Ha már felépítettük a kísérletet, minden rendben van, akkor ideje kinyerni belőle a hasznos adatot amiért végül is dolgoztunk. Átfutunk gyorsan és egyszerűen egy recommender system dolgon. Mint már korábban említettem valamikor, van elég sok olyan alkalmazása a gépi tanulásnak, hogy például a vásárlásaid alapján, vagy tervezett vásárlásaid alapján (i mean wishlist) a rendszer kidobálja, hogy más vásárolók miket vettek meg, vagy néztek még meg, és nagy valószínűséggel az neked is tetszene (erősen próbálnak rávenni arra, hogy termeld szépen a profitot nekik 😀 ).
Szóval, lényeg jön… Van egy három részes adatbázisom, amiben felhasználói adatai, filmek adatai és a felhasználók értékelése az egyes filmekre. Összeraktam egy egyszerű példát olyan kísérletre, amiben ezen adatok rendelkezése állása alapján, ha megadunk egy user azonosítót, akkor válaszként sorban megkapjuk, hogy az adott felhasználónak nagy valószínűséggel melyik filmek tetszenének, azaz melyiket ajánljuk számára.
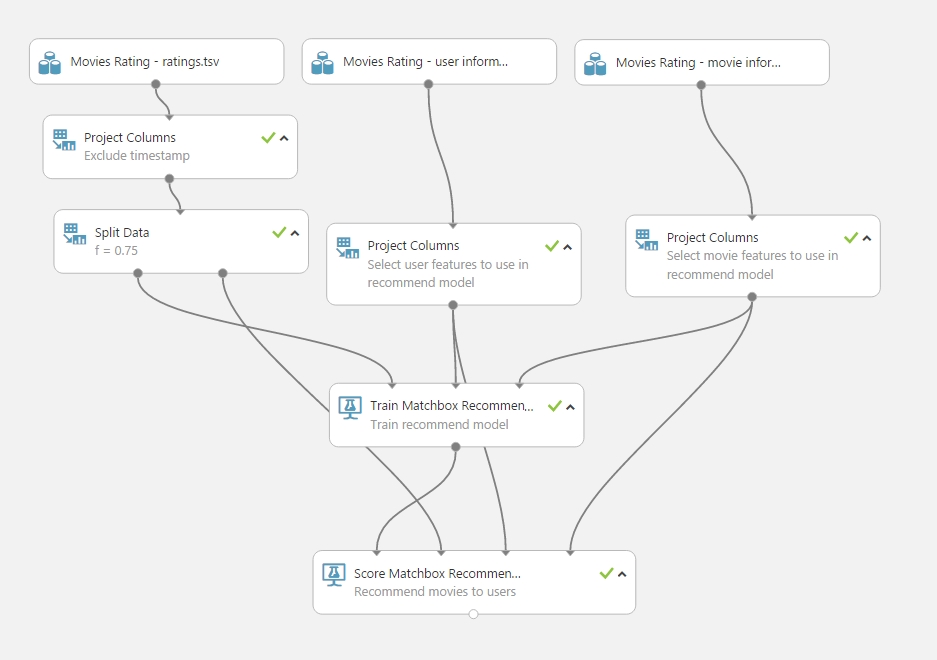
A példa kísérlet valahogy így néz ki:
Egy gyors összefoglalás mi miért is:
- Az első adathalmaz tartalmazza az egyes use-és film azonosítókat, rétingeket és egy időbélyegeket. Mivel később a Train Matchbox Recommender csak egy hármasokból álló adathalmaz vár képző adathalmaz bemenetére így a timestamp-et levágom a Project Column-al. Majd szokásos módon az adathalmazt ketté osztjuk egy Split Data modullal (ahogy eddig is a nagyobb része megy a képzésre a kisebb pedig a pontozásra).
- A második adathalmaz tartalmazza az egyes user információkat (pl.: azonosító, kor, nem, foglalkozás…). Ezekből a már ismert módon összeállítunk egy új adathalmazt azokkal a tulajdonságokkal amiket használni akarunk az ajánlatkészítéskor (ezt mindenkinek a saját ízlésvilágára bízom 🙂 ).
