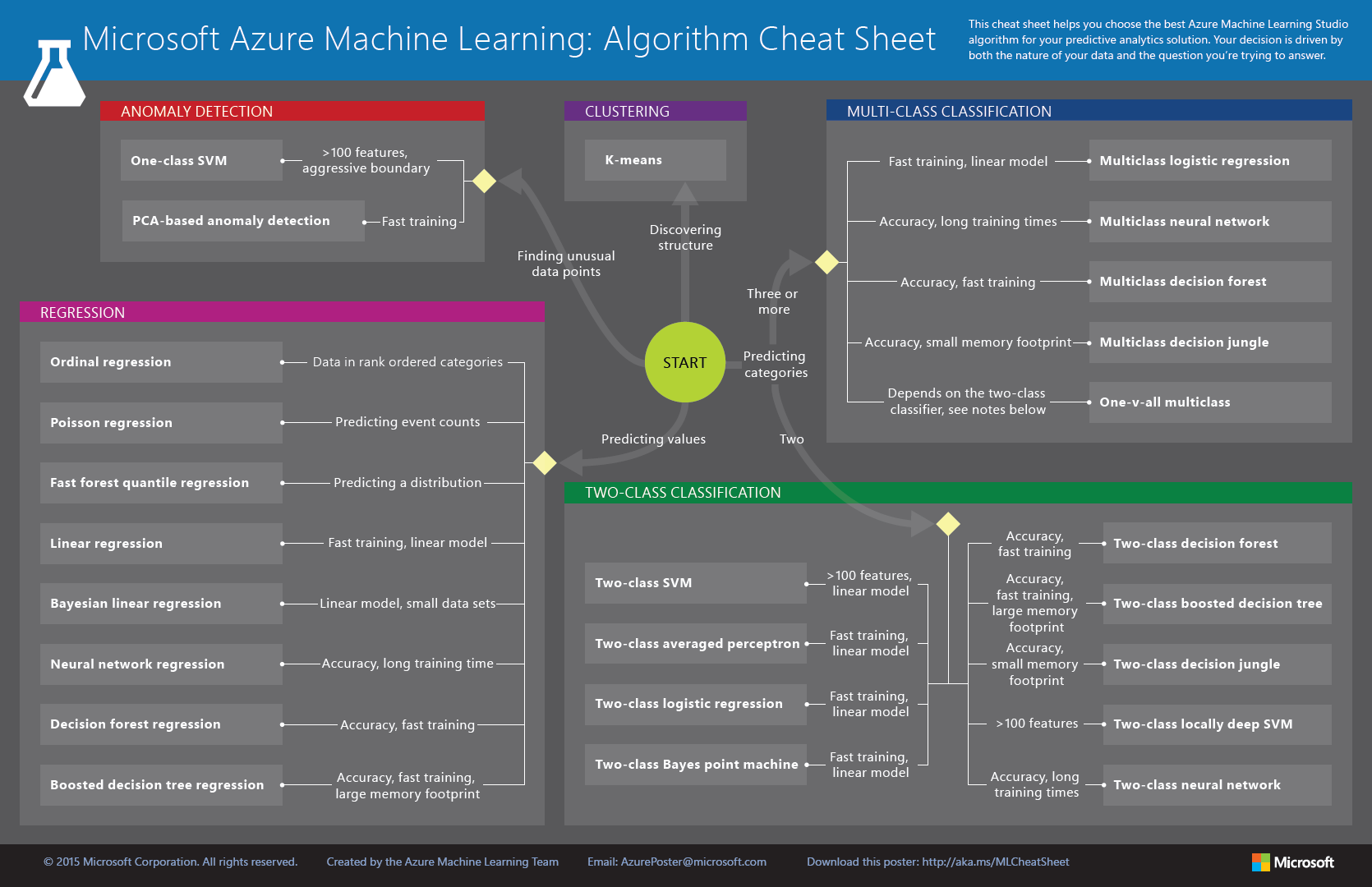
Rengeteg algoritmus megtalálható a Studioban, így sokszor az adhatja a legnagyobb fejtörést, hogy melyiket válasszuk ezek közül.
Rengeteg algoritmus megtalálható a Studioban, így sokszor az adhatja a legnagyobb fejtörést, hogy melyiket válasszuk ezek közül.
Először azt kell kitalálni, hogy milyen típusú a problémánk, majd azon belül kell választani egy megfelelő algoritmust.
