
Oké, milyen algoritmust is kellene választanom a kísérletemben? Alapvetően sok-sok tényezőtől függ (méret, minőség, az adatok típusa, mit akarok kezdeni a kapott eredménnyel, hogyan tudom az adatokat a gép számára legjobban átadni és igazából mennyi időm is van arra, hogy eljátszadozzak az adatokkal). valójában még nagy tapasztalattal rendelkező ML guruk sem képesek minden egyes helyzethez megmondani, hogy melyik algoritmus fogja a legjobb eredményt adni az adott problémára (Ugye milyen jó, hogy néhány kattintással módosíthatunk mindent az ML Studióban? :D).
A nehéz fegyverzet
A Microsoft összeállított egy segédletet, ami megadja a kellő támogatást ahhoz, hogy ezen az aknamezőn átsétáljunk és minél jobb algoritmust válasszunk. Ez persze nem egy olyan dolog, hogy na akkor én ezt akarom csinálni ahhoz pedig pont az az algoritmus kell, sajnos vagy szerencsére nem. Sok algoritmus nincs is felsorolva benne, ezért csupán egy rendes útmutatást kapunk a nagyoktól, hogy ne lőjünk teljesen mellé a dolgoknak. Ez az egész segédlet nem csupán a Microsoft által kigondolt irányvonalak alapján készült, hanem nagy mennyiségű visszajelzések is alakítottak rajta.
Erről a segédletről lenne szó.
Hogyan is használjuk? Egyszerű, csak követni kell az útvonalat és olvasgatni a feliratokat, aminek a végén egy vagy több algoritmushoz fogunk eljutni. Természetesen megeshet az, hogy néha tökéletesen megtaláljuk azt amire szükségünk van, máskor pedig x próbálkozás után sincs meg a tökéletes jelölt (megjegyzés: x > 10). Ezért is most átfutok azon, hogy pontosabban hogyan is válasszunk algoritmust.
Tanulási típusok, megint…
Ellenőrzött tanulás.
Az ellenőrzött tanulás előre meghatározott példák alapján próbál meg egy eredményt előállítani. Minden egyes példához van egy címke, ami a értékét adja meg. Az ellenőrzött tanulási algoritmus mintát keres ezekben az értékkel ellátott címkékben (ehhez felhasználhat bármilyen információt amely releváns lehet). Minden algoritmus különböző mintákat keres keres. Ha megtalálta a megfelelő mintát, akkor szépen meghatározza/megjósolja a címkézetlen értékeket.
Az Azure Machine Learning csak ellenőrzött tanulást használó modulokat tartalmaz. Persze ezen belül több egyedi típus van: osztályozó, regressziós és anomália érzékelős.
- Osztályozó: Az adatokat lényegében kategorizálni kell. Például annak az esete, amikor van egy fénykép és meg kell mondani, hogy azon egy tyúk vagy kakas van :D. Ilyen esetben amikor két besorolási osztályunk van, két-osztályú (two-class) vagy binomiális (binomial)osztályozásnak nevezzük a dolgot. Egyéb esetben, tehát amikor több besorolási kategóriánk van, akkor multi-osztályú (multi-class) osztályozásnak nevezzük.
- Regressziós: Amikor egy folytonos értéket kell megjósolni, akkor az a regressziós kategóriába sorolható (pl. részvényárfolyam meghatározások).
- Anomálisa érzékelős: Lényegében arra jó, hogy szokatlan jelenségeket ismerjünk fel az adatokban. Ilyen lehet például a hitelkártyák használatában a hirtelen nagy költekezés, amely nem jellemző az adott kártyán. Az egész úgy működik, hogy megtanuljuk azt, mi a normális adat és azonosítjuk azt ami különbözik attól.
Ellenőrizetlen tanulás
Ismétlés erejéig megemlítem, hogy ennek az a lényege, hogy nincs az adatoknak címkéje vagy hasonló. Itt többnyire az a cél, hogy rendezzük az adatainkat és felismerjünk benne valamilyen mintát, struktúrát.
Megerősítéses tanulás
Az Azure nem használ ilyen fajta gépi tanulást, többnyire ezt a típust a robotikában alkalmazzák. Ha valakit mégis érdekel a dolog, kezdésnek ez a link jó lesz.
Mire figyeljünk?
Néhány fontos jellemző amit meg kell vizsgálni mielőtt eldöntjük, hogy melyik algoritmus kell nekünk.
