
Ahogy már korábban is írtam, létezik felügyelt, és felügyelet nélküli tanulás is. Most a másodikkal fogok foglalkozni.
A klaszterezés lényege, hogy az egyes egyedeket csoportokba osztja.
Fontos különbség az osztályozással szemben, hogy itt az adat belső struktúrájának a felfedése a lényeg, és nem pedig az egyes elemek pozíciója.
Tipikusan a klaszterizálásnál nincsenek meg a tanító adatbázisban az osztály címkék, hanem az algoritmus feladata megtalálni a valamilyen szempontból hasonló elemeket, és ezeket egy klaszter alá venni.
Gyakorlatilag egy dimenziócsökkentő eljárás, amivel az egyes dimenziók szerint megnézhetjük az elemek távolságát/hasonlóságát, és ez által összehasonlíthatjuk, majd klaszterekbe rendezhetjük őket.
Létezik több típusa is, mint például:
- Hierarchikus
- Centroid alapú
- Eloszlás alapú
- Sűrűség alapú
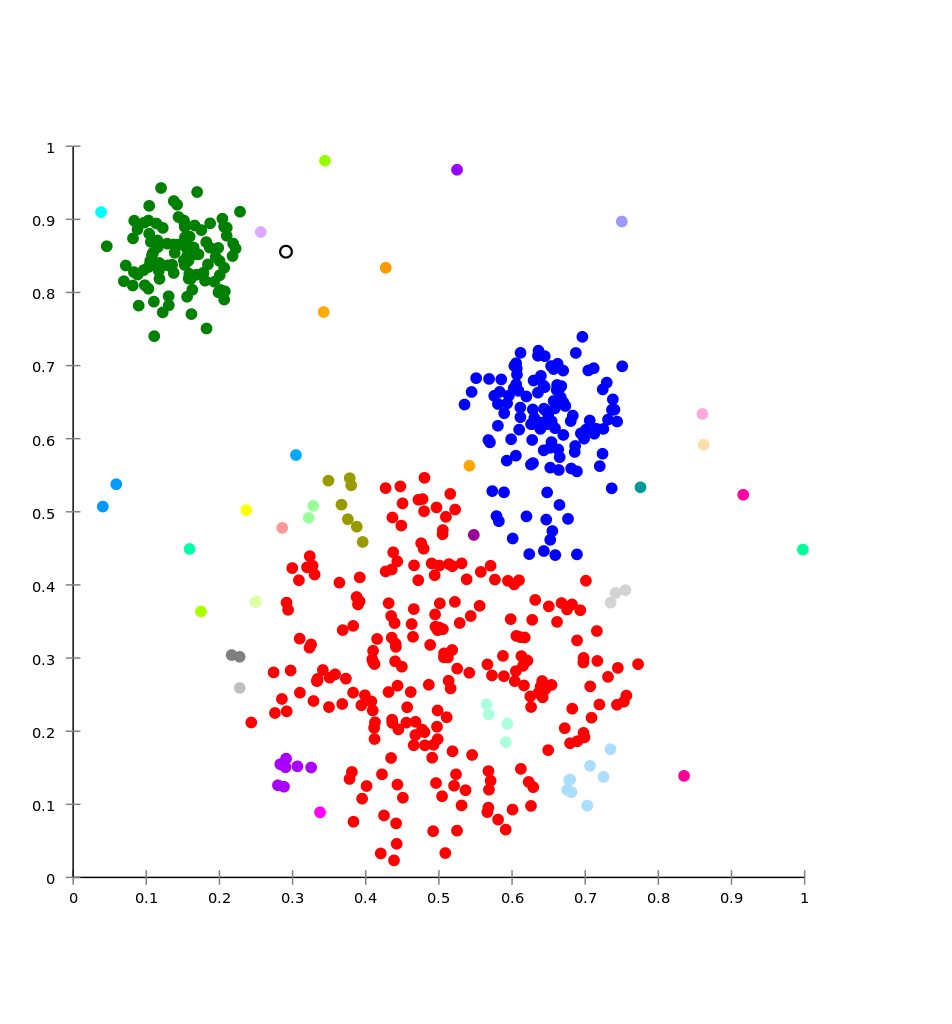
A hierarchikus lényege, hogy a távolság alapján sorolja az egyes klaszterekbe az elemeket. Teljesen logikus, hogy ha közelebb van egymáshoz két elem, akkor nagyobb valószínűséggel van közük egymáshoz, mintha messze lennének.
Lehet összevonó vagy felosztó, attól függően, hogy hogyan tekintünk az elemekre:
Az összevonóban kezdetben minden elem külön klaszter, majd az egymáshoz közel levő klasztereket összevonjuk, és mindezt addig folytatjuk, amíg elérjük a megfelelő klaszter mennyiséget.
Ezzel ellentétben a felosztó kezdetben egy klaszterrel kezd, és a legeltérőbb elemekből külön klasztert csinál – szintén addig, amíg elérjük a kívánt darabszámot.
