Tudjuk, hogy hogyan vigyünk fel adatokat az ML Studio-ba. Most dolgozzunk az adatokkal. A Studióban nagyon könnyen hozhatunk létre kísérleteket (erről már beszéltem egy korábbi bejegyzésben), egyszerű drag-n-drop módszerrel illesztjük össze a megfelelő modulokat, melyből a végén egy értelmes modell áll össze. A Studió számos előre rögzített szerszámot biztosít számunkra, legyen szó tesztelésről, adatmanipulációról vagy tanító algoritmusról. Azonban ha valamivel nem vagyunk kellőképpen megelégedve, vagy szükségünk van egy egyedi megoldásra akkor sokmindent felüldefiniálhatunk, lecserélhetjük saját megoldásunkkal, amelyeket R vagy Python kódban írhatunk meg.
A munka elkezdéséhez csupán két dologra lesz szükség:
- egy böngészőre (hiszen a teljes Azure ML Studió a felhőben fut, nincs szükségünk telepítésre vagy egyéb lokális konfigurációkra).
- és a tanító adatokra (hiszen adatok nélkül nem sok értelme van bármit is csinálni)
Tehát, egy kísérlet elkészítésének néhány nagyon egyszerű lépése van, ezek alapján fogunk most felépíteni egy lineáris regressziós modellt:
- adatbevitel
- adat előfeldolgozás
- funkciók definiálása
- tanító algoritmus választása és alkalmazása
- jóslás (lényegében a modell értékelése és tesztelése)
1. Adatbevitel
Néhány előre definiált teszt adat is megtalálható a Studióban, azonban mi magunk is könnyen importálhatunk lényegében tetszőleges mennyiségű adatot. (Megjegyzem, ha valaki az R studió egy objektumát vagy munkaterületét, tehát egy .RData állományt szeretne importálni, akkor érdemes úgy is kipróbálni ha valamiért nem megy, hogy először egy sima .zip állományt készít belőle. Nekem nem fogadta el valamiért az .RData fájlt. Szimplán egy tömörítés után minden gond nélkül importálva lett.)
Bővebb információ az adatok importálásáról.
Kezdjünk egy új kísérletet és kattintsunk a +NEW gombra a bal oldal alján, majd a felgördülő menüből válasszuk a bal oldalon található EXPERIMENT menüt. Itt egy újabb felsorolás fogad minket, ahol a Microsoft által közzétett minták, előre elkészített kísérletek indíthatóak el. Nekünk most egy üres, azaz egy Blank Experiment kell.
Kaptunk egy új felületet (és itt már láthatjuk a középső fő ablakban, hogy a kísérlet létre lett hozva a jelenlegi dátumra), a bal oldalon található menüsávban most az összes elérhető eszközt látjuk csoportosítva (adatok, algoritmusok, stb). A középső felület maga a munkaterület, ahova majd az egyes modulokat fogjuk egyszerű mozdulatokkal behúzni. Végül a jobb oldalon található egy tulajdonságok sáv, amely az aktuálisan kijelöl modulra értelmezett hasznos dolgokat fogja mutatni. (Természetesen az alsó menü továbbra, ahogyan már megszoktuk, a főbb vezérlési pontokat tartalmazza, azaz mentés, futtatás, publish, stb.).
A folytatáshoz a bal oldali menüben a kereső sávba be kell gépelni azt a modult, amit éppen keresünk és használni szeretnénk, vagy megkereshetjük a csoportosított listában is. Én most egy újonnan létrehozott OrvosiKerdoiv nevű adathalmazomat kerestem meg (ez egy GenericCSV with header állomány). Miután megtaláltam amit kerestem, csak megfogom és a munkaterületre húzom, és kész is a hozzáadás.
(Pro. tipp #1: Az egyes modulokra ha duplán kattintunk, akkor lehet leírást adni hozzájuk, ez egy közel száz modulból álló kísérletnél már jelentősen könnyítheti az átláthatóságot.)
És itt a lehetőség, hogy akkor megnézzük az előzőleg ígért HDInsight adatok használatát.
