
Az előző postban eljutottam addig, hogy az adatokat kicsit módosítottam és a több osztályos tanulásból kétosztályos tanulást csináltam. Most ismét a későbbi könnyebb munka és egy kicsit az eredmények javítása céljából tovább bontottam az adathalmazt. Azaz teljesen különálló adathalmazt hoztam létre a tanuló és a teszt adatoknak. Ez azt jelenti, hogy mind a BENING és a MALIGNANT halmazból véletlenszerűen kiválasztottam 5 db sort tesztadatnak.
Adatok random szeparálása
Ezt a folyamatot egy kicsit komplikáltabb módon valósítottam meg (lássuk azt is, hogy az Azure ML támogat elég sok megvalósítási módot csak megfelelő Python vagy R tudásra van szükség :)), hogy később szintén szeparálva és összesítve is jól tudjam használni az adathalmazokat. Az előző postban ott hagytam abba, hogy megvan a két különálló adathalmazom a BENINGN és MALIGNANT adatokkal, azaz a két osztály adatai. Most ezeknek a kimenetét hozzákötöttem egy-egy Execute R Script module első bemenetéhez (értelemszerűen egy modul a jóindulatú és egy modul a rosszindulatú adathalmazhoz kapcsolva). Illetve a továbbiakra is gondolva az Add Rows module segítségével (ami fo két adathalmazt és egymás után fűzi őket) készítettem egy összevont adathalmazt. A következő ábrán jól látszik, hogy hogyan kapcsolódnak egymásba a modulok:
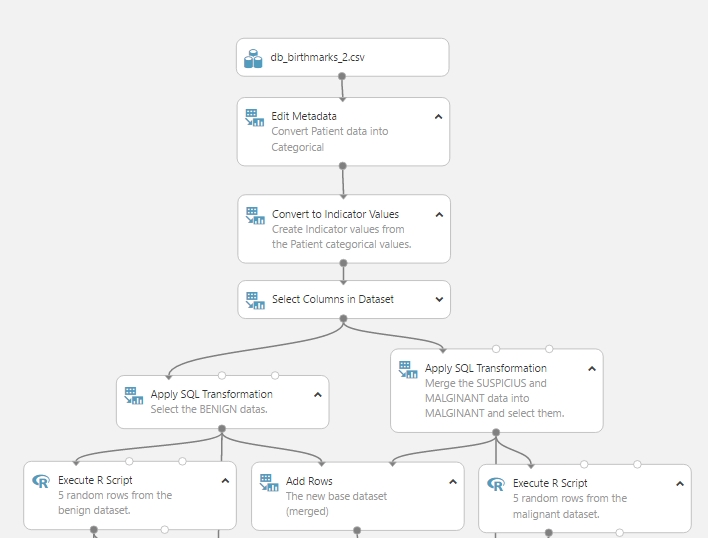
Az Add Rows modulnak semmi extra paraméterezésre nincs szüksége, csupán megadjuk a bemeneten a két adathalmazunkat és megkapjuk az összefőzött adatokat.
Az Execute R Script modulokban értelemszerűen egy-egy R kód hajtja végre a random mintavételezést az egyes adathalmazokon, ami a következőképpen néz ki:
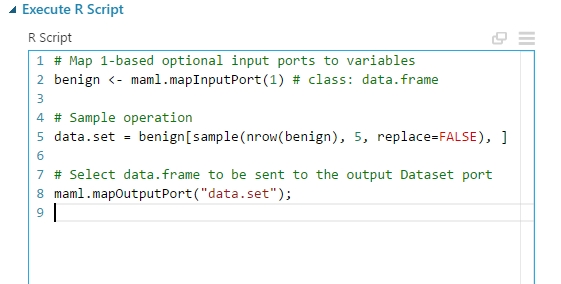 természetesen hasonló megvalósítás alapján van egy kód a malignant adatokra is. De mit is csinál a kód?
természetesen hasonló megvalósítás alapján van egy kód a malignant adatokra is. De mit is csinál a kód?
