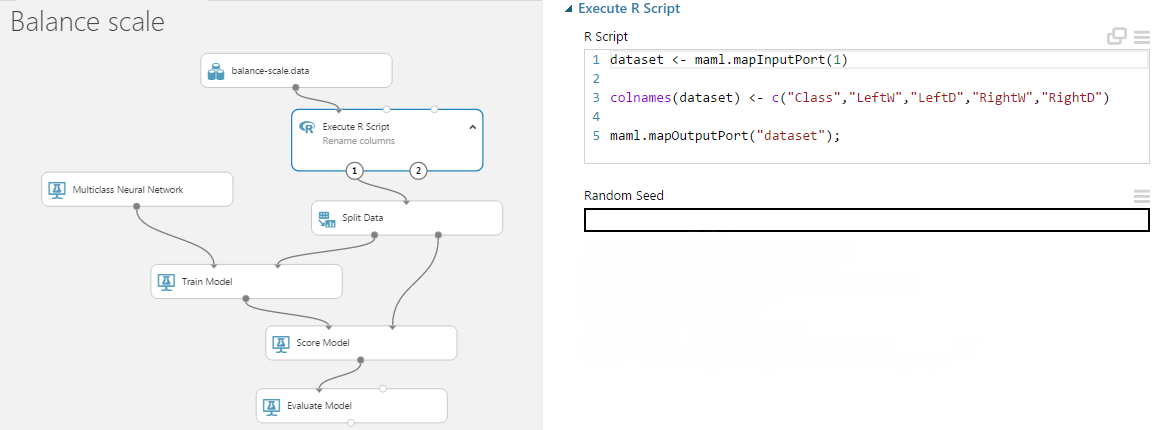
Az előző postban eljutottam addig, hogy az adatokat kicsit módosítottam és a több osztályos tanulásból kétosztályos tanulást csináltam. Most ismét a későbbi könnyebb munka és egy kicsit az eredmények javítása céljából tovább bontottam az adathalmazt. Azaz teljesen különálló adathalmazt hoztam létre a tanuló és a teszt adatoknak. Ez azt jelenti, hogy mind a BENING és a MALIGNANT halmazból véletlenszerűen kiválasztottam 5 db sort tesztadatnak.
Birthmarks data #2 – separation
Reply
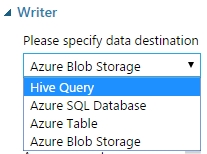 Az aktuális adathalmazunkat, vagy eredményeinket, részeredményeinket (lényegében bármit) el tudunk menteni a Writer modul segítségével. A modul a Data Input and Output csoportosítás alatt található. A modul segítségével írható Hive Query, Azure SQL Databse, Azure Table és Azure BLOB Storage.
Az aktuális adathalmazunkat, vagy eredményeinket, részeredményeinket (lényegében bármit) el tudunk menteni a Writer modul segítségével. A modul a Data Input and Output csoportosítás alatt található. A modul segítségével írható Hive Query, Azure SQL Databse, Azure Table és Azure BLOB Storage.