A helyzet az, hogy egy HDInsight cluster létrehozásához (vagyis egy részéhez) némi euró szükséges, így nem ástam magam túlzottan bele, hogy valóban létrehozzak egy clustert példaadatokkal, így marad az, hogy utána olvastam és elhisszük, hogy ez így működik 🙂 Azután ha rákattintunk a Reader modulra, a bal oldali jellemző sávban megjelenik néhány kitöltendő mező. Alapvetően itt választhatjuk ki, hogy a Reader honnan szerezze be az adatokat.
A történet egyszerű, ugyanígy a keresőbe a bal oldalon beírjuk, hogy nekünk egy Reader kell (mert ezen keresztül tudunk elérni bármilyen online adatforrást, nem csak HDInsight-ot) majd behúzzuk azt a munkaterületre.
A modulon keresztül elérhetőek adatok:
- egy URL címről
- Hive lekérdezés
- Azure SQL adatbázisból
- Azure táblából
- Azure Blob tárházból
- vagy egy Data Feed Provider-ről (ezt nem fordítom le mert jól hangzik 😀 )

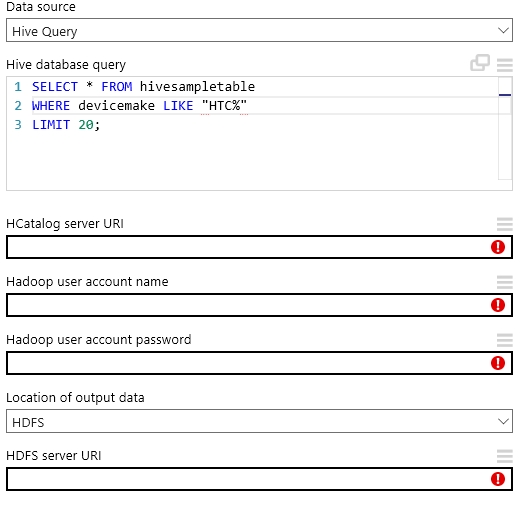
A legtöbb esetben motorikusan ugyanazokat a dolgokat kell beállítanunk, hogy a Reader megfelelően működjön. Ezek hitelesítő adatok, forrás címek és adattípus meghatározások többnyire. Jelen esetben nézzük mi kell egy HDInsight Hive tábla adatainak eléréséhez.
Megadhatjuk, hogy pontosan milyen adatokra van szükségünk. Ezt egyszerűen egy Hive lekérdezéssel tehetjük meg ami meglepő módon egy egyszerű vagy egész nyakatekert SQL parancs. Majd néhány olyan információra lesz szükség, ami biztosítja a Readernek az adatok elérését (azaz elérési URL és hitelesítő adatok). Meg kell mondjuk,. hogy az output adatokat hol találjuk, a clusterben vagy az Azure tárolja őket. Az első esetben csak egy elérési címet kell pluszba megadnunk a második esetben viszont szükséges még egy hitelesítés és egy konténer név az Azure felé.
Ha mindent beállítottunk, akkor a Reader elvégzi a dolgát, és a modul output ugyanúgy fog viselkedni mint egy mentett adathalmaz. Megnézhetjük a megkapott adatokat a Vizualize segítségével, vagy menthetjük is az adatokat egy helyi adathalmazként vagy ugyanúgy a kimenetet beköthetjük a kísérletünkbe, így a távoli adatváltozás hatással lesz a kísérletünkre is.
Visszakanyarodom az elkezdett, már meglévő adathalmazhoz.
Ha szeretnénk megtudni, hogy pontosan mi is van a behúzott adathalmazunkban, akkor a modul outputjára kattintva (Az egyes feliratú kör) megjelenik egy menü, ahol válasszuk a Vizualize opciót.
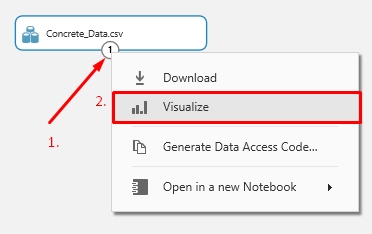
Egy modális ablakban láthatjuk, hogy mi és hogyan szerepel az adathalmazban. Az egyes oszlopra kattintva a bal oldali sávban néhány statisztikai információt találunk és egy vizualizációs felületet, ahol lehetőségünk van egy grafikonon az egyes oszlopok ábrázolva összehasonlítani.
