
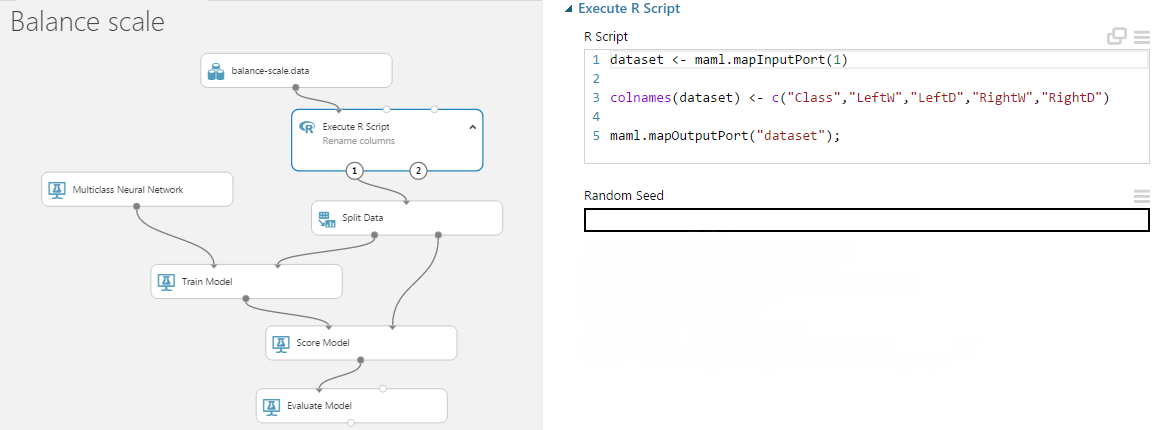
Ha már felépítettük a kísérletet, minden rendben van, akkor ideje kinyerni belőle a hasznos adatot amiért végül is dolgoztunk. Átfutunk gyorsan és egyszerűen egy recommender system dolgon. Mint már korábban említettem valamikor, van elég sok olyan alkalmazása a gépi tanulásnak, hogy például a vásárlásaid alapján, vagy tervezett vásárlásaid alapján (i mean wishlist) a rendszer kidobálja, hogy más vásárolók miket vettek meg, vagy néztek még meg, és nagy valószínűséggel az neked is tetszene (erősen próbálnak rávenni arra, hogy termeld szépen a profitot nekik 😀 ).
Model results
Reply
 A Normalize Data modul segítségével az adatainkat azonos volumenűre hozhatjuk. Erre akkor van szükség, ha nagyságrendbeli különbségek vannak köztük. A kisebb skálájú adatokat kevésbé veszik fontosnak az algoritmusok, hiszen ott jóval kisebb eltérés van, így hajlamosak szinte „megfeledkezni” róluk. A normalizálással viszont azonos mértékűre hozhatjuk az egyes adatokat, így azonos lesz a „súlyuk” is.
A Normalize Data modul segítségével az adatainkat azonos volumenűre hozhatjuk. Erre akkor van szükség, ha nagyságrendbeli különbségek vannak köztük. A kisebb skálájú adatokat kevésbé veszik fontosnak az algoritmusok, hiszen ott jóval kisebb eltérés van, így hajlamosak szinte „megfeledkezni” róluk. A normalizálással viszont azonos mértékűre hozhatjuk az egyes adatokat, így azonos lesz a „súlyuk” is.