (vagy oszlopokat), amit hashelni szeretnénk. Meg kell adni az N-grammok számát (1 – unigram, 2 – bigram, 3 – trigram, …), ez azt jelenti, hogy milyen egységekre szedje szét a szöveget az algoritmus. 1 esetében minden szó külön lesz, 2 vagy több választása mellett azonban szóbajönnek a kettes/hármas szópárok is. Azért lehet ez fontos, mert például az a szó, hogy “jó” értelem szerűen jót jelent. Azonban, ha úgy áll a mondatban, hogy “nem jó”, akkor az pont az ellentetje. Ha két vagy három szót egyben is elmentünk, akkor az pontosabb képet adhat számunkra. A másik paraméter a Hashing bitsize pedig azt adja meg, hogy hány bitet használjon a hash tábla elkészítéséhez. Ez befolyásolja azt, hogy hány oszlopunk lesz a hash után.
A Vowpal Wabbit nevű projektet használja fel a felbontáshoz. Az algoritmus változó hosszú szöveget is képes feldolgozni. Sajnos egyelőre csak angol szövegeket ért meg.
Ha ezzel megvagyunk, egy újabb problémába ütközünk: most már túl sok feature van (több ezer), ami valószínűleg rengeteg felesleges információt / redundanciát tartalmaz, és így nem lenne hatékony a tanuló algoritmus. Tehát csökkentenünk kell a számukat. Erre is több lehetőségünk van: vagy kiszűrjük a leginkább lényegtelenebbeket, vagypedig kevesebb oszlopba konvertáljuk őket. Az elsőre egy példa a Filter Based Feature Selection, ami a leginkább releváns N oszlopot tartja meg. A második megoldás lehet például a Principal Component Analysis (Főkomponens-analízis, ha így ismerősebb statisztika óráról…), ami megadott számú oszlopot hoz létre az eredetiekből.
Én most az utóbbit használtam. Valami oknál fogva a PCA modul igen lassú, ezért ha nagyon szorít az idő, érdemes lehet egy saját implementációt használni helyette, R-ben például egy sorral megoldható, és lényegesen gyorsabban lefut.
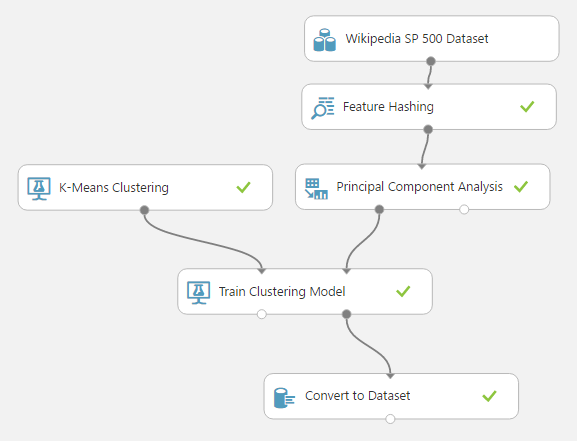
Most már különösebb meglepetés nem érhet, bekötjük az algoritmust, a hozzá tartozó tanító modult, és jöhet a paraméterek állítgatása, hogy a lehető legjobb eredményt kapjuk. A végeredmény valami ilyesmi:
 Van még egy érdekes modul, a Named Entity Recognition. Ez a bemeneti szövegben felismeri a neves embereket, helyeket és szervezeteket, majd a megtalált szavakat a kimeneti adathalmazban adja vissza, a szövegben való elhelyezkedésével és típusával együtt.
Van még egy érdekes modul, a Named Entity Recognition. Ez a bemeneti szövegben felismeri a neves embereket, helyeket és szervezeteket, majd a megtalált szavakat a kimeneti adathalmazban adja vissza, a szövegben való elhelyezkedésével és típusával együtt.
Az alábbi szöveget engedtem rá a modulra:
“Emma loves to be at Paris.
Microsoft recently bought Linkedin.”
Az eredmény pedig:
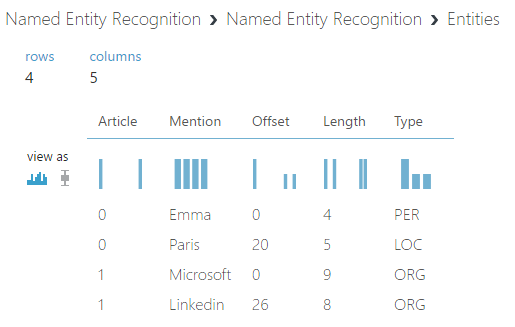
Megadja, hogy az adott szó melyik sorban, melyik oszlopban található, milyen hosszú, és természetesen milyen típusú. Sajnos ez is csak angol nyelvet ismer, azonban a későbbiekben lehetőség lesz a jobb oldali bemenetére egy ZIP-et kötni, amivel képes lehet újabb dolgokat felismerni.
Jelenleg egy beépített képfeldolgozó modul van a rendszerben, a Pre-trained Cascade Image Classification, aminek a neve is mutatja, hogy egy előre kitanított modell. Arcfelismerésre használhatjuk, a Score Model bal oldali bementén. Paraméterként megadhatjuk a sklázódás mértékét, azaz, hogy milyen gyorsan növelje a program a keresőablak méretét, illetve a Minimum number of neighbors az algoritmus szigorúságát állítja: minél nagyobb, annál pontosabb, viszont annál kevesebb arcot ismer fel.
Kép betöltésére az Import Images modult alkalmazhatjuk, ami előállítja a kép 3 csatornájából az egész oszlopokat, majd ezt kell a Score Model jobb oldali bemenetére kötni. Megadhatjuk URL-lel, vagy a Blob Storage azonosítójával és elérési útjával a képeket.
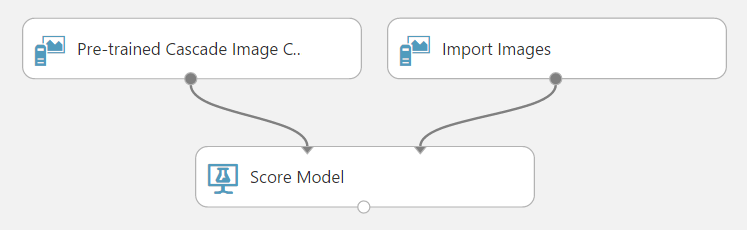
Érdemes kiválasztani a folyamat végén a “Scored Labels” és a “Scored Probabilities” oszlopokat, és a többit eldobni, hogy lássuk a szerkesztőben is az eredményt a futtatás után (ezek az utolsó oszlopok, és a sok feature miatt nem jeleníti meg a szerkesztő őket).