2. Adat előfeldolgozás
Erre a lépésre azért van szükség, mert szükség van. Az indok egyszerű, jellemzően egy gépi tanulást használó alkalmazásban igen nagy méretű adathalmazzal kell dolgozzunk, ilyen hatalmas méretű adathalmazban nem kizárt, hogy hiányzik néhány mező értéke vagy hasonló jelentőségű hiba van az adatban. Ahhoz hogy a későbbi folyamatokban ne zavarjon meg semmit, ezeket javítani vagy csak ellenőrizni kell.
Itt a legegyszerűbb megoldást választottam, kitörlöm azokat a sorokat amelyekben van hiányzó adat (remélhetőleg az adatok igen kis százalékáról van szó, amely nem fogja nagyban befolyásolni a futást).
HASZNOS INFORMÁCIÓ: Ugyanakkor érdemes azokat az oszlopokat teljes mértékben törölni amelyekben az “adatvesztés” százaléka túl nagy.
Ilyen műveletek elvégzésének a lehetőségét az adat transzformáló modulok teszik lehetővé. Érdemes ezek között böngészni, mert számos manipulálási lehetőséget biztosít a Stúdió.
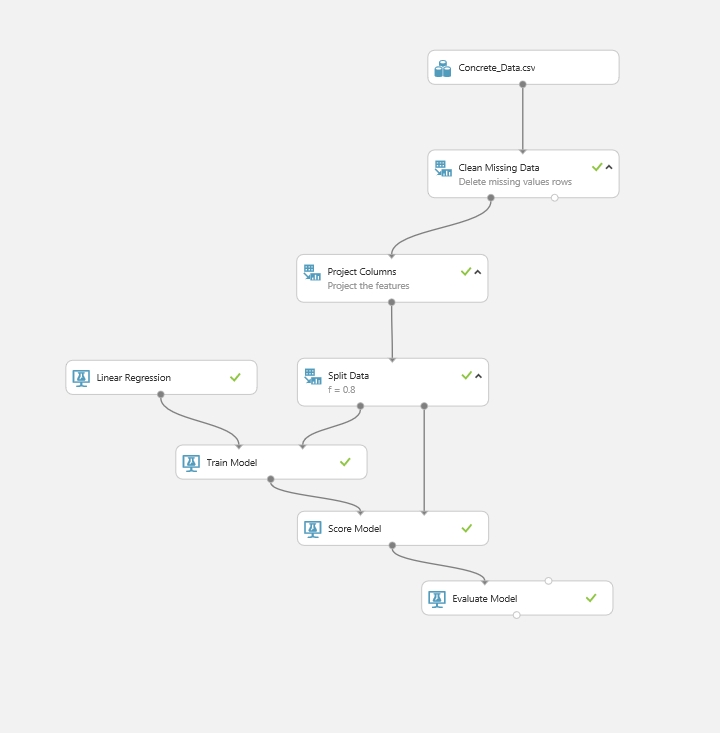
Tehát, keressük meg a Project Columns modult. Ez a modul segít nekünk majd abban, hogy meghatározzuk, hogy mely oszlopok szerepeljenek vagy ne szerepeljenek a modellben. A munkaterületre helyezés után a már ott lévő Concrete_data adathalmaz outputját össze kell kötni a ennek a modulnak az inputjával.
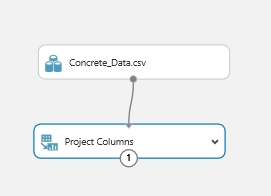
Ha ez megvan, ki lehet jelölni, hogy melyik oszlopok kellenek a modellünkbe. Ezt úgy tehetjük meg, hogy a Project Columns modulra kattintunk, majd a bal oldali tulajdonságok sávban a Lunch Column Selector gombra kattintunk.