Megpróbálok egy kicsit segíteni a választásban az alábbi leírással:
Regresszió:
Egy számértékre vagyunk kíváncsiak, amit kiszámol az algoritmus, mint egy függvény. Meghatározza minden oszlop szerepét a „képletben”, és ez által fogja megadni az értéket.
Linear regression:
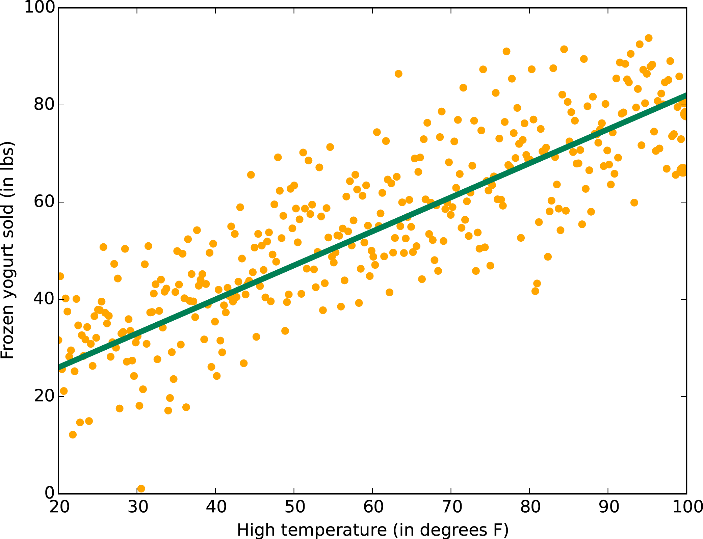
A legegyszerűbb regressziós modell, lineáris kapcsolatot feltételez. Ezáltan gyors lesz, ám ha a valóságban nem lehet jól közelíteni lineárisan a függvényünket (ami elég gyakran előfordul), akkor igen gyenge eredményeket kapunk.
Választhatunk a legkisebb négyzetek és a gradiens módszer között, utóbbinál megadhatóak a paraméterek intervallumként. Kis adathalmaznál érdemesebb a legkisebb négyzetes módszert választani.
Boosted decision tree regression:
Több döntési fát is felépít, majd kiválasztja közülük a legjobbat. Akkor igazán hasznos, ha az adathalmazunkban az oszlopok összefüggenek. Sok memóriát használ fel, ezt figyelembe kell venni.
Decision forest regression:
Több döntési fát alkalmaz, majd ezek kimenetét összesíti, és ez alapján hozza meg a végső döntést. Megadhatjuk, hogy ugyan azon az adathalmazon tanuljon az összes fa, vagy pedig ugyan olyan eloszlású, ám különböző adatokon menjenek végig.
Poisson regression:
Amennyiben Poisson eloszlású változót szeretnénk becsülni, ez lesz a megfelelő modul.
Ez leginkább valaminek a számolásáról szól, például, hogy hányan adják be a dolgozatukat a tétel címének elolvasása után. Ebből adódik természetesen, hogy pozitív egésznek kell, hogy legyen az érték.
Fixen, és intervallumokkal is paraméterezhetjük, utóbbinál a Sweep Parameters modul fogja kiválasztani a legjobb paramétereket a megadott listából.
Neural network regression:
Amikor a klasszikus regressziós módszerek nem tudnak megfelelő pontosságú jóslást adni, érdemes lehet megpróbálni ezt az algoritmust. A neurális hálók elég robusztusak, ám jó eredményeket képesek elérni.
Intervallumosan is megadhatjuk a paramétereit, továbbá akár saját magunk is meghatározhatjuk a hálózat kapcsolódását a Net# nyelv segítségével.
Fast forest quantile regression:
Ez a modul nem a tényleges értéket, hanem az osztópontokat adja meg, amikkel az eloszlást vizsgálhatjuk. Szintén használhatunk intervallumokat is a paraméterek megadásánál.
Bayesian linear regression:
Lineáris regressziót használ kiegészítve azzal, hogy Bayes statisztikát feltételez.
Leginkább kis adathalmazoknál használjuk.
Ordinal regression:
Sorrendiséget keres, például egy versenyen a résztvevők sorrendjét.
Ennek a modulnak nincsen paramétere, mindössze egy tetszőleges (tanítatlan) bináris osztályozó algoritmust kell bekötni a bemenetébe.
