
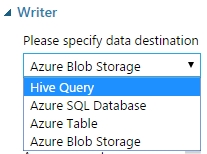
 Az aktuális adathalmazunkat, vagy eredményeinket, részeredményeinket (lényegében bármit) el tudunk menteni a Writer modul segítségével. A modul a Data Input and Output csoportosítás alatt található. A modul segítségével írható Hive Query, Azure SQL Databse, Azure Table és Azure BLOB Storage.
Az aktuális adathalmazunkat, vagy eredményeinket, részeredményeinket (lényegében bármit) el tudunk menteni a Writer modul segítségével. A modul a Data Input and Output csoportosítás alatt található. A modul segítségével írható Hive Query, Azure SQL Databse, Azure Table és Azure BLOB Storage.
Részletesebben csak az Azure SQL Databse használatát írom le, a többi hasonló terminológiát követ.
Writer modul – Azure SQL Databse
(Az Azure SQL adatbázis létrehozásával és beállításaival nem foglalkozok részletesen, de természetesen az is kell, ha oda akarok adatokat menteni 🙂 )
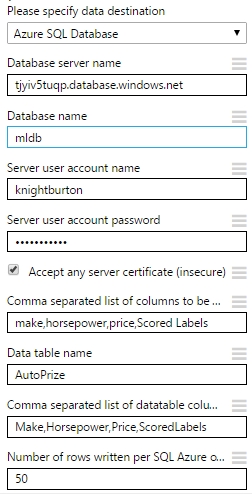
Miután a munkaterületre húztuk a Writer modult, a tulajdonságai között az első opciónál, Please specify data destination, meghatározhatjuk, hogy hova akarunk menteni, értelem szerűen választunk…(SQL…) 🙂 Ha kiválasztottuk a célt, akkor alatta megjelennek a további opciók.
- Database server name: Az Azure által megadott szerver azonosító, lehet csak a szervernév, vagy az egész azonosító egyben, akkor is működni fog.
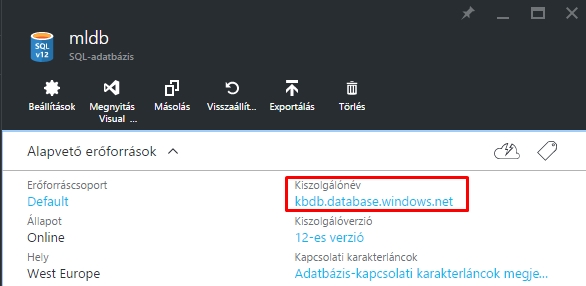
- Database name: egy a szerveren létező adatbázis neve szükséges ide.
- Server user account name: Az az felhasználónév, amit a szerver létrehozásakor megadtunk.
- Sevrer user account password: Az a jelszó amit a szerver létrehozásakor megadtunk,értelemszerűen.
- Accept any server certificate (insecure): Ezt akkor pipa ha nem akarunk több certificate-el találkozni.
- Comma-separated list of columns to be saved: Ahogy a neve is mutatja, azok az oszlopok kellenek ide vesszővel felsorolva, amiket a bemeneti adathalmazból vagy eredményhalmazból ki szeretnénk menteni.
- Data table name: Egy létező táblanév kell az adatbázisban, tehát nem a writer modul fogja létrehozni a táblát ahova majd az adatok kerülnek. Fontos, hogy ha a megadott tábla nem létezik akkor hibaüzenetbe fogunk ütközni, illetve ha a táblában megadott és a szolgáltatott oszlopok típusa nem egyezik akkor is hibaüzenet fogad majd minket. Tehát a modul csak egy INSERT utasítást hajt végre a megadott táblán.
- Comma-separated list of datatable columns query: Egy vesszővel elválasztott lista kell ide, amiben megadhatunk a kiválasztott oszlopokhoz alias neveket. Használhatjuk ugyanazokat a neveket amiket az adat vagy eredményhalmazból kapunk, vagy akár teljesen újakat is kreálhatunk. A kikötés csak annyi, hogy a dolognak követni kell az SQL szabályait.