- A harmadik adathalmaz értelemszerűen az egyes értékelt filmeknek az adatait tartalmazzák (pl.: cím, megjelenési dátum, kategória….). Ahogyan a user adatokkal is tettük, itt is kiválasztjuk, hogy melyik jellemzőkre van szükségünk a későbbiekben, ezt az ismert módon a Project Column megint elvégzi szépen.
- Egy fontos összetevő, a Train Matchbox Recommender ami a Matchbox algoritmust használja. A modul a helyes működéshez a bemeneteire a fent leírt sémára épülő dolgot várja, tehát első inputra egy (user-id,item-id,rating) hármas adathalmaz megy (se több se kevesebb jellemző), a másik két inputon pedig egy-egy információs adathalmaz mind user, mind item tekintetében.
- Végül a Score Matcbox Recommender modul, ami lényegében visszaadja, hogy akkor adott user-nek mely itemeket ajánljuk fel.
A Score Matchbox Recommender tulajdonságai:
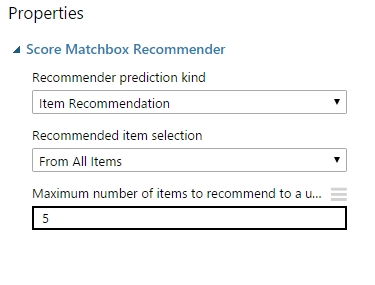
Megadhatjuk, hogy végül hány darab ajánlatot adjon vissza (“prioritási” sorban adja vissza, értem ez alatt, hogy az első a legjobban ajánlott item, és aztán sorban a többi….).
A máik nagyon fontos tulajdonság a Recommender prediction kind, itt jön ki a szépsége a rendszernek, mert van több alternatíva is, hogy mit akarunk pontosan visszakapni (persze ahhoz kell igazítani a fenti inputokat is).
Választhatunk 4 opció közül:
- Rating Prediction – Egy rétinget fog jósolni az átadott user és item párhoz.
- Item Recommendation – Itemeket fog ajánlani az átadott userhez.
- Related Users – Az átadott userhez hasonló usereket fog adni.
- Find Items – Az átadott itemhez hasonló itemeket fog adni.
