Feature Selection – a gépi tanuláson belül és statisztikában azt a folyamatot jelenti, amivel meghatározhatunk releváns, hasznos feature részhalmazt az analitikai modell megalkotásához. Segít meghatározni a hasznos inputok egy szűk keresztmetszetét, csökkenti a zajt és fejleszti a képzés hatékonyságát.
A feature selection kitűnően alkalmas arra, hogy fejlesszük a modellünket, és megelőzzük a problémákat. Ilyenekre kellene figyelni, hogy:
- Elképzelhető, hogy az adathalmaz tartalmaz redundáns vagy irreleváns feature-t, amik egyszerűen nem adnak semmilyen többlet információt a számunkra.
- Az adathalmaz irreleváns információt tartalmaz, ami semmilyen kontextusban nem határoz meg hasznos információt.
- Irreleváns adatok feldolgozása nem csak a futásidő terheli meg, hanem a rossz eredmény felé vezeti az modellt.
Az ML Studio biztosít néhány Feature Selection megoldást, így elég sok variációval tudunk dolgozni. Érdemes megjegyezni, hogy némely esetben a feature selection modul alkalmazása elhagyható, mert vannak olyan tanuló algoritmusok amelyek önmagukban is alkalmaznak valamilyen dimenziócsökkentő vagy jellemző kiválasztó eljárást. Ilyenkor a modul önállóan is képes eldönteni mi a legjobb input a számára. 🙂
A Studioban van három modul amit használhatunk erre a célra (további Feature Selection mély boncolgatásra használd ezt a linket), ezekből most megnézzük a Permutation Feature Importance modult.
Permutation Feature Importance
Minden egyes feature-re kiszámol egy értéket, az alapján, hogy ha random összekeverjük az értékeket és megváltoztatjuk, akkor hogyan változik meg a teljesítmény. Számos teljesítmény mértéket tudunk kiválasztani, hogy mi alapján végezze a mérést. Maga a modulnak szüksége van egy teszt adathalmazra és egy már képzett regressziós vagy osztályozási modellre.
Hogyan működik
A modul minden egyes feature oszlop értékeit megváltoztatja, felcseréli random módon, egyszerre csak egy oszlopot bántva. Majd minden változtatás után kiértékeli a helyzetet. A kiemelkedően fontos feature részhalmaz általában az összekeverésre jobban érzékeny.
A modul
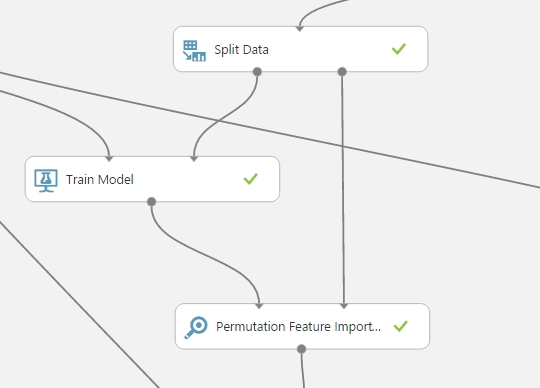
Ahogy fentebb írtam, szükség van egy képzett modellre, és egy teszt adathalmazra.
Az opciói között tudjuk beállítani, hogy mi legyen a random seed, amit ha 0-ra állítunk, akkor az aktuális rendszer időd veszi alapul a Studio.
Illetve a másik opció a mérési metrika kiválasztása. Itt általánosan is használt, ismert mérési metrikák vannak felsorolva, nem rétnék ki konkrétan a magyarázatra.
- Osztályozás – Pontosság
- Osztályozás – Precízió
- Osztályozás – Visszahívás
- Osztályozás – Átlagos belépési veszteség
- Regresszió – Átlagos abszolút hiba
- Regresszió – Root Mean Squared Error
- Regresszió – Relatív abszolút hiba
- Regresszió – Relatív négyzetes hiba
- Regresszió – Együttható meghatározás
Miután kiválasztottuk a mérési metrikát, futtatjuk a kísérletet, rögtön láthatjuk is a kimeneten, hogy melyik feature milyen értéket kapott (Kedvesen érték szerint sorba is rendezi alapból a modul nekünk 🙂 ).
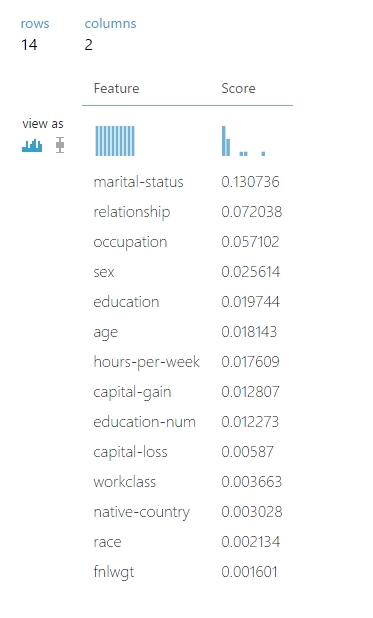
(Felnőtt jövedelem meghatározása, az alapadathalmaz segítségével)
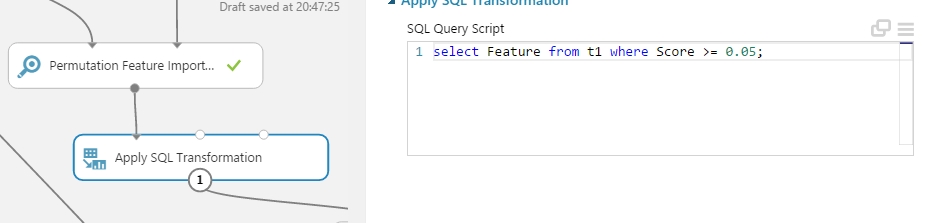
Azután egy egyszerű SQL transzformáció segítségével kiválasztom a számomra még hasznosnak megítélt ponthatár feletti featur halmazt.