- Number of rows written per SQL Azure operation: Egy egész szám megadása szükséges, amely behatárolja, hogy egy művelet egyszerre hány sort szúrhat be a táblába. Érdemes ezt a számot jól átgondolni, mert ha a beszúrandó sorok igen nagyok,és ez a limit is egy nagy szám akkor számolni kell az esetleges többlet idővel.
Fontos azt is megjegyezni, hogy ha be van állítva egy ilyen writer modullal az adatbázisba való mentés, akkor ha egy epxerimentet újra futtatunk, akkor minden futtatáskor az adott sorok beszúrásra kerülnek a táblába.
A példában egy egyszerű autó ár előrejelző kísérlet eredményhalmazából vágok ki adatokat amiket majd tárolok a táblában. Az eredmény így néz ki (nem teljes a kép):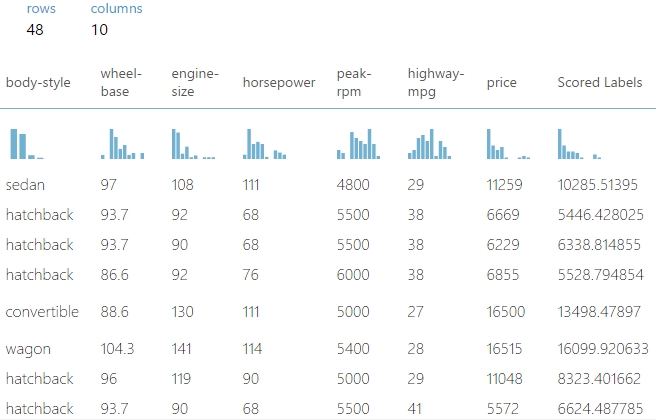
Amikor az SQL táblát létrehozzuk, már tudnunk kell, hogy milyen adatokat szeretnénk tárolni ott. Felmerül a kérdés, hogy a Táblában létrehozott típusok egyezni fognak-e azzal amit kapni fog a wirter modul. Alapvetően elég jól nyomon követhető, hogy az egyes oszlopoknak mi a típusa, esetleg mire konvertálódik át a kísérlet során, azonban ha az egyes oszlopok típusai nem felelnek meg a táblában létrehozott típusoknak, két opció áll rendelkezésünkre.
- Ha még nincs egyetlen adat sem tárolva a táblában, és a későbbiekben nem fog változni a kísérletben szereplő típus, akkor célszerűbb a táblázat oszlopán változtatni.
- Ha a tábla módosítása bármilyen okból nem megoldható, akkor sincs semmi gond, a Studióban ott van megoldásnak a Metadata Editor modul, segítségével elég sok konverziót végre tudunk hajtani. Ennek segítségével biztosak lehetünk abban, hogy a writer modulnak szolgáltatott adatok biztosan a táblának megfelelő típusban vannak.
A példában most ki akarom menteni mondjuk az eredmény halmazból a make(string), horsepower(integer), price(integer) és a Scored label(double) oszlopokat az SQL táblába. Ezeknek megfelelően hozok létre egy táblát a létező (mldb) adatbázisban.
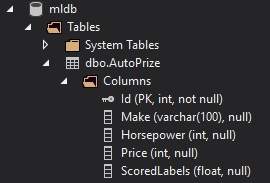
Miután a tábla készen van , és minden tulajdonságot beállítottam a writer modulban, amit megkap a modul a bemenetre, kiválogatja belőle a megadott oszlopokat, majd fogja és insert a táblába.
Ha minden jól működik, akkor miután futtatjuk a kísérletet, minden modul, beleértve a Writer modult is, ki lesz pipálva, hogy szépen lefutott, és akkor meg kell legyenek az adataink az adatbázis táblában.