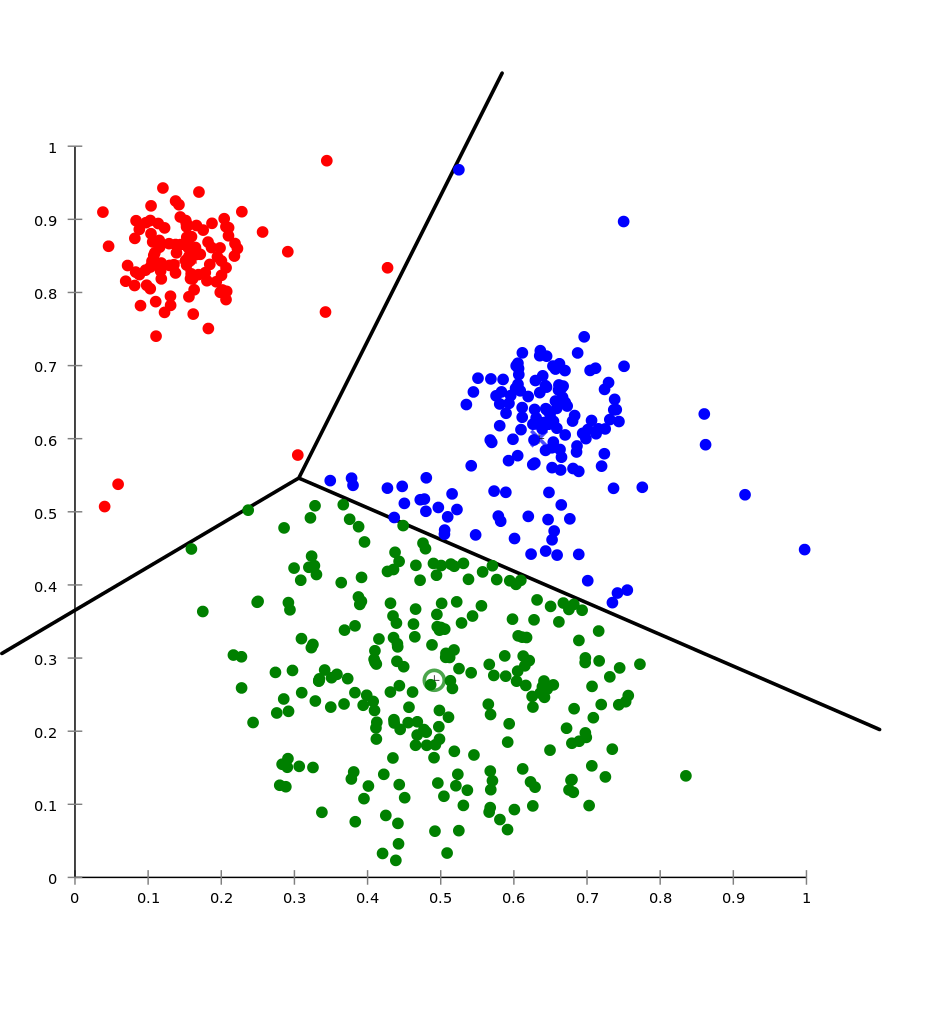
A centroid alapú ezzel szemben az egyes klaszterek középpontját próbálja meghatározni, majd meghúzni a vonalat, ami határolja őket egymástól. Ezzel egy optimalizálási problémát vet fel, hogy meg kell keresni a k darab középpontot, majd valamilyen stratégia alapján hozzárendelni a pontokat az egyes centroidokhoz.
A legnagyobb problémája az, hogy előre szükséges a klaszterek száma, ami azonban nem mindig triviális.
A legelterjettebb ezek közül a k-means, ez megtalálható az Azure ML Studio-ban is, a következő posztban erről bővebben fogok beszélni.
