
Itt az ideje, hogy valós adatokon egy teljesen új kísérletet állítsunk össze, nem kimondottan a környezet, a rendszer vagy a lehetőségek megismerése céljából, hanem sokkal inkább az eddigi ismeretek felhasználva valami egészet alkotni. Kaptam egy adathalmazt amelyben x számú ember (mind férfi és nő) adatai szerepelnek olyan anyajegyekről amelyekről el kell dönteni, hogy nem problémás, gyanús vagy gondot okozó darab.
Az adathalmaz tartalmaz minden anyajegyről számos információt. A teljesség igénye nélkül néhány: RGB színkomponensek szerinti felbontás amely tartalmazza a kerületi szórást, a mag szórást, különböző eltéréseket szintén külső és belső jellemzőkre lebontva. Ugyanezek az információk Több színsémában megtalálhatók az adathalmazban. Továbbá textúra adatok is találhatóak, mint pl. entrópia, contrast, uniformitás, stb… (a lista tényleg nagy, és többnyire száraz is) és végül néhány általános adat magáról az adott betegről, akin megtalálható az adott anyajegy, pl. szem, hajszín, napozási szokás, összes anyajegy szám, stb.. és természetesen a kezdeti adathalmaz tartalmazza az osztályozást is.
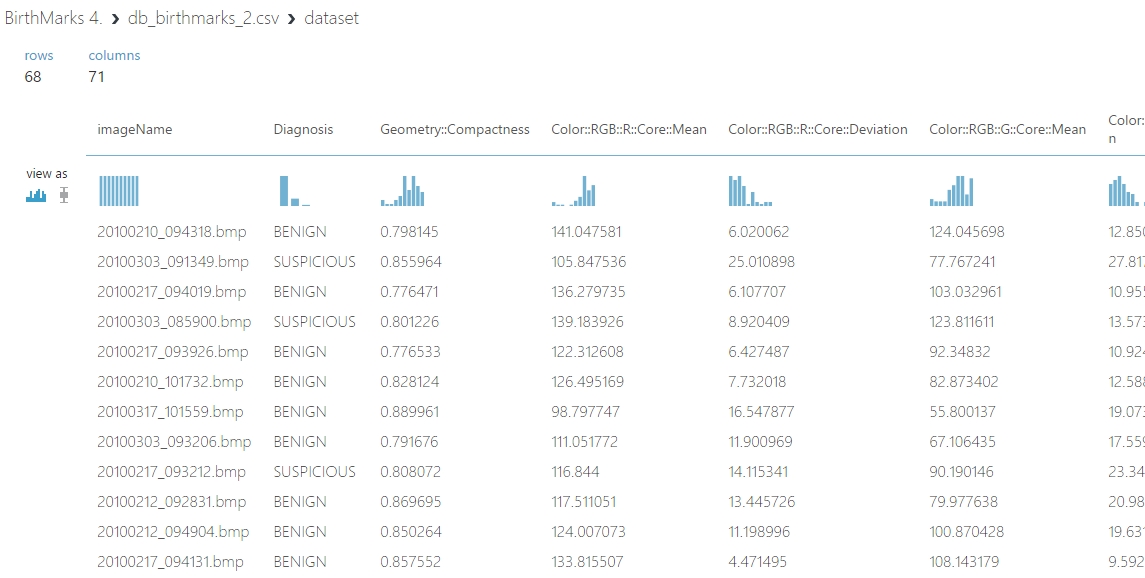
Az adatok módosítása
Amint a fenti képen látszik is jelenleg az adathalmaz minden manipulációtól mentesen 68 egyedi sorból 71 featureből áll és 3db osztálya van. Ezen némileg módosítani fogok.
