Egy Android alkalmazás egy vagy több alkalmazás komponensből épül fel:
- Activity (a program egy “ablaka”)
- Service (háttérben futó szolgáltatás)
- Content Provider (adatok kezelése)
- Broadcast Receiver (rendszerszintű eseményekre reagál)
Minden komponensnek különböző szerepe van az alkalmazáson belül. Bármelyik komponens önállóan aktiválódhat. Akár egy másik alkalmazás is aktiválhatja az egyes komponenseket.
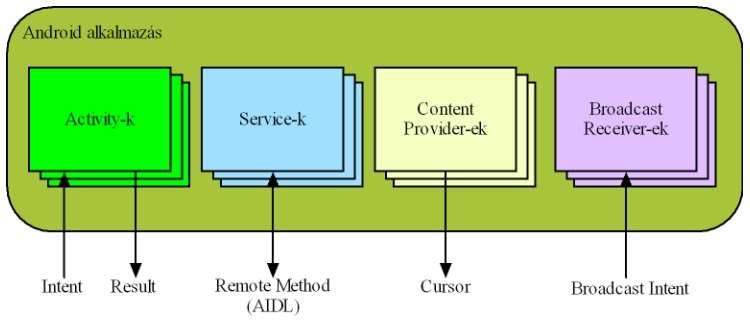 |
| Android alkalmazás komponensek. |
Activity: egy-egy Activity leszármazott egy-egy képernyő a mobil eszköz kijelzőjén. Egyszerre mindig csak egy Activity látható, de egy alkalmazáshoz több képernyőkép tartozhat, amelyeket futás közben – események hatására – szabadon cserélhetünk. Minden programnak kell legyen egy belépési pontja, amely az az Activity leszármazott, amelyet először mutat meg a felhasználónak. Minden Activity az android.app.Activity osztályból származik le.
Service: sok alkalmazás igényli, hogy bezárt ablakkal is képes legyen futni a háttérben, ezt szolgáltatásként megteheti, egyszerűen kell egy Service osztályból leszármazott példány, így marad a programunknak olyan része, amely a felfüggesztett Activity esetén is fut (gondoljunk például egy média lejátszóra). Minden szolgáltatást addig futtat a platform, amíg azok be nem fejeződnek, s a futó alkalmazások képesek hozzákapcsolódni a szolgáltatásokhoz, így képesek vagyunk vezérelni a háttérben futó szolgáltatást. Az android.app.Service osztályból kell öröklődnie.
Content Provider: általában minden alkalmazás tárol adatokat két futás között, hiszen ha felfüggesztés helyett bezárnánk az alkalmazást, akkor elvesznének az addig összegyűjtött adatok. A Content provider (tartalom szolgáltató) komponens feladata egy megosztott adatforrás kezelése. A platformon lehetőségünk van állományokba vagy SQLite adatbázisba menteni adatokat, és ezt segíti a Content Provider, illetve lehetővé teszi, hogy két alkalmazás adatokat cseréljen egymással. A Content provider-en keresztül más alkalmazások hozzáférhetnek az adatokhoz, vagy akár módosíthatják is azokat pl.: CallLog alkalmazás, ami egy Content provider-t biztosít, és így elérhető a tartalom. Az android.content.ContentProvider osztályból származik le és kötelezően felül kell definiálni a szükséges API hívásokat.
Broadcast Receiver: a Broadcast receiver komponens a rendszer szintű eseményekre (broadcast) reagál. Például: kikapcsolt a képernyő, alacsony az akkumulátor töltöttsége, elkészült egy fotó, bejövő hívás, stb. Az alkalmazás is indíthat saját „broadcast”-ot, például ha jelezni akarja, hogy valamilyen művelettel végzett (pl. letöltődött a torrent). Nem rendelkeznek saját felülettel, inkább valamilyen figyelmeztetést írnak ki például a status bar-ra, vagy elindítanak egy másik komponenst (jeleznek például egy service-nek). Az android.content.BroadcastReceiver osztályból származik le; az esemény egy Intent (lásd. később) formájában érhető el.