- a második sorban egyszerűen egy benign változóba olvassuk az 1-s inputról az adatokat.
- az ötödik sorban beállítunk egy új datasetet, amely a beolvasott benign adatokból mintavételezéssel n darab (jelen esetben 5) sort fog kiválasztani úgy hogy nincs a mintavételezés után csere az adathalmazban, azaz nem kerül a kivett minta helyére semmi.
- majd végül a nyolcadik sorban egyszerűen az output portra visszaadjuk az elkészített datasetet.
Az elkészült script a következő kimenetet fogja eredményezni:
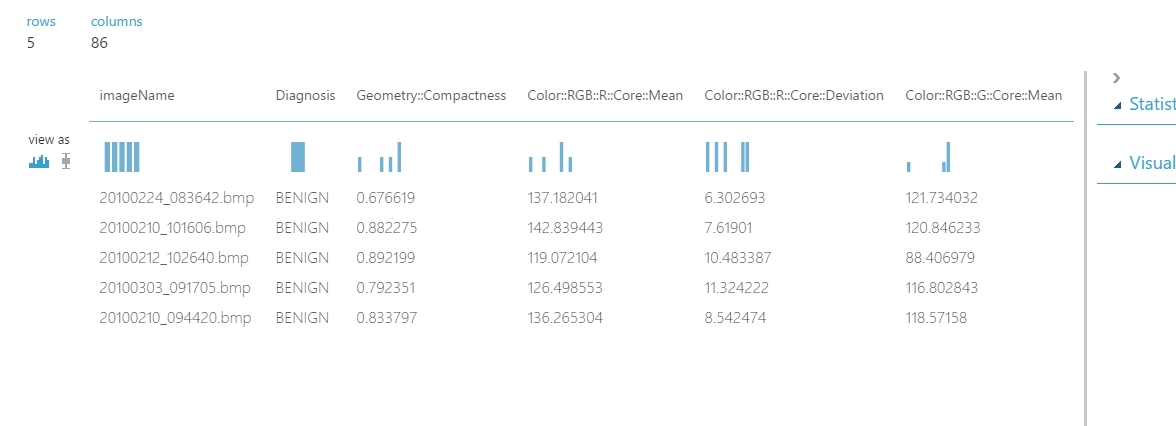
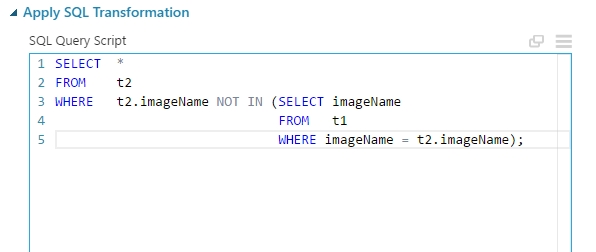
Miután random kiválasztottunk 5 darab adatot mind a kettő adathalmazból, ki kell válogatni a megmaradt adatokat (ugyanis a mintavételezés nem ketté bontja az adathalmazt ebben az esetben hanem egy újat képez). Ehhez egyszerűen egy Apply SQL Transformation modult használtam, aminek a bemenetére bekötöttem az újonnan létrehozott 5 soros adathalmazt és azt az adathalmazt amiből készítettem azt. Majd a modul segítségével egy egyszerű egymásba ágyazott lekérdezéssel kiválogattam a véletlenül választott adatokat a teljes adathalmazból (azonosításra az imageName mezőt használtam, amely egyedi, ez határozza meg hogy melyik képről lettek az adatok kigyűjtve):