Első nekifutásra a betegek vagy páciensek adatait átkonvertáltam kategórikus változókká, ugyanis alaphelyzetben ezek szöveges adatok voltak. Kategórikus változókkal némileg könnyebb lesz dolgozni a későbbiek folyamán. Ehhez a már ismert Metadata Editort kellett alkalmazni. Egyszerűen az adathalmaz kimenetét rákötöttem a ME modul bemenetére majd a Properties sávban a Launch column selector segítségével kiválasztottam a megfelelő adatokat amiket át szerettem volna alakítani.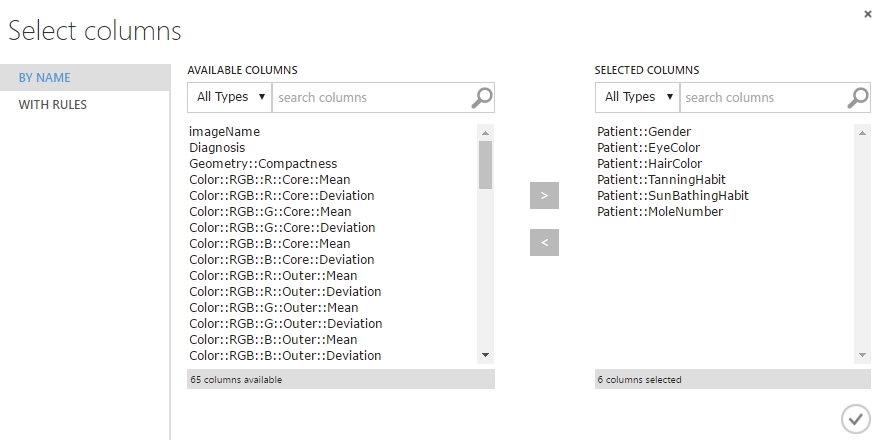
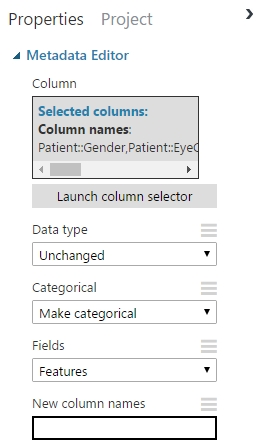
Majd megadtam, a Categorical opció alatt a Make categorical lehetőséget és kész is a beállítása a modulnak.
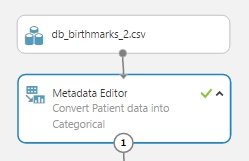
Majd a megfelelő módon bekötve valahogy ilyen egyszerűen kell kinézzen a 2 modul.
Ezek után a ME modul kimenetére rákötöttem egy új modult amellyel a frissen átalakított oszlopokat indikátor értékeké konvertáltam. Ezzel annyit értem el, hogy teljesen kiváltottam a szöveges adatokat lényegében true vagy false adatokra néhány plusz oszlop hozzáadásával. Ez a modul a Convert to indicator values module. Ennél is mint a ME modul esetében a Launch column selectorral kiválasztjuk, hogy mely adatokat akarjuk indikátorokká alakítani (ami jelen esetben ugyanazok mint az előbb is) és készen is vagyunk. A folyamat végén egy ilyen szerkezetet kaptam:
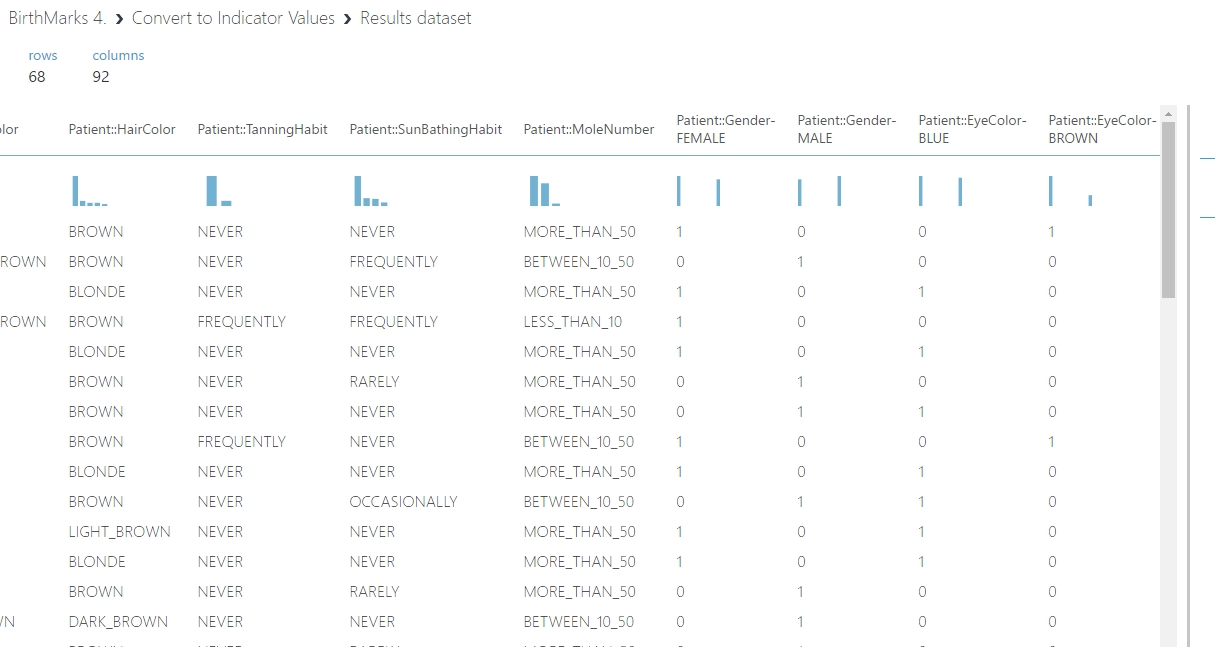
Ezek után az adathalmazom kissé megváltozott. Az egyedi sorok száma természetesen megmaradt 68-nak mivel ezeket nem bántottuk, azonban az oszlopaink száma 92-re emelkedett. Ebben még benne vannak az indikátor értékekhez felhasznált adatok is szöveges formában, és természetesen az adathalmaz végén már ott vannak az új indikátor értékek is.