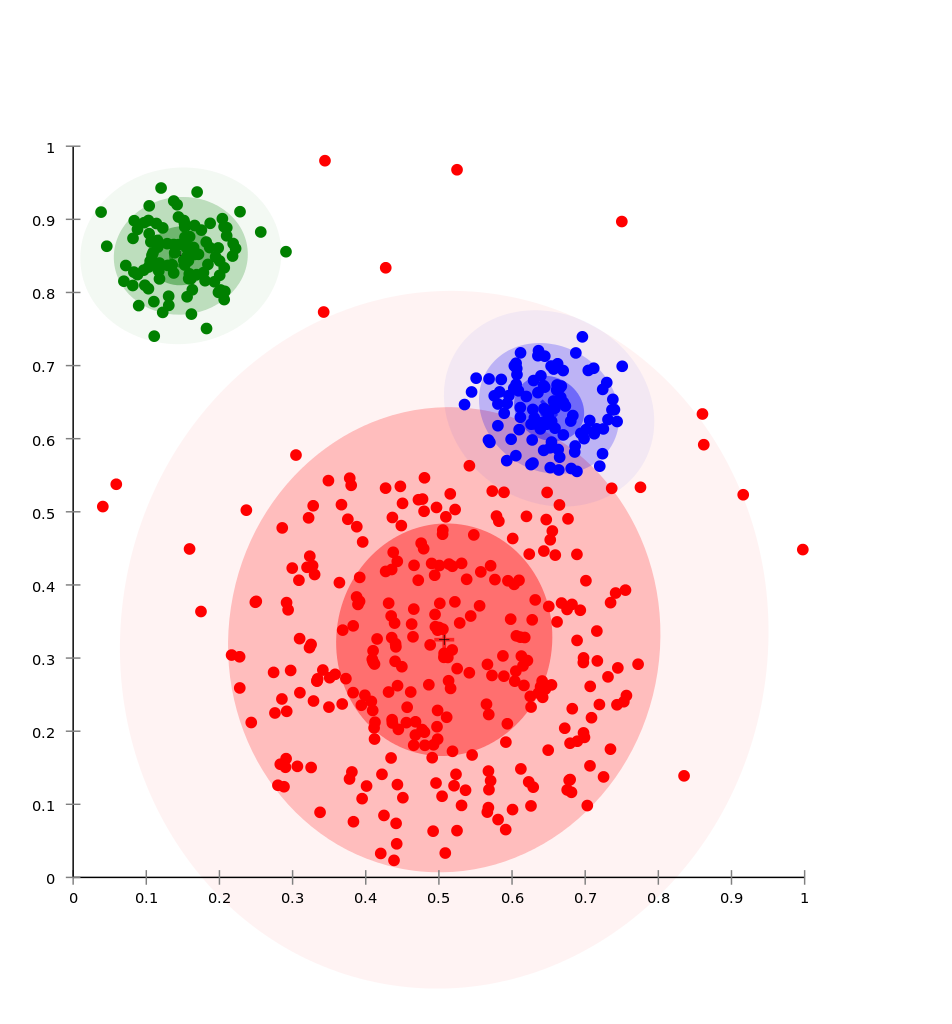
Az eloszlás alapú a statisztikai eloszlásokra épít, ezáltal jól tudja reprezentálni a különféle eloszlású csoportokat. A nagy hátránya, hogy könnyen beleesik a “túltanulás” hibájába, és így hamis eredményt nyújt. Nagyobb odafigyeléssel a megfelelő helyen alkalmazva azonban rendkívül hasznos.
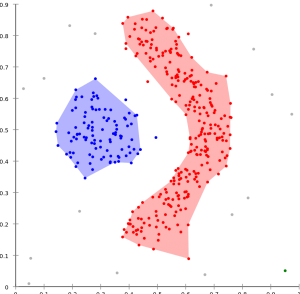 A sűrűség alapú az elemek sűrűségét veszi figyelembe, és ez alapján alakítja ki a csoportokat – a nagy sűrűségű részek klaszterek lesznek, a közöttük levő alacsony sűrűságű rész lesz a határ, a zaj. Természetesen innen látszik, hogy ez a fajta algoritmus azt feltételezi, hogy jól szeparáltak a klaszterek határai.
A sűrűség alapú az elemek sűrűségét veszi figyelembe, és ez alapján alakítja ki a csoportokat – a nagy sűrűségű részek klaszterek lesznek, a közöttük levő alacsony sűrűságű rész lesz a határ, a zaj. Természetesen innen látszik, hogy ez a fajta algoritmus azt feltételezi, hogy jól szeparáltak a klaszterek határai.
Egyes klaszterező eljárások lehetnek “erősek”, vagy “gyengék”. Ez azt jelenti, hogy az erős esetében az egyed vagy hozzátartozik egy klaszterhez, vagy nem, amíg a gyengénél egy számérték jelzi (a valószínűség), hogy melyik klaszterhez mennyire tartozik hozzá.
Akár olyan is előfordulhat, hogy egy elem semelyik klaszterhez nem tartozik (kívülálló).
Általánosságban azt mondhatjuk, hogy a klaszterezés akkor sikeres, ha fel tudtunk fedezni egy új struktúrát az adathalmazban (vagy beigazoltunk egy sejtést), hiszen ekkor sikerült találnunk egy rendszert az adatunkban.
A klaszterezést alkalmazzuk az informatikában például képfeldolgozásban szegmentálásra, élfelismerésre, illetve egyes ajánlómotorok is ilyen technikát alkalmaznak.
Marketingben piac szegmentálásra, vagy az új termék pozícionálására használják.
De talán az egyik legjobb példa a közzöségi portálokon a közösségi háló feltérképezése, és klaszterezéssel csoportokra bontása, ezáltal tud például a Facebook ismerőst ajánlani (aki egy klaszterben van a felhasználóval, valószínűleg kapcsolatban van vele valamilyen szinten).