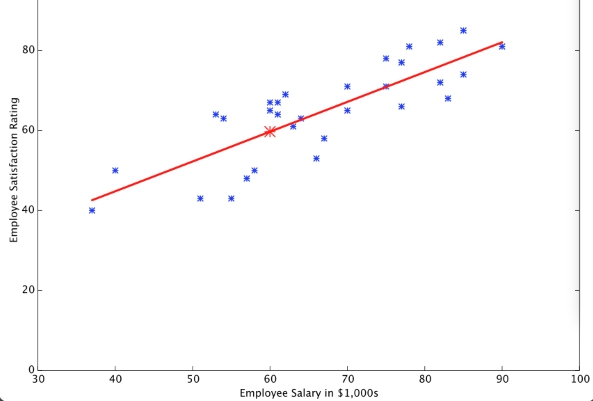
- Idő: A percek vagy az órák igen nagy kompromisszumra is rá tudnak kényszeríteni, mikor két algoritmus között kell dönteni. Fontos kérdés az idő, nem játszhatunk minden esetben a minél gyorsabb algoritmusra, mert a legtöbb esetben az idő és a pontosság szorosan függnek egymástól (ez olyan nem a legjobb barátok dolog). Legfőképpen akkor kell nagyon az időre figyelni, amikor az adathalmazunk kivételesen nagyra nőtt, azonban kisebb adathalmaz esetén sem szabad megfeledkezni az idő fontosságáról, remek útirány mutató is lehet belőle.
- Pontosság: Ez egy másik kompromisszumot követelő tényező. Ahogy fent az időnél említettem, a két jellemző nem a legjobb barátok, ezért lehet, hogy nem célszerű a legjobb, legnagyobb pontosságra törekedni minden esetben. Tudnunk kell, hogy mire akarjuk majd használni az eredményünket, és ahhoz nagyon pontos értékek szükségesek vagy csak elég ha egy bizonyos (persze nem túl nagy) hibaszázalékkal közelítjük az eredményt. Ez a kicsi kompromisszum igen nagy mértékben csökkentheti az algoritmus futásidejét. Egy jó megoldás, vagy használható ötlet lehet az is, hogy jobb vagy több közelítő metódust használunk az értékünk kiszámítására.
- Linearitás: A lineáris osztályozó algoritmusok feltételezik azt, hogy az osztályok azok szétválaszthatóak egy határozott egyenes mentén (vagy dimenzió mentén). A lineáris regresszió feltételezi, hogy az adatok alakulása egy egyenest fognak követni. Ezek a feltételezések nem feltétlen rosszak, de néha csökkenthetik a pontosságot. Ezek az algoritmusok nagyon népszerűek, és valóban sok mindenre “alkalmazhatóak”, gyorsak és gyorsan taníthatóak, ugyanakkor számos olyan valós probléma van amelyre képtelenség lineáris regressziót alkalmazni. Például: a dolgozók megelégedése a fizetésükhöz képest lehet lineáris, de a kávéeladások száma már nem feltétlen az.
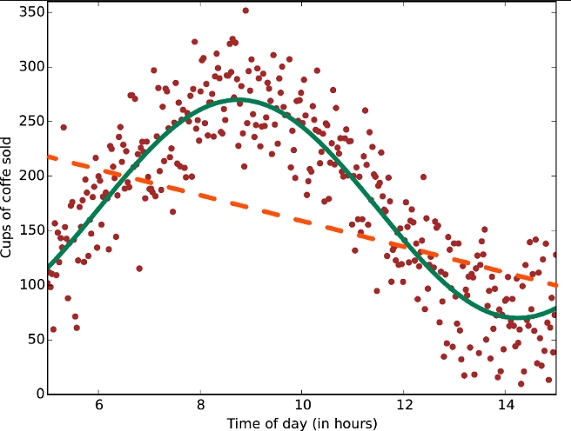
- Jellemzők száma: Bizonyos adattípusoknál, a nagy számú jellemzők gondot okozhatnak az egyed adatok vizsgálatánál. Ezek a problémák főként genetikus vagy kép állományoknál jönnek elő. A nagy mennyiségű jellemzők könnyen megakasztják az algoritmus futását egy adott ponton, ami miatt a ráfordításra szükséges idő eléggé megnyúlik. A vektoros támogatás ebben az esetekben nagyon hasznos tud lenni.