A Begin With résznél a legördülő listában az All columns opciót válasszuk, mert minden oszlopra szükségünk lesz, kivéve majd azokra amiket a következő sorban megadunk. Tehát a következő sorban az első legördülő menüben válasszuk az Exclude opciót, tehát, hogy mi nem kell majd, és válasszuk ki hogy mi alapján szűrjünk lényegében (nekem teljesen jó az oszlop neve). Majd adjuk meg azokat az oszlopokat amelyekre nincs szükségünk. Mivel most a jelentősen “sérült” oszlopokat szeretnénk eltüntetni (persze itt bármi alapján dönthetek úgy, hogy az az oszlop ne legyen benne a modellben) ezért a saját adathalmazunkat ismerve válasszuk ki azt az oszlopot amelyikre ez igaz. (nálam a nehez oszlop lesz a nyertes) Ezt úgy tudjuk hozzáadni, hogy a beviteli boxra kattintunk, ahol majd megjelenik egy legördülő lista, kijelöljük ami kell és már hozzá is adva. Ha ez megvan ez a rész ennyi, és valami ilyet kell lássunk:

Azaz azonnal látjuk, hogy a modellben minden oszlop benne van kivéve egyet, ez a Age (day) oszlop (mondjuk, de ezt csak a példa miatt mondom, egyébként rendben van az adathalmaz).
{kind=link}
Ezt csak megmutattam, a jelenlegi megoldásomba nincs rá szükség, el is távolítom a kísérletből.
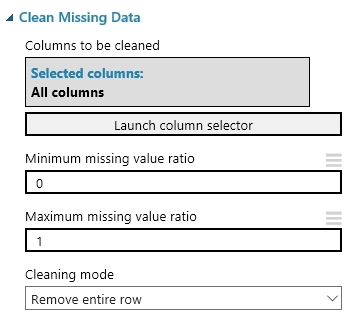
Most a hiányzó adatokkal kell foglalkoznunk. Erre azt mondtam, hogy amelyik sorban van hiányzó adat, az teljes mértékben tűnjön el a modellből. Ehhez egy újabb adatmanipulációs modul kell, amely a Clean Missing Data.
A CMD modul inputja az adathalmazunk outputja lesz (vagy ha alkalmazunk előtte Project Columns modult akkor annak az aoutputja). Az összekötés után a CMD modul tulajdonságainál megadjuk, hogy mit is csináljon pontosan. A Cleaning Mode opció alatt van néhány lehetőség, hogy mi történjen akkor ha hiányzó adatra bukkanunk, pl. helyettesítés a mediánnal, vagy az átlaggal, az egész oszlop vagy sor törlés, stb. Tehát nekem a Remove entire row kell. Itt is meg lehet adni, hogy mely oszlopokat érintse a hiányzó adatok keresése, nyilván most mindent átnézetünk tehát az marad All columns a Columns to be cleaned opció alatt (ha máshogy szeretnénk, akkor csak ismét a column selectort kell használnunk).
Ezek után akár egy futtatást el is végezhetünk a kísérleten, így a felépített modulok mind elvégzik a dolgukat és a végén megtekinthetjük az újonnan kapott megtisztított adathalmazunkat a Vizualize segítségével, amit most a CMD modul egyik ouputjára kattintva keressünk most. Tehát futtatás után nálam valahogy így néz ki a dolog (a zöld pipa minden modul sarkában azt jelzi h a futás sikeresen lezajlott):
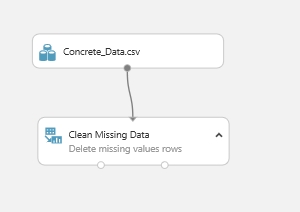
Ezzel alapvető hibákat küszöböltünk ki az adathalmazunkban, ezeket elvégezni minden esetben célszerű. Ha ezek után máshol is akarjuk használni ezt az adathalmazt akkor egyszerűen csak a CMD outpujára kattintva elmenthetjük az egészet egy új adathalmazként amiben már nem szerepel semmi hiányzás. Ha megvagyunk jöhet a kövi lépés.
3. Funkciók definiálása
Ez egy fontos része a kísérlet építésének, ugyanis meg kell választani azokat a jellemzőket, amik alapján majd a jóslás történik. Számos összefüggést figyelembe kell venni ahhoz, hogy a legjobb választást hozzuk meg és a legjobb eredményt kapjuk a modelltől. Ezért is jó az Azure ML Studio, megvan az adathalmazunk, felépítünk egy kísérletet és néhány kattintással meg tudjuk változtatni a modellben résztvevő jellemzőket, így nagyon gyorsan egy új kísérleti futtatást végezhetünk el. Ahhoz hogy megtaláljuk az optimális jellemzőhalmazt, sok kísérletezés kell, és tudni kell milyen problémát akarunk megoldani, mire akarjuk használni…
Tehát válasszuk ki a szükséges jellemzőket a modellhez. Ehhez alkalmazzunk egy Project Column modult. Adjuk a munkaterülethez és a Clean Missing Data egyik kimenetét kössük rá a bemenetére, majd végezzük el itt is a megfelelő oszlopok kiválasztását a Properties->Lunch column selector segítségével.