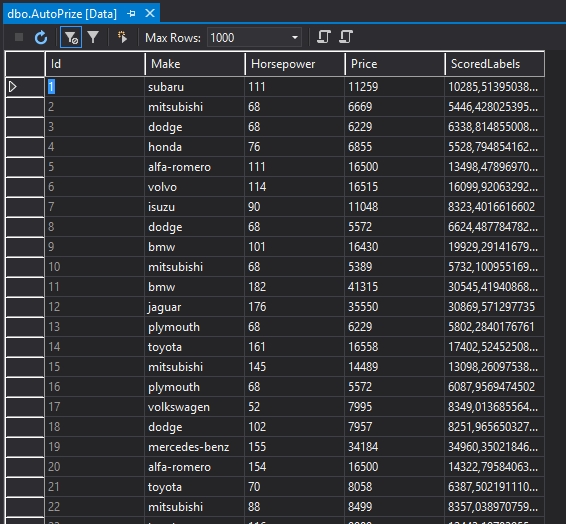
Látszik is a táblázatban (egyébként az adatbázist azt a Visual Studióban piszkálom, ahogyan azt az Azure Portál javasolta is 🙂 ), hogy jól működik az eddig elképzelt dolog.
Ha bizonytalanok vagyunk az adott oszlop típusát illetően, vagy csak biztosra szeretnénk menni (bár elég jól működik a dolog automatikusan is, hiszen már az adatok importálásakor ki kellene szűrődni az ilyen jellegű dolgoknak, de ha ott nem akkor majd a feldolgozásnál), akkor elővesszük a már korábbról ismert Metadata Editor modult. A modul amit inputként megkap, ugyanazt adja vissza outputban is, persze a kijelölt módosításokat végrehajtva. A modul beállítása, és tulajdonságai módosíthatóak miután behúztuk a munkaterületre, illetve adtunk neki valamilyen inputot.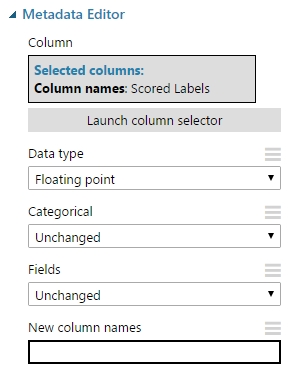
- Launch column selector: a már jól ismert eljárás szerint ki tudjuk választani a módosításra szánt oszlopo(ka)t.
- Data type: itt jelölhetjük ki, hogy milyen adattípusról is lenne szó.
- Categorical: ezt akkor használjuk, ha az adott értéket kategorikus változóként kell kezelni. A tényleges érték nem változik meg, csak az ml algoritmusok kezelik máshogy az adatokat.
- Fields: itt kijelölhetjük az érték “használatának módját”, hogy az aktuális érték az labelként, feature-ként, stb. legyen kezelve a továbbiakban. Például, ha azt akarjuk hogy a továbbiakban (amennyiben felhasználjuk még az adatokat a becslés számításában) nem akarjuk, hogy az érték részt vegyen a becslésben, akkor állítsuk label-re a field opciót.
- New column names: átnevezhetjük a kijelölt oszlopo(ka)t, ha több oszlop van akkor vesszővel tagolt listát kell megadni.