- Paraméterek száma: Ügyes kis szabályozó potméterek. Olyan dolgokra vannak hatással, mint a hiba tolerancia, iterációszám vagy változók közötti műveletek meghatározása, tehát meghatározzák azt, hogy hogyan viselkedjen egy algoritmus. A képzési idő és a pontosság nagymértékben befolyásolható azzal, hogy a megfelelő paramétereket a megfelelő értékre állítjuk be. Azonban általánosságban kijelenthető az, hogy az algoritmusoknak amelyeknek nagy számú paramétere van több próbálgatást igényel a jó megoldás meghatározásához. Ennek a kiküszöbölésére van egy remek modul az Azure ML-ben, amely fogja és végigpörgeti az összes lehetséges paraméter variációt, és a legjobbat fogja kidobni a végén, ez a parameter sweeping modul (persze ameddig ez fut, növekszik a szükséges idő is, hiszen nagy paraméter lista esetén elég sok variáció jöhet szembe). Viszont a sok paraméter lehetőség jelzi, hogy az algoritmus felxibilisebb, ami gyakran azzal jár, hogy könnyebben érnek el jó pontosságot.
- Speciális esetek: Néhány algoritmus részleges feltételezéseket készít az adatok szerkezetéről vagy az elvárt eredményről. Ha megtaláljuk azt amelyik pont illik arra amire szükségünk van, akkor egy hasznosabb, gyorsabb és pontosabb becslést/jóslást fog eredményezni.
Az algoritmusok…
Linear Regression
Ahogy már említettem, a lineáris regresszió az egy egyenest illeszt rá az adathalmazra. Gyors és egyszerű algoritmus, ugyanakkor pont ez a hibája is, hogy néhány problémához túl egyszerű.
Logistic regression
Bár a neve a regressziót tartalmazza, ennek ellenére ez egy two-class és multiclass osztályozó algoritmus. Egyszerű és gyors, akár a lineáris regresszió. Az algoritmus egy határozott egyenes helyett inkább egy ‘S’ alakú íves vonalat használ, amivel az adatokat csoportokra tudja osztani. A logisztikus regresszió az lineáris osztály határokat ad, így mielőtt használjuk, győződj meg arról, hogy a lineáris közelítés az egy olyan dolog amit értesz és tudsz használni.
Trees, forests, and jungles
A döntési erdők (regresszió, két-osztályos, és multiosztályos), döntési dzsungelek (két-osztályos és multiosztályos) és a megerősített döntési fák (regresszió és két-osztályos) algoritmusok mind a döntési fákon alapulnak, és mind alapvető gépi tanulási elgondolás. Sok változatuk van a döntési fáknak, de ugyanazt csinálja mind (a jellemzőteret osztják fel régiókra, többnyire ugyanazzal a címkével). Ezek lehetnek konzisztens kategória vagy konstans értékű régiók, attól függ, hogy regressziót vagy osztályozást végzünk.
Azért, mert a jellemzőtér elosztható tetszőlegesen kicsi területekre, könnyen elképzelhetjük hogy addig osztjuk egyre kisebb területekre a teret, amíg minden egyes térben csak egyetlen adatpont fog szerepelni, ez az extrém esete a dolgoknak. Ezt el szeretnénk kerülni, ezért sok olyan fa van amely matematikai fügvényekkel ügyel arra, hogy a fák ne korreláljanak.
A döntési erdők egyik hátránya, hogy igen nagy mennyiségű memóriát emésztenek fel. A döntési dzsungelek viszont kevesebb memóriát igényelnek de egy picivel több időigényük van.
A megerősített döntési fák úgy igyekeznek elkerülni a túltanulási problémát, hogy limitálják a tér leosztásának számát illetve hogy egy térben hány darab adatpont szerepelhet. Az algoritmus fák sorozata, minden egyes fa megtanulja kiegyenlíteni a hibát amit a balra elhagyott fa okozott esetlegesen. Ennek az eredménye egy nagyon pontos tanulás, aminek cserébe nagyon nagy a memória igénye. (Ha nem csak az egyes medián értékeket akarjuk az egyes régiókra megkapni, hanem a kvantális eloszlásokat is, akkor ez egy speciális esetnek minősül, amire külön van egy regressziós algoritmus: Fast forest quantile regression.)