Majd a megkapott eredményt felhasználva egy egyszerű R script segítségével az eredeti adathalmazból kiválasztom a megadott oszlopokat (mintha eredendően a Project Column modult használtam volna), így újra le tudom futtatni a számomra megfelelő algoritmust, de már csak a fontosnak ítélt feature halmazzal.
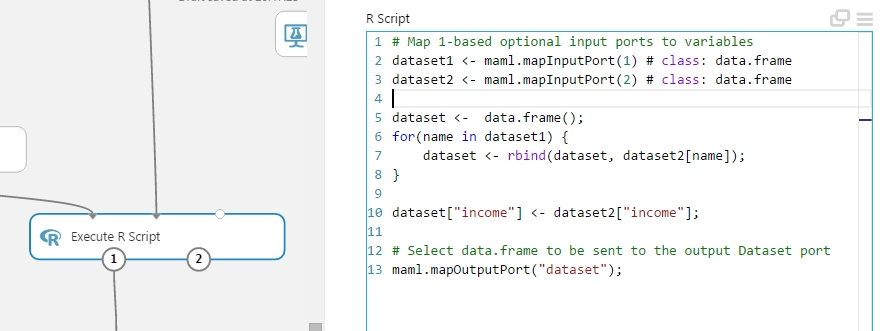
Ettől a ponttól kezdve pedig minden mehet úgy, ahogy megszoktuk a kísérletek felépítése során. Példa miatt összeraktam egy olyan kísérletet ami összehasonlítja, hogy a Permutation Feature Importance modul segítségével kiválogatott feature halmaz vagy a manuálisan próbálgatások által összeválogatott feature halmaz a jobb megoldás számunka.
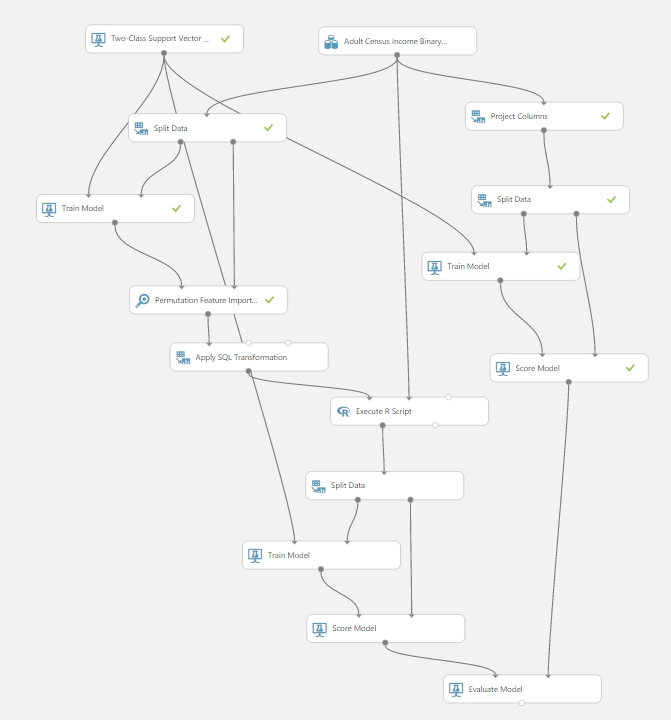
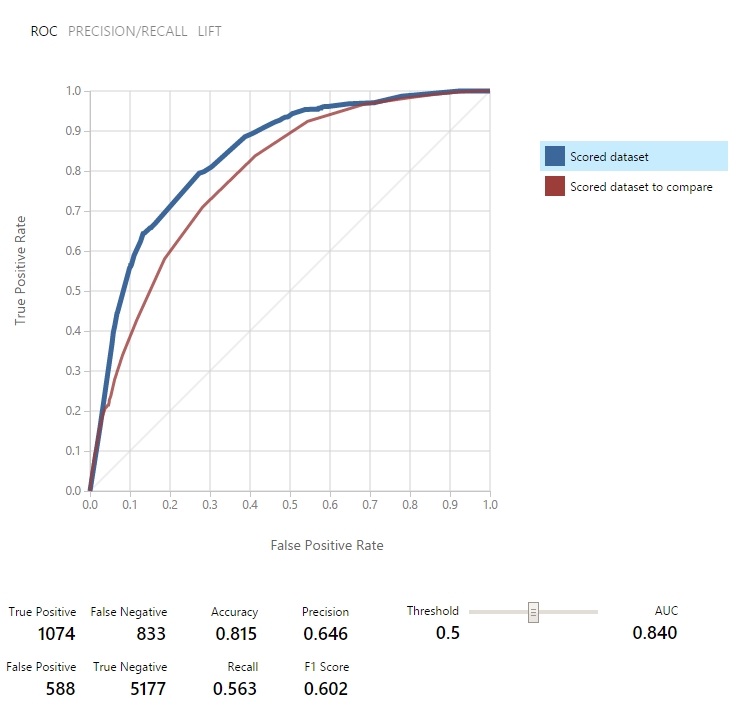
Többszöri próbálgatás után is látszott, hogy egy picit mindig jobb eredményt ad a modul használata, mint a manuális eset (kivéve persze mikor pont minden ugyanaz a manuális beállítások során):
(kék a modul által választott feature halmaz, piros a manuális)