Ahhoz hogy a szöveges adatok a páciensekről eltűnjenek, a legegyszerűbb módot választottam, a már ismert Project Column modult. (Ez opcionális, de ha nem kell a későbbiekben semmire az adat én jobbnak tartom kivenni, mert akkor véletlenül fogjuk azokat felhasználni valamely másik modul működésében.)
Az osztályok módosítása
Alapesetben az adathalmazban 3 osztály található, ezek a BENIGN, SUSPICIUS és a MALIGNANT soztályok. A BENIGN az az ártalmatlan anyajegyek címkéje, a SUSPICIUS a gyanús és a MALIGNANT a rosszindulatú anyajegyek címkéje. Az adathalmaz jelenleg rendkívül kevés adatot tartalmaz, mindössze ugye csak 68-at, melyből csupán 2db a rosszindulatú címkéjű és 13db a gyanús címkéjű.
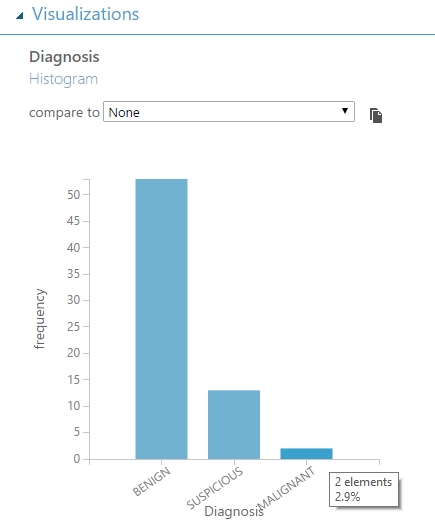
Mivel a való életben egy gyanúsnak ítélt anyajegyet is erősen ajánlott szakorvossal megvizsgáltatni, nem csak a rosszindulatút (a mi algoritmusunk alapján), így a két osztályt összevontam. Ezzel a csalással több osztályú problémából csináltam egy 2 osztályú problémát, és a negatív osztálycímkék arányát is javítottam. Erre több magyarázat is lehetséges: elsősorban kétosztályos problémákat könnyebb kezelni, több algoritmus áll a rendelkezésünkre és ha tovább tekintünk egy projekt életében, akkor azzal is érvelhetnék, hogy a felhasználókra kevesebb információ nehezedik a folyamat végén, továbbá a kevés adat miatt szükség volt és lesz mindenféle cselre ami javítja a tanulási arányt. (Természetesen ezt nem lehet bármilyen probléma esetén véghezvinni, csak ahol jól látszik, hogy ez nem jelent semmilyen hátrányt a valós problémában).