Miután megvannak, hogy melyik oszlopokat szeretnénk kimenteni a Writer modul segítségével, felmerülhet olyan igény is, hogy azokat soronként tovább szűrjük, azaz a teljes adathalmaz vagy eredményhalmaz akár egy igen szűk keresztmetszetét tároljuk csak el. Ezen kritériumok megvalósítására találhatunk eszközöket a Data Transformation menüpont alatt. Én csak kettő, modullal szeretnék most foglalkozni (más bejegyzésekben és későbbi bejegyzésekben lesz szó még az adatok transzformálásáról, manipulálásáról). Az első ilyen modul az szinte mindenkinek egyértelmű, az Apply SQL Tranformation modul. Lényegében SQLite utasításokat tudunk végrehajtatni a modul segítségével a kapott inputokon (három tábla köthető a bemenetre), itt lényegében csak az SQLite szintaxis szab határt annak, hogy mit akarunk csinálni. 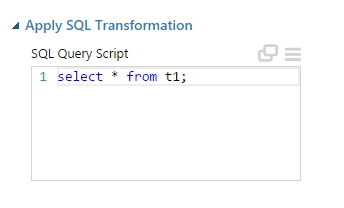
Arra azért vigyázzunk, hogy azokat az oszlopokat tartsuk meg a transzformáció alkalmazása után amelyeket majd a táblában akarunk tárolni. Mivel ezt még értelemszerűen a Writer modul előtt használom, teljesen hozzáférek az adathalmaz minden oszlopához. A példa szemléltetése végett csak azokat sorokat fogom a legvégén tárolni az SQL táblában, amelyeknél az autó body-style(amit Metadata Editorral cseréltem style-ra) sedan, az engine-size(amit Metadata Editorral cseréltem style-ra) az nagyobb mint az átlag és a horsepower az legalább 100. (Azaz a már megszokott módon tudunk bármilyen bonyolultságú lekérdezést végrehajtani.) Ennek az eredménye már csak 8 sort ad vissza, és csak ez a nyolc sor fog bekerülni az adatbázis táblába.
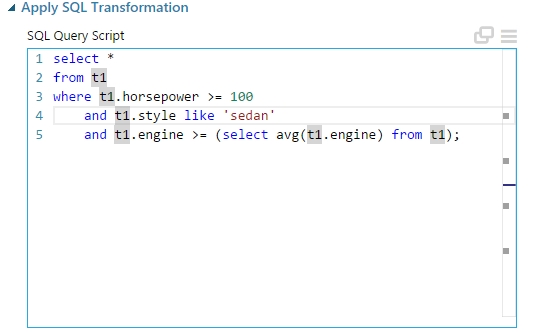
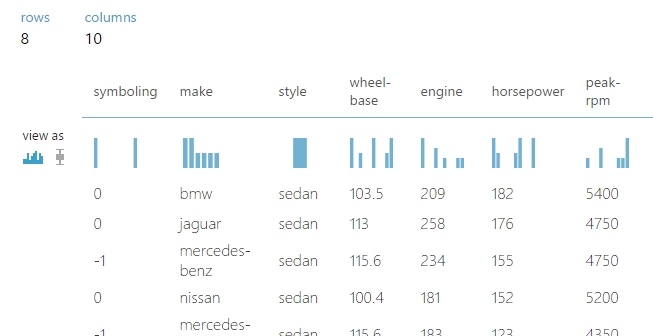
Ellenőrzésnek a Visual Studióban megnyitottam a táblát és csak ez a nyolc sort került be, természetesen csak a kiválasztott 4 oszloppal, tehát ez az első módja annak, hogy manuálisan meghatározzuk, hogy melyik keresztmetszet kerüljön tárolásra. (Az Id ne zavarjon meg senkit, auto increment és az előző futtatások sorait már töröltem, ténylegesen csak ez a nyolc sor van a táblában!)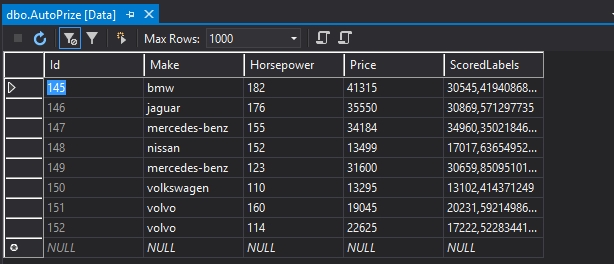
A másik opció lehet az adatok sorainak szűrésére ha mondjuk nem kimondott értékek alapján akarunk kimenteni adatokat, hanem csak egy bizonyos százalékát, egy bizonyos sormennyiséget vagy hasonló elgondolások. Ezekre IS lehet használni a Sample and Split almenüben található modulokat, megadott paraméterek alapján különböző részekre osztható az adat vagy eredményhalmaz az értékek vizsgálata nélkül is. Ezeknek a moduloknak a működéséről és használatáról részletes leírást találunk kollégám bejegyzésében!!!!