Szóval, nekem most ugye az kell, hogy Item Recommendation, mert filmeket akarok ajánlani az egyes usereknek. Ha minden megvan, akkor egy futtatás után meg is kapjuk, hogy az egyes usereknek mely filmeket ajánlja a rendszer. (értelemszerűen itt most azonosítók szerepelnek 😀 )
Nézzük működik-e rendesen…. Ehhez csupán annyit kell tenni, hogy a kísérletből egy Web Service-t készítünk. Az alsó menüsávban van is erre egy csinos kis gomb.
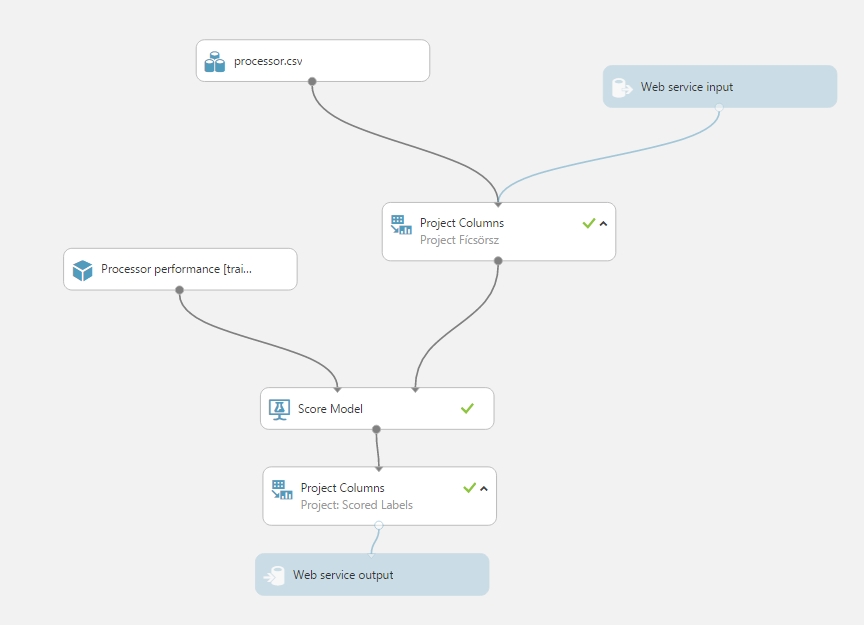
(Mivel már előre megcsináltam a projectet és utólag írom ezt, így nekem egy Update van amit használok.) Ha megvan a Web Service, akkor kapunk egy új munkafelületet, ahol kicsit megváltozik a dolgok helyzete. Kapunk egy Web service input és output modult, ahol értelemszerűen megadjuk a bemenetet és valahol majd printelődik is. Egy kicsit testre kell szabni a tökéletes működéshez általában, azaz figyelni kell, hogy a Web service input modul hova csatlakozik be, milyen jellemzőket akarunk bekérni majd. Én most annyi módosítást csináltam, hogy a ratings adathalmazból a Project Column modullal most csak a user azonosítókat veszem ki, csak azt akarom majd a web service inputon is megadni, majd mielőtt az outputra kiküldöm a megoldást, az adathalmazról levágom a user azonosítókat, mert arra semmi szükség a továbbiakban. Végül valami ilyen formát kapott a dolog:
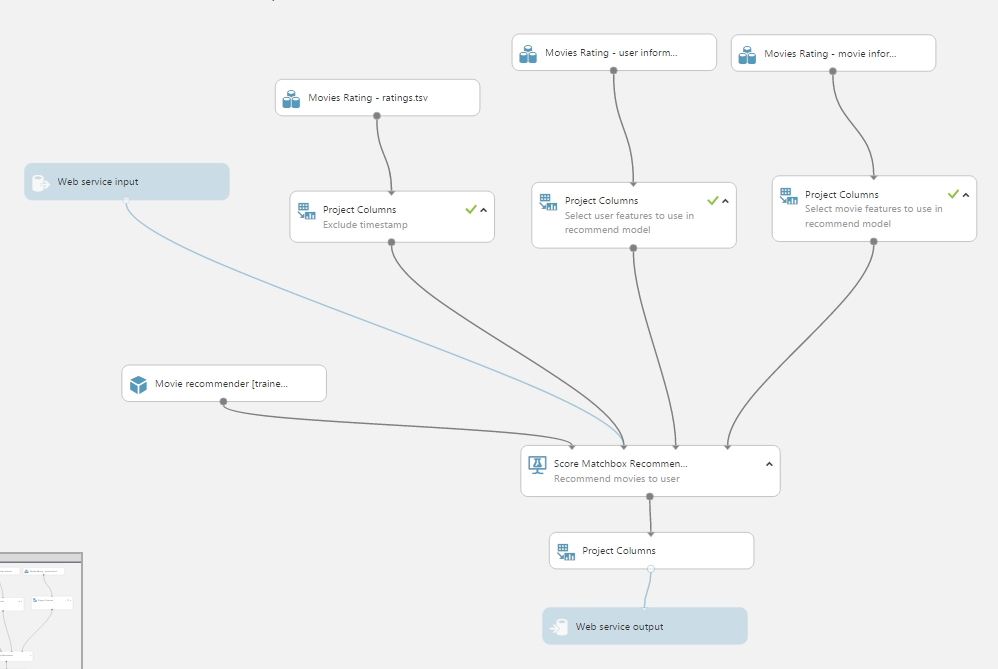
Ha ez megvan persze itt is futtatni kell a kísérletet, hogy minden beálljon megfelelően és ellenőrizni tudjuk, hogy minden úgy történik ahogy kell. Ha a futásnak vége, akkor a Deploy Web Service gomb segít abban, hogy valóban használni kezdjük a modellt.