Bináris osztályozás:
Olyan speciális osztályozás, ahol kétfelé kell bontani az adatokat: spam / nem spam, megfelelt / megbukott…
Two-class SVM:
A tanító adatokat pontokként lehet elképzelni egy síkon, ahol egy maximális vastagságú vonal választja el a két csoportot egymástól. Inkább a gyorsaságra megy, minthogy a pontosságra.
Two-class averaged perceptron:
Egy leegyszerűsített, „korai verziójú” neurális háló. A legnagyobb előnye, hogy kifejezetten gyorsan tanul, és mivel sorosan dolgozza fel az adatokat, így folytonos tanulásra is használható
Two-class logistic regression:
Kiszámolja a valószínűségét, hogy az egyik csoportba esik az elem, majd eszerint dönt, hogy hova sorolja. Elég gyors algoritmus, és igen elterjedt is.
Two-class Bayes point machine:
Egy lineáris modell, ami Bayes pontot keres. Minél inkább korreláltak az adataink, annál több iterációra van szüksége az algoritmusnak.
Two-class boosted decision tree:
Rendkívül nagy memóriaigényű, így megeshet, hogy néhány nagy adathalmazt nem tud kezelni, amit lineáris társai igen, azonban általánosságban jó eredményeket ér el sokféle feladaton.
Fontos, hogy nagyságrendekkel több példánk legyen, mint tulajdonságunk, mert hajlamos a túltanulásra.
Two-class decision forest:
Döntési erdőt hoz létre, aminek előnye, hogy nem térítik el a zajos tulajdonságok, és képes nem-lineárisan dönteni. Képes kevés adaton is elég jó hatásfokot elérni, ha sok fát kérünk.
Two-class decision jungle:
A döntési erdők továbbfejlesztése, ahhoz képest kevesebb memóriát fogyaszt, azonban tovább tart a tanítása. Fák helyett irányított körmentes gráfokat használ.
Two-class locally deep SVM:
Ez az implementáció akkor hasznos, ha a lineáris bináris osztályozó algoritmusok nem adnak jó eredményt az adatunka, vagy esetleg találtunk egy jó algoritmust, de az nem volt elég gyors.
Two-class neural network:
Az emberi agy ihlette megoldás. Rengeteg összekapcsolt rétegből áll, amiben neuronok vannak.
A leginkább pontos, és egyben leginkább lassú algoritmus, így akkor érdemes használni, ha van időnk kivárni az eredményt, és szükséges is a nagy pontosság.
Osztályozás több csoportba:
3, vagy több csoportba soroljuk az egyes elemeket. Akár több bináris osztályozót is használhatunk, ha megfelelően kötjük őket össze.
Multiclass logistic regression:
Olyan, mint a bináris társa, szintén valószínűségeket számol. Relatíve gyorsan tanul.
Ne tévesszen meg a neve, ez is osztályozó algoritmus!
Multiclass neural network:
A neurális háló erre a feladatra is megfelelő, képes akár egy láthatatlan réteggel is pontos eredményt adni. Minden neuron kiszámolja a kimenetét, majd továbbadja azt a következő réteg számára. Igen bonyolult szerkezetek alakulhatnak így ki. Amennyiben a pontosság az első, mindenképpen érdemes ezt választani.
Multiclass decision forest:
Annak ellenére, hogy nem lineáris, képes elég gyorsan tanulni. Ha erre van szükség, csak kevesebb fát (5-10) és kevesebb véletlen vágást (<100) kell beállítani rajta.
Multiclass decision jungle:
Igen hasonló a bináris változatához, csak itt ugye több csoportba sorolhat. Nem lineáris döntési határokat készít.
One-v-all multiclass:
Egy bináris osztályozó algoritmusból csinál multiclass osztályozó algoritmust úgy, hogy minden osztálynak felépít egy modellt, ahol az osztályt szembe állítja a komplementerével. Tetszőleg Two-class algoritmust megadhatunk bementként, további paraméterek megadására nincs szükség.
Klaszterizálás:
Felügyelet nélküli tanulás, hasonló az osztályozáshoz, csak itt nincsenek tanítópéldáink a klaszterekre (osztályokra). Az adat rejtett szerkezetét fedi fel ez a módszer. Iteratív módon (nulláról indulva folyamatosan hozzáadva, vagy a teljes halmazból indulva folyamatosan kivonva) állítja össze a klasztereket.
