
A TensorFlow regressziós példáján keresztül utánanéztem, hogy egy modell építése során használt egyes függvényeknek milyen argumentumai lehetnek és ezek mit jelentenek. A regressziós probléma esetén egy folyamatos érték, például ár vagy valószínűség előrejelzése a célunk. Ellenben az osztályozási problémával, amikor egy címkét akarunk megjósolni, például, hogy egy kép milyen fajta ruhadarabot ábrázol.
tf.keras: egy magas szintű API a TensorFlow modellek létrehozására.
Normalize features – Adatok normalizálsása
Javasolt normalizálni a különböző tartományokban mozgó adatokat.
Setup the layers – Rétegek beállítása
model = keras.Sequential([
layers.Dense(64, activation=tf.nn.relu,
input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation=tf.nn.relu),
layers.Dense(1)
])
A Sequential model egy lineáris rétegsor. Létrehozhatunk Sequential modellt a konstruktornak átadott réteg példányok listájával. A modellnek tudnia kell, hogy milyen input alakot (input shape) várhat. Emiatt az első rétegnek a Sequential modellben (és csak a legelsőnek, mert az ezt követő rétegek már automatikusan kikövetkeztetik) szüksége van információra az input alakjáról.
Ez a modell két sűrűn összekapcsolt (densely connected), rejtett rétegből és egy output rétegből áll, ami egyetlen, folytonos értéket ad vissza. Az első és második Dense réteg is 64 neuront tartalmaz, az utolsó pedig egyetlen értékkel tér vissza.
Dense réteg:
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
- units: pozitív integer, a kimenet mérete.
- activation: Aktivációs függvény használata. Ha nincs megadva, akkor nem alkalmazzák (pl. “lineáris” activation: a(x) = x).
Aktivációs függvény szerepelhet Activation rétegben, vagy activation argumentumként. Rendelkezésre álló aktivációs argumentumok pl.:
- softmax: Softmax activation function= normalized exponential function (normalizált exponenciális függvény)

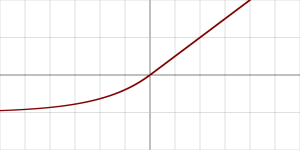
- elu: Exponential linear unit. (Exponenciális lineáris)
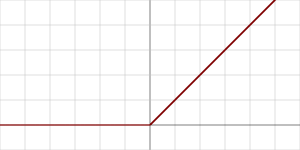
- relu: Rectified Linear Unit. (Egyenesített lineáris)
Compile the model – Modell fordítása
Mielőtt a modell kész lenne a tanításra szükségünk lesz még néhány beállításra. Ezeket a modell fordítása közben végezzük el:
model.compile(loss='mse', optimizer= tf.train.RMSPropOptimizer(0.001), metrics=['mae', 'mse'])
- Loss function: Ez azt mutatja, mennyire pontos a modell a tanítás során. Ezt a funkciót minimalizálni akarjuk, hogy a modellt a megfelelő irányba “irányítsuk”.
- Optimizer: Így frissül a modell az általa látott adatok alapján és a loss függvény alapján.
- Metrics: Tanítási és tesztelési lépések monitorozására szolgál.
- Mean Squared Error: mean_squared_error, MSE or mse
- Mean Absolute Error: mean_absolute_error, MAE, mae
- Mean Absolute Percentage Error: mean_absolute_percentage_error, MAPE, mape
- Cosine Proximity: cosine_proximity, cosine
Training the neural network – Neurális háló tanítása
model.fit(train_images, train_labels, epochs=5)
fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None)
- x: Numpy array a tanítási adatoknak.
- y: Numpy array a címke(label) adatoknak.
- batch_size: Integer vagy None. A minták száma gradiens frissítésenként. Ha nincs megadva, akkor a default batch_size 32.
- epochs: Integer. „Szakaszok” (epochs) száma a modell tanításához.
- validation_split: Float 0 és 1 között. A tanítási adatok mekkora része az, melyet validációs adatként használunk.
Evaluate accuracy – Pontosság kiértékelése
loss, mae, mse= model.evaluate(normed_test_data, test_labels, verbose=0)
print("Testing set Mean Abs Error: {:5.2f} MPG".format(mae))
Testing set Mean Abs Error: 1.88 MPG
evaluate(x=None, y=None, batch_size=None, verbose=1, sample_weight=None, steps=None)
- verbose: 0 vagy 1. Verbosity mode. Hogyan szeretném látni a tanítási folyamatot az egyes szakaszok (epoch) során:
-
0 = silent, nem látunk semmit
-
1 = progress bar, egy animált folyamat sávot rajzol ki így:
Megmutatja, hogy a modell hogyan teljesít a teszt adatokon, amiket nem látott még a tanítás során. Visszatér a modell tesztelés során kapott loss értékével és a metrics értékeivel. A modell pontossága a tesztelési adatokon kicsit kisebb lehet, mint a tanítási adatokon. Ez a különbség a tanítási és tesztelési pontosság között egy példa lehet az overfitting-re.
Overfitting azt jelenti, amikor a modell rosszabbul teljesít az új adatokon, mint a tanítási adatokon.
Make predictions – Jóslatok készítése
predictions = model.predict(test_data)
predict(x, batch_size=None, verbose=0, steps=None)
- x: az input adat, egy Numpy array (vagy egy Numpy array lista, ha a modellnek összetett inputja van)
- batch_size: Ha nincs megadva neki érték, akkor a default értéke 32.
- verbose: 0 vagy 1.
- steps: Az összes lépés száma (batches of samples) mielőtt a predikciós kör deklarációja befejeződne.
Visszatérési értéke egy Numpy array, ami a megjósolt értékeket tartalmazza a kapott input minták alapján.