Ha minden rendben ment, akkor átkerülünk a Web Service menübe, ahol be is tölti nekünk kevesen a rendszer az éppen létrejött új csomagunkat. (API kulcs piros, nem ajánlatos mindenkinek mutogatni 🙂 )
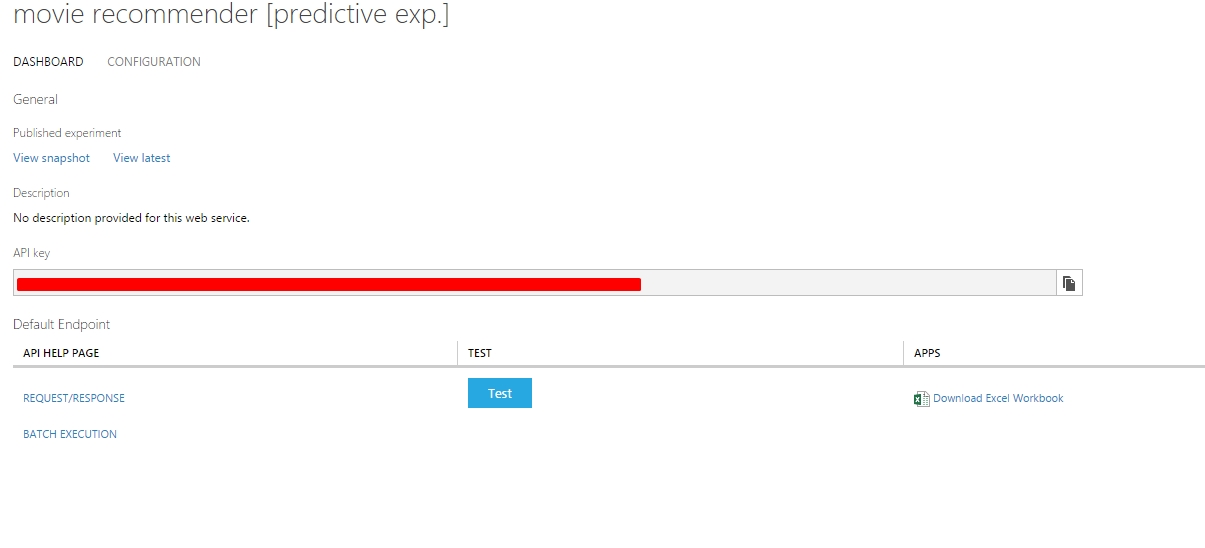
Itt lehetőségünk van két féle tesztet végrehajtani, rögtön a Studióban, ehhez egy Test feliratú gombot kell keresni. Megjelenik egy ablak, ahol az előzőekben beállítottak szerint (ha minden jól ment) meg tudjuk adni inputot. Majd az inputok megadása után egy Submit gombbal munkára fogjuk szolgáltatást és a végén megkapjuk az eredményt.
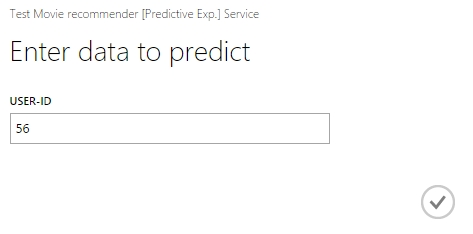
Majd az eredmény:

Azaz az 56 azonosítóval rendelkező usernek a 318, 313, 64,114 és végül a 173-as azonosítóval ellátott filmet fogjuk ajánlani.
A másik tesztelési lehetőség, az Excel, le tudunk tölteni egy Escel állományt, ami ügyesen makrózott (igen, szükséges engedélyezni az Excellben a makrók használatát), és ugyanúgy használható mint a Studiós teszt, lesz egy input mező, és lesz 5 output mező, miután megadtuk az inputot rögtön kapjuk is az outputot, tiszta sor 🙂

Ami még nagyon jó, hogy fel tudjuk használni a szolgáltatást Request/Response és Batch Execution használatával is. Jelenleg itt egy kicsit falba ütköztem, mert láthatólag minden működik, azonban egy web appal nem hajlandó megállapodásra jutni a dolog. (Amint van megoldás jön az is :), és persze hogy mire kell ügyelni…) Addig is a kolléga egy ezt megelőző postban remekül bemutatja hogyan is megy a folyamat.
Lényegében ennyi lenne az, hogy kinyerjük az eredményünket valamilyen felhasználható formában.