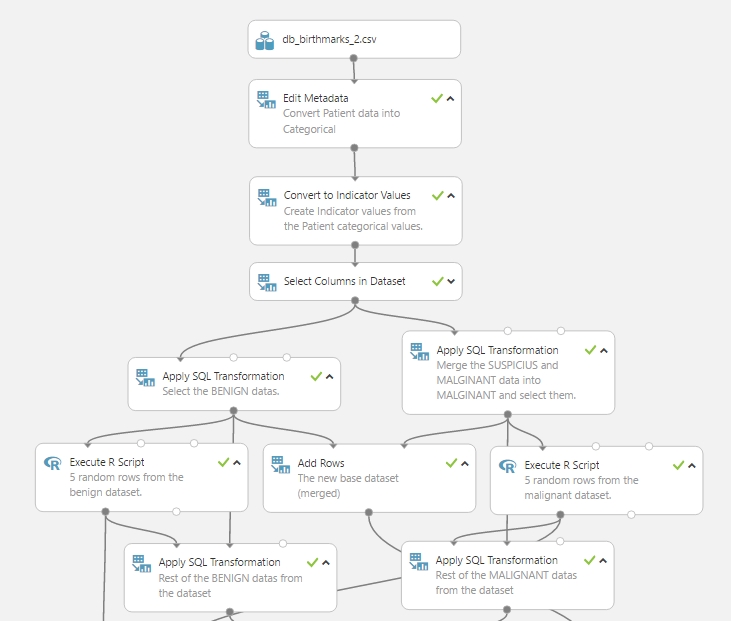
Az adataink szeparálása lényegében készen van, csupán a különálló teszt és tanuló adathalmazokat össze kell kapcsolni, hogy egyben is használhatóak legyen a kísérlet folytatásában. Ehhez ismét az Add Rows modult használjuk. Kettő modulra lesz szükség, az egyik a teszt adatokat állítja majd elő a két Execute R Script kimenetéről, a másik pedig a tanuló adathalmazt a két Apply SQL Transformation modul kimenetéről:
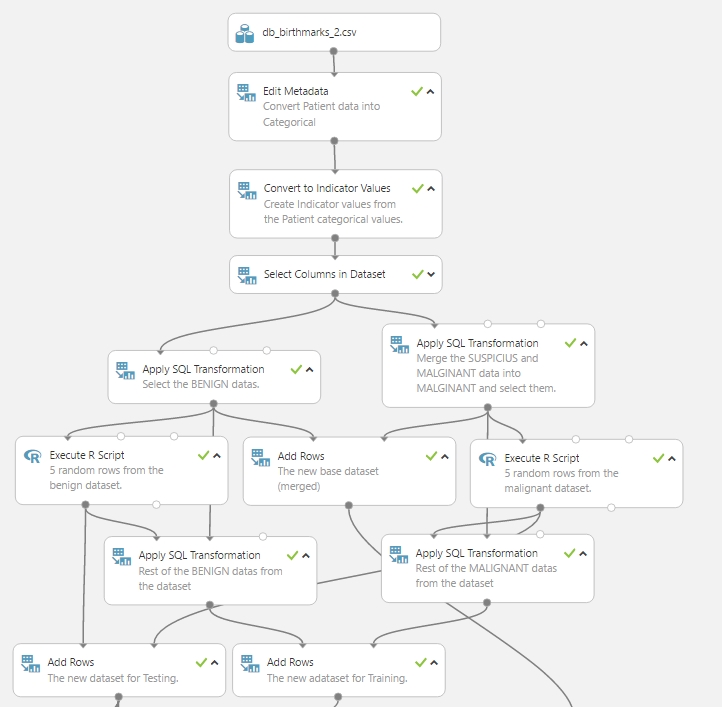
Nos, lehet nem a legegyszerűbb mód arra, hogy az adatainkból külön teszt és tanuló halmazt készítsünk, azonban így teljesen különálló, külön kezelhető halmazokat kapunk, ami a későbbiek során hasznos lehet, és látjuk azt is, hogy mindent meg lehet valósítani többféleképpen. (A másik módszer az az lenne, hogy a Split Data és a Partition and Sample modulok segítségével állítjuk elő a szükséges adathalmazainkat, azonban abban az esetben nem tudunk akkora kontrollt adni a dolognak mint így az R scripteket használva, illetve nem kapunk minden fázis végén egy felhasználható adathalmazt).