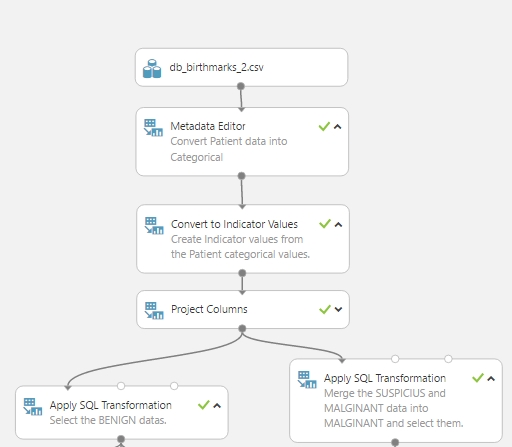
Ezt szintén egy egyszerű módon valósítottam meg, csupán 2 db Apply SQL Tranformation modult használtam fel. Az indikátor értékké alakító modul kimenetét bekötöttem a két darab SQL modul bemenetére. Az első SQl modulban egy egyszerű lekérdezéssel kigyűjtöttem azokat az adatokat, amelyek jóindulatúak azaz a BENINGN címkét viselik. A második SQL modulban pedig a gyanús címkéket lecseréltem rosszindulatóra, azaz a SUSPICIUS-t MALIGNANT-ra, majd ismét egy egyszerű lekérdezéssel kigyűjtöttem a rosszindulatú, azaz a MALIGNANT címkéjű adatokat.
(Az ártalmatlan, jóindulatúak kigyűjtésére szolgáló SQL lekérdezés)
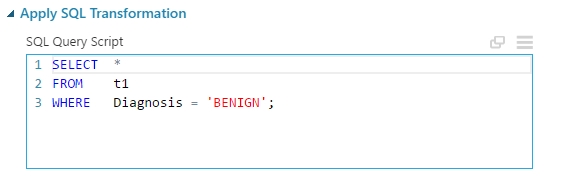
(A gyanús adatok rosszindulatúra “konvertálása” és lekérdezése)
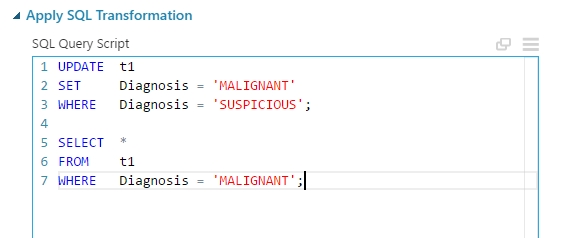
A két SQL modul bekötve az eddig megvalósított rendszerbe a következőképpen néz ki (megjegyzés: azért tettem kettő külön SQL-modult, hogy a két osztály adatait külön-külön adathalmazban tudjam a későbbiekben kezelni):
Összefoglalva a dolgokat:
- Felhasználtam egy valós egyedi adathalmazt
- Az adathalmazban a páciensek adatait kategórikus adatokká alakítottam
- A páciensek adatait indikátor értékekké alakítottam
- A három osztályból készítettem egy kétosztályos problémát, és az adathalmazt ezek mentén szétszedtem