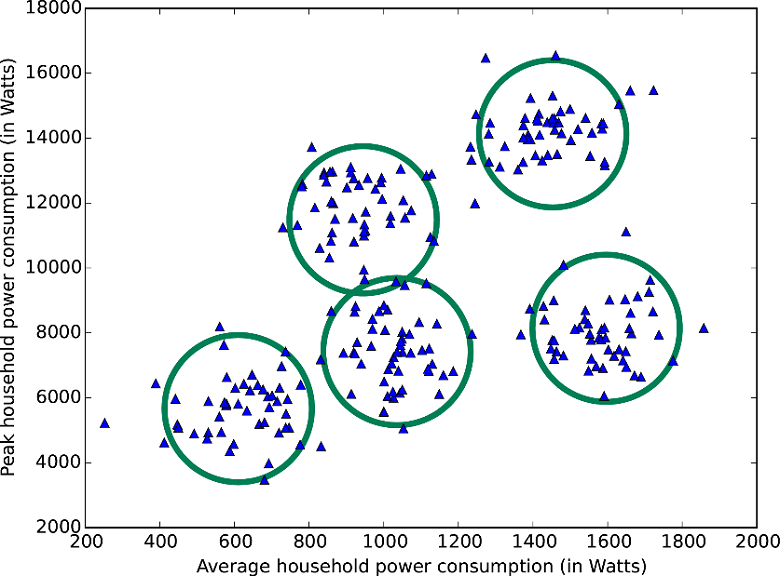
K-means:
Jelenleg ez az egyetlen elérhető klaszterizáló algoritmus, így ha ilyenre van szükség, nem kell sokat gondolkodni, hogy melyiket válasszuk. Megadhatjuk neki a kezdőpontok számát, ahonnan majd indul a klaszterizálás. Azonban az nem garantált, hogy a végén pont ennyi klaszter lesz.
Anomália felismerés:
Sokféle forgatókönyv elképzelhető, ahol bizonyos rendellenességeket kell felfedezni az adathalmazban: biztosítási csalás, bankkártya lopás… A tanító adatokban jellemzően igen kevés a pozitív elem (anomália), így ezek az algoritmusok a normális viselkedést tanulják meg, és jeleznek arra, ami szignifikánsan eltér attól.
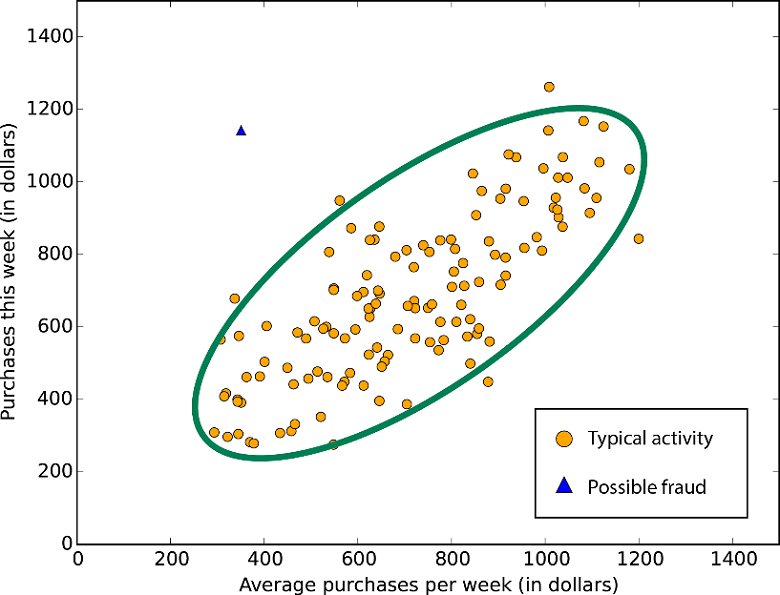
One-class SVM:
Ez a modul A Support Vector Machine modell segítségével ismeri fel az anomáliákat. Viszonylag sok időbe telik a tanulás, főleg nagy adathalmaznál, így ha ez szempont, akkor válasszuk inkább a PCA-t.
PCA-based anomaly detection:
Fő komponens analízist végez, amivel normalizált hibát számol. Minél nagyobb egy elem értéke, az annál inkább rendhagyó.
Továbbá a Microsoft készített egy gyors összefoglalót az algoritmusokról, ezen a linken letölthető a vektorgrafikus változata.