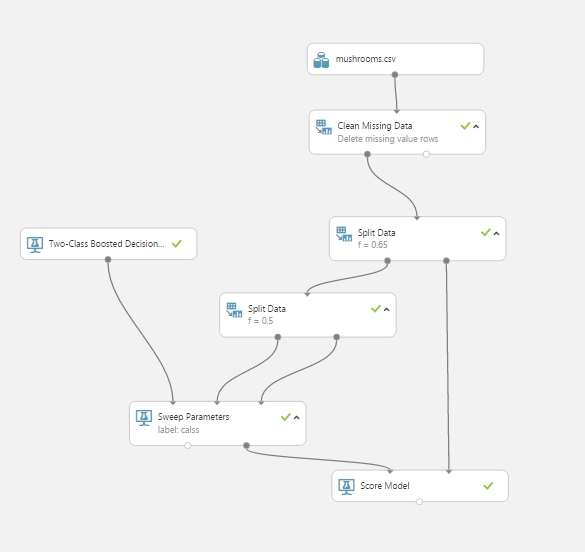
Minden egyes típusra (Ha véletlen nem lenne tiszta mire gondolok: Linear Regression, Clustering, Multi-Class Classification, Two-Class Classification) hasonló folyamatot kell elvégezni, ahhoz, hogy a fenti módszerek valamelyikét használva kinyerjük az adatokat.
Minden egyes eshetőséghez készítettem egy-egy kísérletet ami gyakorlásra tökéletes volt, és esetleges