Tehát lényegében, bármilyen modult felhasználhatunk itt is ahhoz, hogy a Writer modulnak megszabjuk mi legyen a bemenetele, azaz mi kerüljön bele az adatbázis táblába.
Dinamikus paraméterezés
Továbbá, felmerült annak a kérdése is, hogy bizonyos értékeket lehet-e futás közben valójában random módon módosítani, valamilyen visszacsatolás vagy paraméter segítségével. A helyzet az hogy igen és nem. A legtöbb tulajdonság az egyes moduloknál módosítható a felhasználó által programban is vagy közvetlenül, azonban vannak olyan értékek amelyek egyszer rögzítésre kerülnek és vége. Azok az értékek amelyek a modell felépítésében, a képzésben vesznek részt, kívülről nem módosíthatóak, mert pontosan azért építi fel a modellt, hogy később azt használva tudjon becsléseket hozni. Tehát az egy fix pont. A modulok egyes random sedd, és randomizációs opcióin kívül valamelyest nagyobb hatókört biztosít számunkra ha írunk saját R scriptet az adott problémára, ugyanakkor az a későbbiekben ugyanúgy beolvasztásra kerül a modell kiképző részében ha ott használjuk, tehát ismét csak nem módosítható “külsőleg” néhány paraméter. Minden más paraméter ami “körülveszi” a kiképző részt, nagy valószínűséggel módosítható dinamikusan. Legyen szó adatmanipulációról, értékelésről, pontozásról, stb. Ennek a megvalósítására találták ki a Web Service Parameters megoldást. ha van olyan paraméter egy modulban, amit dinamikusan egy programban, vagy a felhasználó által akarunk vezérelni, akkor azt be tudjuk állítani globális web service paraméterként. A legtöbb esetben ezt arra használjuk, amikor a Reader vagy Writer modulokat használjuk, azaz futásidőben tudjuk megmondani, hogy a Reader modul milyen forrásból olvasson, vagy a Writer modul hova írjon.
Egy adott paraméter gy állítható be Web Service Paraméterként, hogy a paraméter jobb felső sarkában található 3 vízszintes vonalra kattintunk, majd a Set as web service parameter lehetőségre kattintunk.
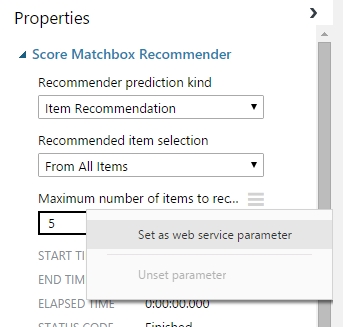
A példához a korábban létrehozott film ajánló kísérletet fejlesztettem tovább, ahol majd programból vagy userként adhatjuk meg, hogy hány darab itemet (azaz most filmet) akarunk megkapni az ajánlásban.
Miután kiválasztottuk az opciót, a paraméter be lesz álítva mint egy wsp. Így globálisan fog megjelenni ez az információ a munkaterület property menüsávjában, azaz szinte mindenhol ahova kattintunk, legyen az modul, látszani fog, hogy mik a web service paraméterek. Legegyszerűbb ha a munkaterület egy üres területére kattintunk, és bal oldalt láthatjuk a paramétereket. Ha meg akarjuk változtatni a paraméter nevét, akkor csak kattintunk rá a címére és írjuk át tetszőlegesre. Ha ismételten a jobb felső sarkában lévő 3 vízszintes vonalra kattintunk akkor lehetőségünk van törölni, illetve alapértelmezett értéket adni a paraméternek.
