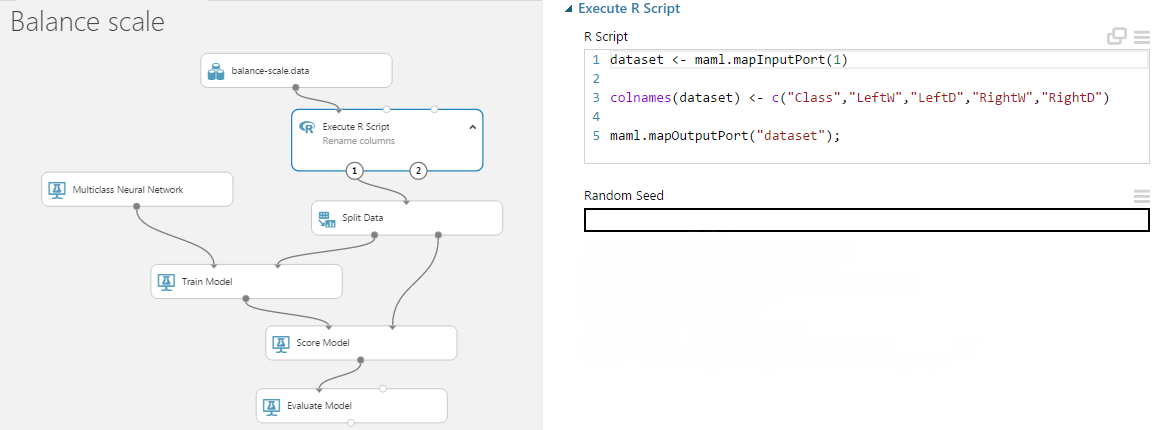
Oké, milyen algoritmust is kellene választanom a kísérletemben? Alapvetően sok-sok tényezőtől függ (méret, minőség, az adatok típusa, mit akarok kezdeni a kapott eredménnyel, hogyan tudom az adatokat a gép számára legjobban átadni és igazából mennyi időm is van arra, hogy eljátszadozzak az adatokkal). valójában még nagy tapasztalattal rendelkező ML guruk sem képesek minden egyes helyzethez megmondani, hogy melyik algoritmus fogja a legjobb eredményt adni az adott problémára (Ugye milyen jó, hogy néhány kattintással módosíthatunk mindent az ML Studióban? :D).
A nehéz fegyverzet
A Microsoft összeállított egy segédletet, ami megadja a kellő támogatást ahhoz, hogy ezen az aknamezőn átsétáljunk és minél jobb algoritmust válasszunk. Ez persze nem egy olyan dolog, hogy na akkor én ezt akarom csinálni ahhoz pedig pont az az algoritmus kell, sajnos vagy szerencsére nem. Sok algoritmus nincs is felsorolva benne, ezért csupán egy rendes útmutatást kapunk a nagyoktól, hogy ne lőjünk teljesen mellé a dolgoknak. Ez az egész segédlet nem csupán a Microsoft által kigondolt irányvonalak alapján készült, hanem nagy mennyiségű visszajelzések is alakítottak rajta.
Continue reading →

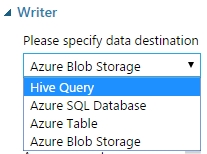 Az aktuális adathalmazunkat, vagy eredményeinket, részeredményeinket (lényegében bármit) el tudunk menteni a Writer modul segítségével. A modul a Data Input and Output csoportosítás alatt található. A modul segítségével írható Hive Query, Azure SQL Databse, Azure Table és Azure BLOB Storage.
Az aktuális adathalmazunkat, vagy eredményeinket, részeredményeinket (lényegében bármit) el tudunk menteni a Writer modul segítségével. A modul a Data Input and Output csoportosítás alatt található. A modul segítségével írható Hive Query, Azure SQL Databse, Azure Table és Azure BLOB Storage.