apróbb eltéréseket lehet megnézni az egyes esetek modellezése közben. A következőkben csak felsorolom ezeket és az elkészült kísérletek web service és sima kísérlet terveit rakom ki, csupán példák, különösebb bravúrok nélkül.
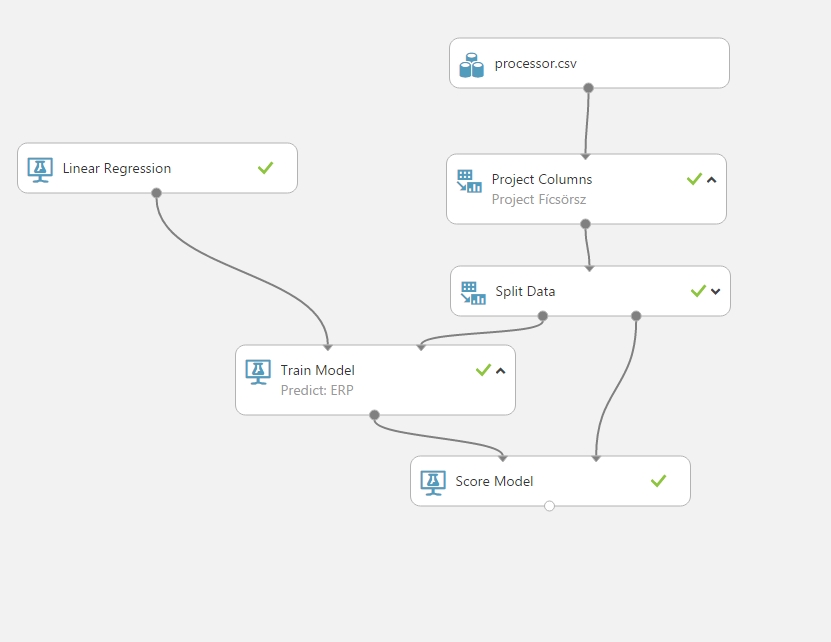
Linear Regression (Processzorok teljesítményjellemzőjének jóslása):
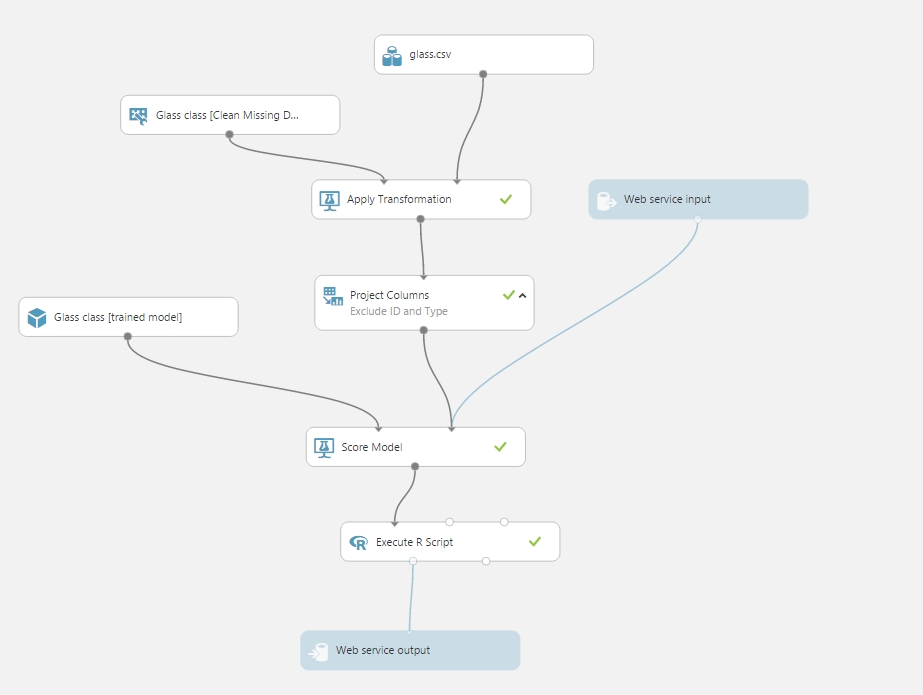
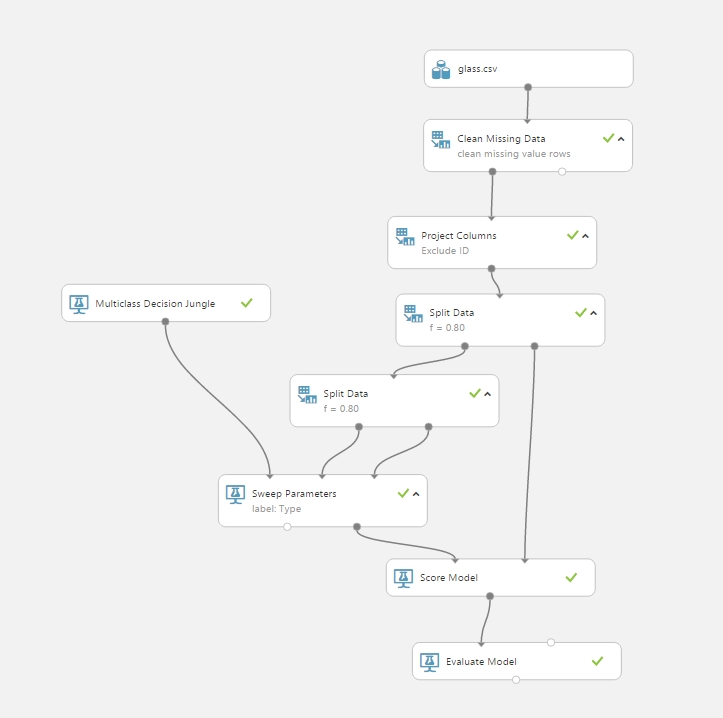