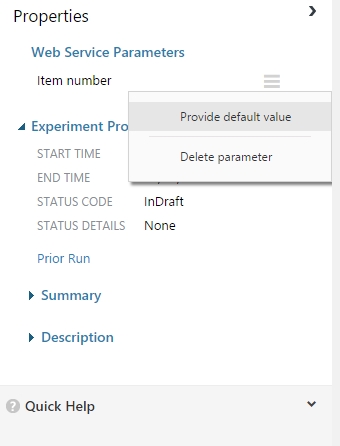

Ha ezeket a paramétereket beállítottuk, akkor minden mehet tovább a régi kerékvágásban, azaz futtatjuk a kísérletet (ezért kell beállítani egy alapértelmezett értéket a paramétereknek, hogy a futtatáskor kapjon valami inputot, amit egyébként meg is kap ha nem tesszük ki azt web service paraméternek), majd web service-t csinálunk belőle és publikáljuk. Miután publikáltuk a web servicünket, az ismert módon tesztelhetjük azt (Excel, Website, C#, R, Studio), ahol már a paraméter értékét is meg kell adni bemeneti paraméternek.
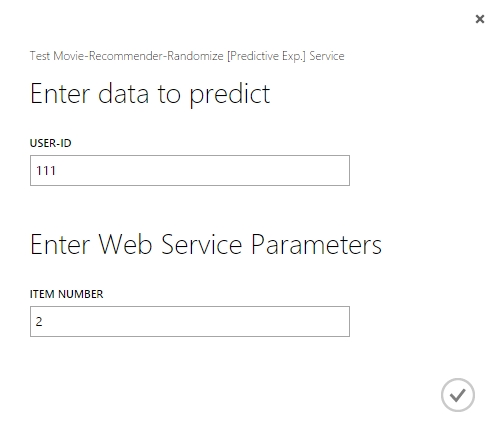
Majd látható, hogy a dolog jól működik, mert csak 2db film azonosítót ad vissza a web service.

Így ezek a paraméterek a kódban ami a háttérben működik Globális paraméterként szerepelnek. Ennek a részleteit ugyanúgy láthatjuk ha a Web Service-nél az API oldalnál megnézzük a Request/Response vagy Batch execution linkeket.

Péládul a request/Respone oldalon a C# kódban látható használata:
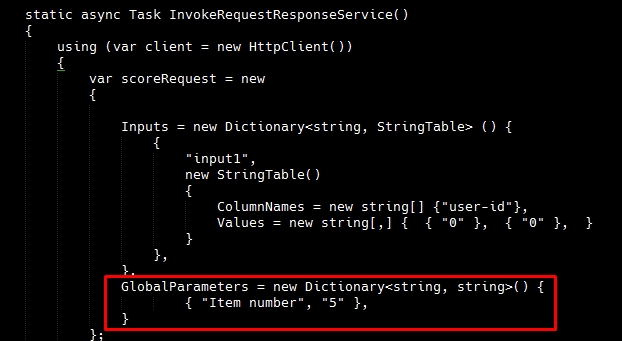
Tehát, ugyanezen terminológia alapján állítható be rengeteg opció a modulok tulajdonságai közül web service paraméterként. Legyen szó a fent látható item számának meghatározásáról, egy SQLite parancsról, a Split Data modul százalékos elosztásának meghatározásáról vagy egy random szám meghatározásáról, a lényeg csak annyi, hogy ami közvetlen a Trained Dataset kialakításához szükséges az később nem módosítható futás közben, mert a kiképzett adathalmazt használja az aktuális becslés megállapítására. (Vagyis jelenlegi tudásom szerint ez a helyzet, ha változik, akkor megy az update! 🙂 )