
Ma egy kicsit utánanéztem a Studio sebességének: néhány modult megírtam R-ben, majd lemértem, hogy melyik mennyi idő alatt fut le.
A Principal Component Analysis volt az első, mert ez már régen is fentűnt, hogy rendkívül lassú. Alul látható egy egyszerű példa: A wikipédiás szöveget hasheltem, majd csináltam egy főkomponens analízist R-rel, és a beépített modullal is. Mindkettőben 10 főkomponenst kértem, amit 4096 oszlopból kellett előállítani.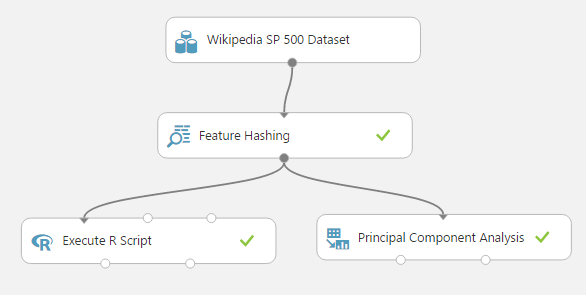
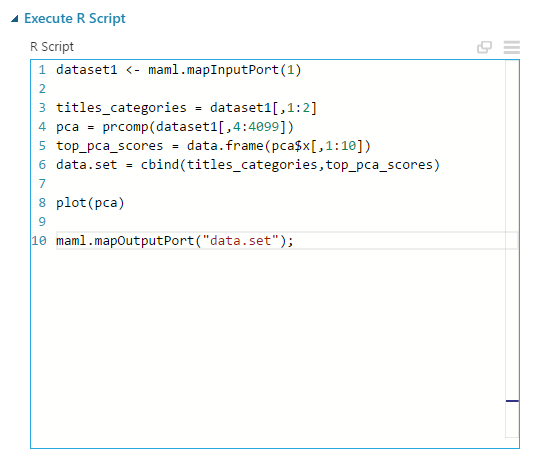
A megírt R programom 12,5 másodperc alatt végzett, a beépített komponens azonban – jól figyelj – 642 másodpercig dolgozott, azaz több, mint 10 percig. Ez azért már egy kicsit zavaró, főleg amikor haladna az ember, és még az ihlet is megvan… Szerencsére, ha egyszer lefutott, és nem változott a bemenete és a beállításai, akkor nem fog még egyszer lefutni (a Studio output cache-t használ), de ha éppen ezt a modult állítgatjuk, akkor sajnos végig kell várni minden módosításnál amíg lefut. Nem lett ugyan az az eredménye mindkét doboznak, nyilván valamit nagyon számol még a háttérben a Studio, azonban azt a blackbox miatt nem tudhatjuk, hogy micsodát. Az általam futtatott kód pedig az alábbi:
A következő választás egy algoritmusra esett, méghozzá az egyetlen felügyelet nélküli tanulást alkalmazóra, a k-means-re. Ez volt a próba kísérlet:
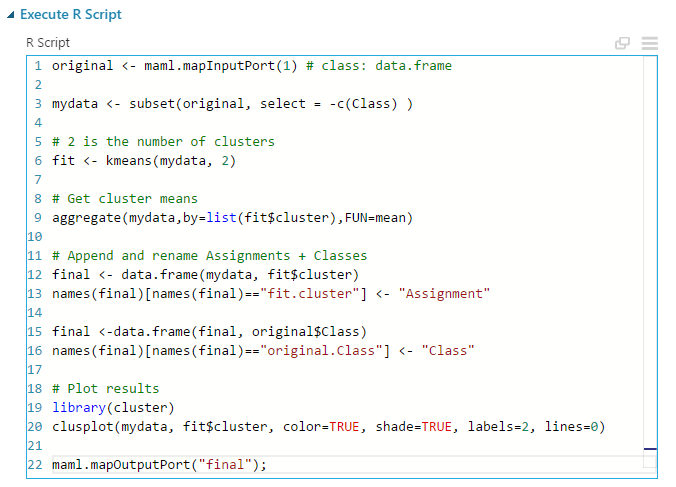
A bal oldalon látható a beépített, a jobb oldalon pedig az általam implementált megoldás. Létezik egy Create R Model nevű alkatrész is, de az sajnos nem támogatja a klaszterizálást, így nem tudtam volna betanítani a Train Clustering Model-lel, ezért egy Execute R script-be írtam az egészet. Itt már sokkal jobb a helyzet, gyorsan lefutott mind a kettő: az eredeti 11 másodperc alatt, a saját pedig 12 másodperc alatt. Itt teljesen idendtikus végeredményt kaptam, a klaszterező modul által produkált címkék:
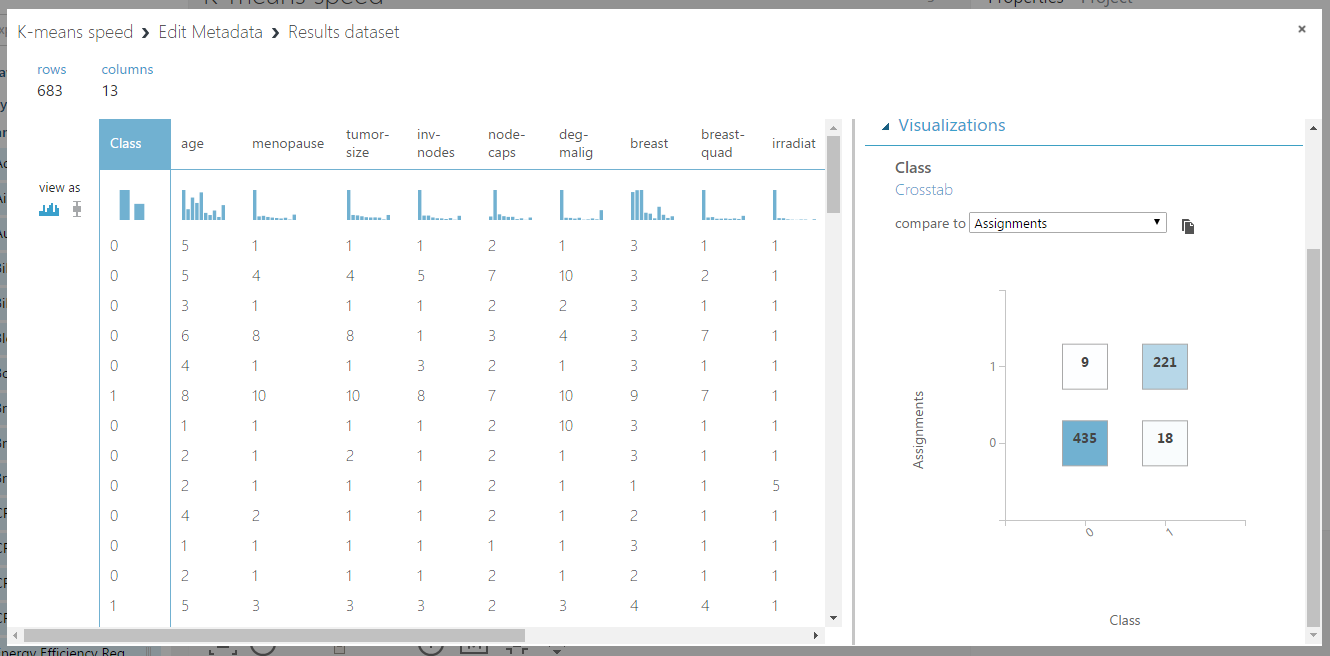
Ez pedig a sajátom:
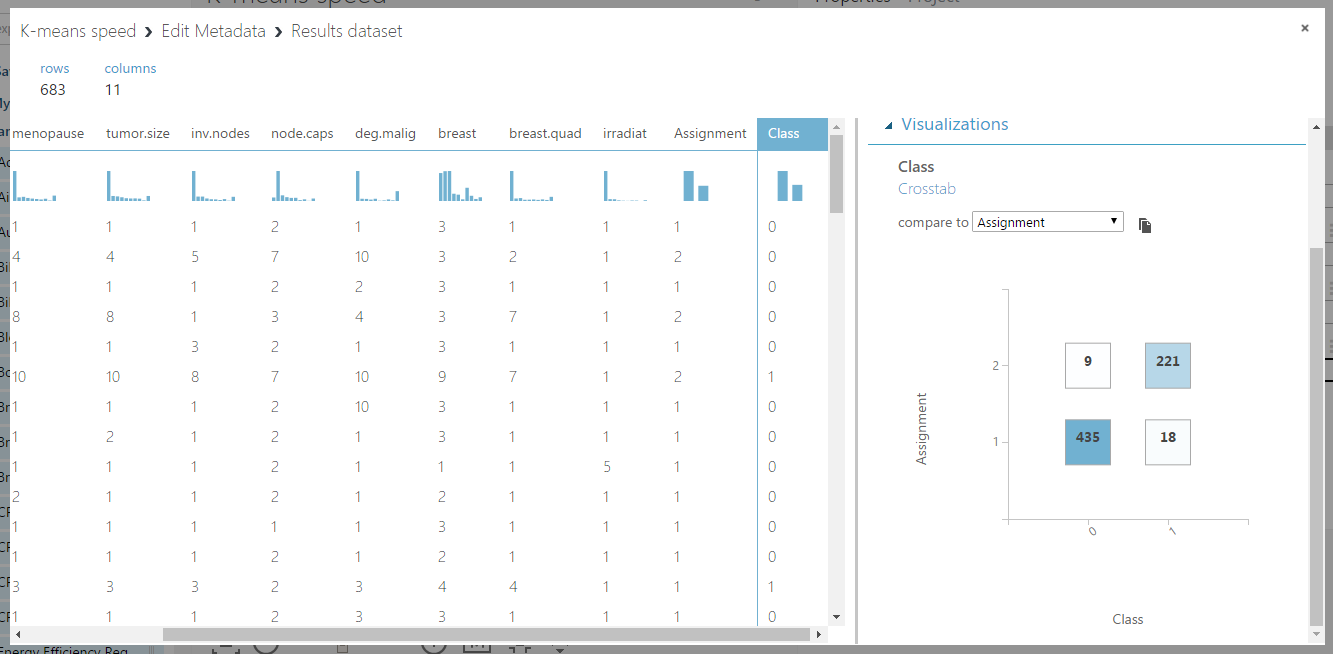
A jobb oldalon az eredeti osztálycímkéket hasonlítjuk össze a kapott csoportokkal, és látható, hogy ugyan azokat kaptuk meg (csak 0-1 helyett 1-2 névvel).
Az algoritmus pedig az alábbi volt:
A következő szintén egy algoritmus, méghozzá a Two-Class Support Vector Machine. Ahogy korábban már láthattuk, egy igen hasznos osztályozó algoritmus. A következőképpen néz ki a példa kísérlet:
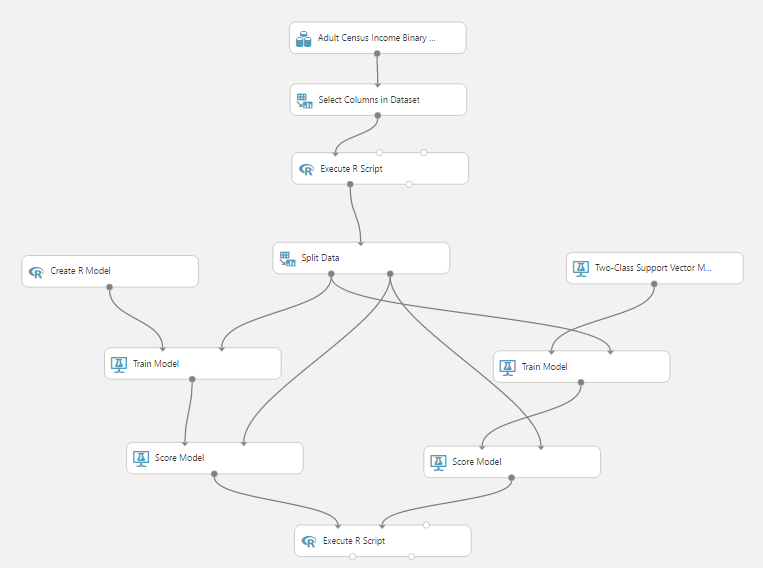
A beépített adathalmaz emberekről tartalmaz információkat (kor, nem, végzettség, ország…) és egy címkét, hogy 50 eyer dollár felett van-e a fizetése. Egy kis előfeldolgozás után jöhet is a lényeg:
A Create R Model-be lehet megírni a tanító és a pontozó szkriptet, majd bekötni egy tanító modulba. Ez az általunk írt tanító szkriptet fogja futtatni. Később a pontozó doboz is a mi általunk definiált kódot fogja futtatni, és ha bármi probléma van vele, itt kapunk hibaüzenetet.
Az eredeti modul 15 másodperc alatt futott le, a sajátomnak pedig 18 másodperc kellett. Viszont sikerült az eredeti 79%-os pontossághoz képest majdnem 2%-ot javítani!
Úgy néz ki, hogy az algoritmusokat jól optimalizálták, csak a PCA lett igen lassú. Az mindenesetre beigazolódott, hogy sok haszna van az R-rel való bővíthetőségnek, hiszen a több elérhető funkció mellett akár gyorsíthatunk is a már meglévőkön.