Multi-Class Classification (Üvegek típusának meghatározása a gyártás során felhasznált alapanyagok alapján):
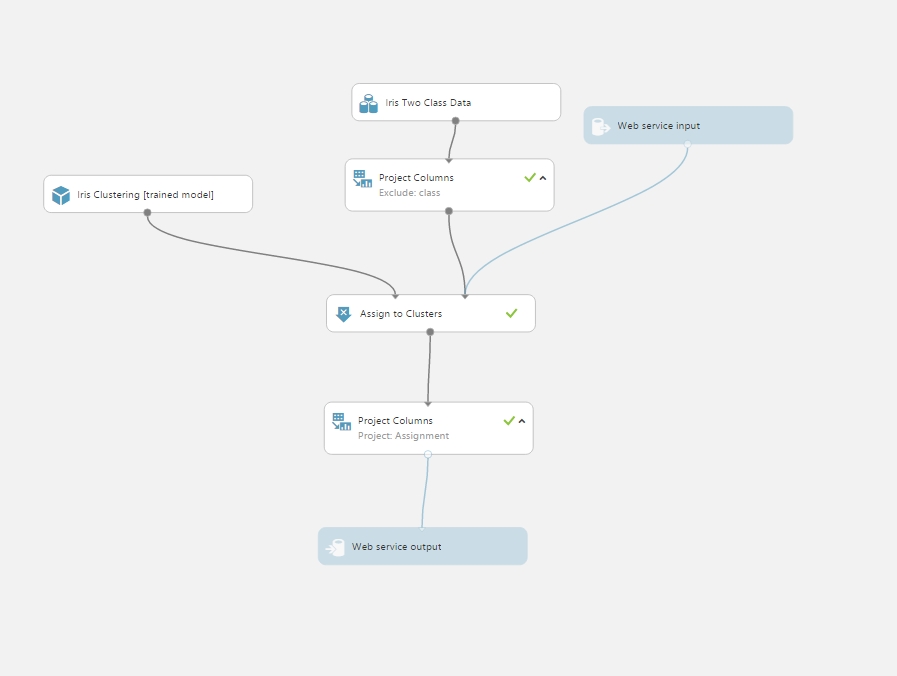
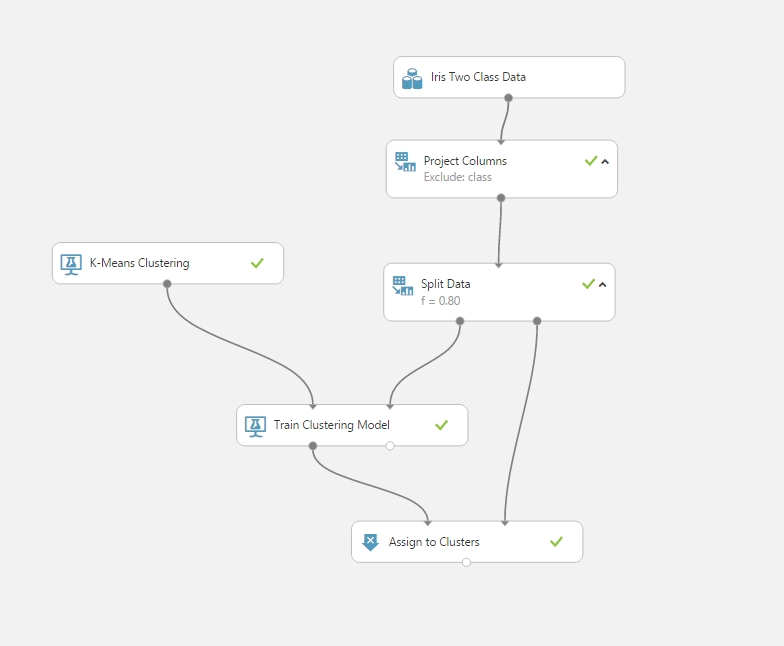
Clustering (Virágok íriszeinek klaszterbe sorolása):
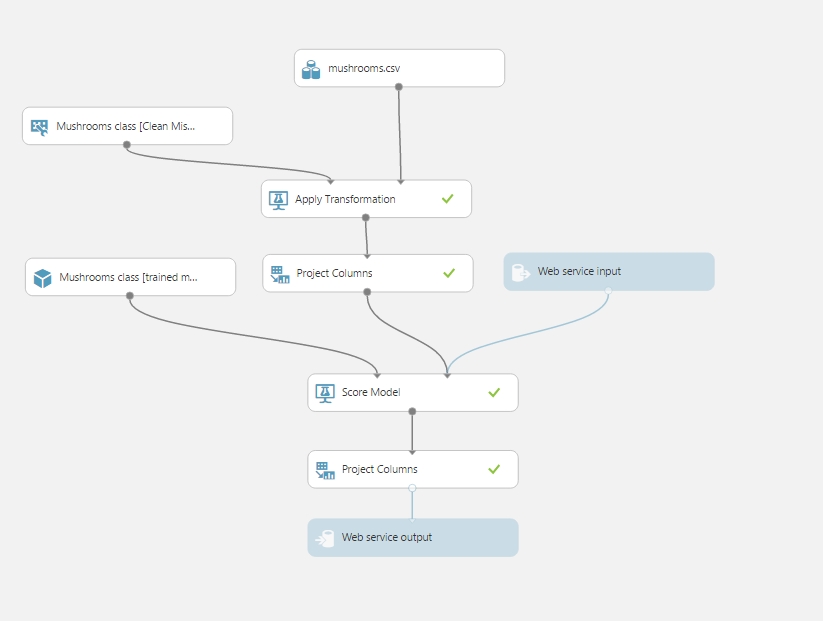
Two-Class Classification (Gombák adataiból meghatározni, hogy éppen az amint találtunk ehető-e vagy mérgező-e):