Neural networks and perceptrons
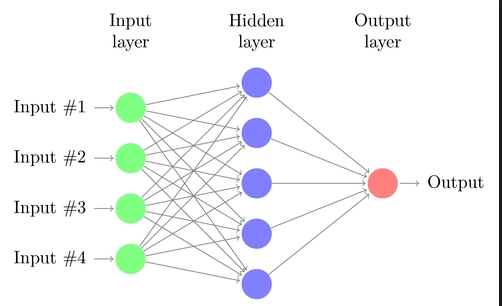
A neurális hálók, az emberi agy működését modellezik le (vagyis az alapelgondolást az agy működése ihlette), ezek az algoritmusok lefedik a multiclass, two-class és a regression problémákat. Az Azure ML-ben minden neurális háló irányított körmentes gráf alapú. Ez azt jelenti, hogy az input jellemzők előrefelé haladnak keresztül a az egyes szekvencia rétegeken, mielőtt át lennének alakítva kimenetté. Minden egyes rétegben az inputok súlyozottak különböző kombinációkban, és átadódnak a következő réteg felé. A kombinációknak az egyszerű számítgatása azzal végződik, hogy kifinomult osztályhatárokat és adattrendeket tanulnak meg. Persze ne legyen nagy az öröm, ennek ára van. Magas időigényű a dolog, és az adathalmazoknak nagyon sok jellemzőjük van. paraméterből is sokkal több van mint a legtöbb algoritmusnak.
Egy neurális hálózat leegyszerűsített nézete:
SVMs
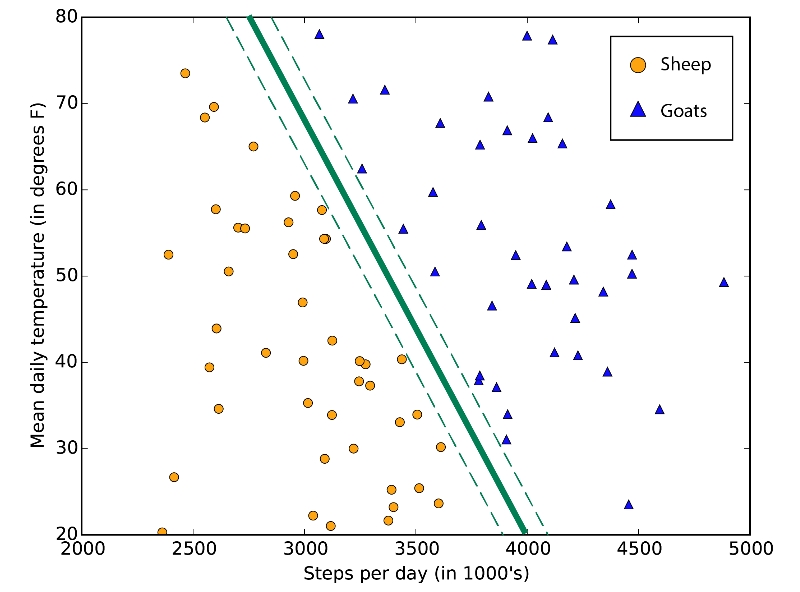
SVM = Support Vector Machines (támogató vektor hálózatok). A lényeg, hogy megtalálja azt a határt ami a lehető legnagyobb margóval szétválasztja az osztályokat. Ha egy két osztály nem választható el tisztán egymástól, akkor megpróbálja megkeresni a lehető legjobb határt. Az Azure ML egy határozott egyenes vonallal oldja ezt meg a two-class SVM modul segítségével. Mivel egyenes vonalat használ, azaz lineáris közelítés játszik a dologban, képes nagyon gyorsan lefutni. Az SVM igazán a szöveges vagy genetiai adatokkal képes szép teljesítményeket elérni. Ezekben az esetekben az algoritmus képes az osztályokat gyorsabban elkülöníteni, mindezt úgy, hogy kevesebb a túltanulás mint a többi algoritmusban (és hab a tortán hogy nem igényel észvesztően sok memóriát).
Az ábrán látható, hogy mire is jó, tehát a lehető legnagyobb helyközzel választja ketté az osztályokat:
Van ennek egy másik, nem-lineáris verziója is amely nagyjából megtartja a lineáris verzió sebesség és memória hatékonyságát. Akkor használatos, amikor a lineáris közelítés nem ad elég pontos választ.
Bayesian methods
A Bayes módszereknek van egy nagyon nagyon vonzó tulajkdonsága: kerülik a ‘túltanítást’. Ezt úgy érik el, hogy a válasz valószínű eloszlásáról készítenek néhány előzetes felvetést. Ennek egy mellékterméke, hogy nagyon kevés paraméterük van ezáltal. Az Azure ML-nek van Bayes algoritmusa mind az osztályozásra (two-class Bayes’ point machine) és mind a regresszióra (Bayes linear regression).
Specialized algorithms
Ha nagyon nem egy átlagos figura vagy akkor van itt néhány algoritmus az Azure ML-ben ami specializálódott a rank meghatározásra (ordinal regression), számolásmeghatározásra (Poisson regression) és anomália felismerésre (egy a Principal Component Analysy és egy az SVM alapján). Végül persze van egy csoportosítási algoritmus is (K-means).