Itt most nem eltávolítani szeretnénk oszlopok mint az előbb, hanem csupán néhányat kiválasztani. Ezért a Begin with opcióhoz a No columns opciót választottam, majd nem Exclude name Include kell az egyes oszlopokra column name alapján. Hozzáadjuk azokat az oszlopok a listához, amikre úgy gondoljuk, hogy szükségünk van.
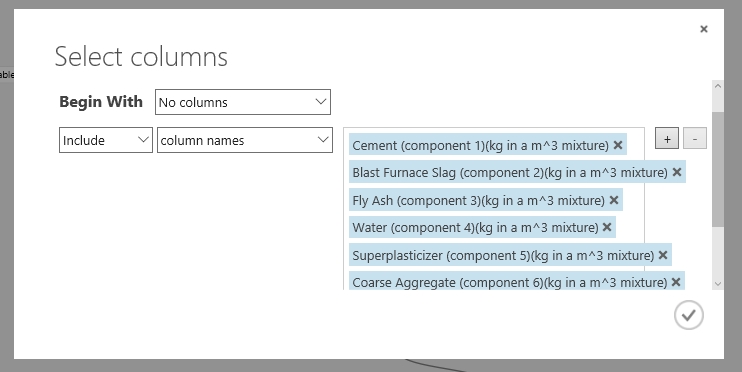
Ha ez a jellemzőválasztás nem fog megfelelőnek bizonyulni, akkor csak vissza kell jönni ehhez a modulhoz, és ezeket az oszlopokat bővíteni, lecserélni vagy törölni kell és újra futtatni a modellt.
4. Tanító algoritmus választása és alkalmazása
Itt jönnek a képbe a már tárgyalt osztályozó vagy regressziós típusú algoritmusok. Ebben a példában mint fentebb már írtam egy regressziós modellt készítünk. Ahhoz hogy tudjuk milyen is lett a dolog, a tanítás után tesztelni is kell az algoritmust. Ezért itt az adatunkat most ketté fogjuk bontani.
Az adathalmaz szétválasztásához a Split Data modul használható. Tegyük ki a munkaterületre a modult, és kössük a bemenetére a Project Column kimenetét, tehát a kiválasztott jellemzők lesznek a bemenet. A bal oldali tulajdonságok sávban tudjuk testre szabni a modult. Megadhatjuk, hogy milyen módon történjen az adatok szétválasztása, ez lehet egyszerű szétvágás, vagy akár egy kifejezés is. A Fraction of rows in the first output dataset opciónál adhatjuk meg, hogy az adatok hány százaléka legyen tanító és hány százaléka legyen tesztelési, én az adataim 80%-át szeretném tanító és 20%-át tesztelő adatnak hagyni. Itt egy 0 és 1 közé eső szám kell természetesen. Megadhatunk egy véletlen opciót is, hogy az alapján döntse el melyik sorok fognak az egyes halmazokhoz tartozni. Végül megadhatjuk, hogy hol kezdődjön a a vágás.
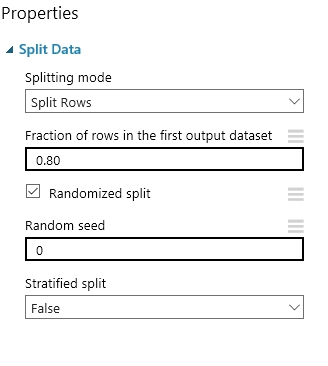
Ha ez megvan nem árt ha futtatunk egyet a kísérleten, hogy a modulok megkapják a neki szánt adatokat.
Most pedig be kell vetni egy tanító algoritmust, hiszen megvan a tanító adathalmazunk. A tanító algoritmusok a bal oldali menüsben a Machine Learning alatt találhatóak. Ez még további alcsoportokra van bontva, van értékelő, tanító, pontozó és inicializáló algoritmus csoport. Ezekről majd egy későbbi bejegyzésben bővebben. Most nekünk az Initalize Model alcsoportból a Regression típusú algoritmusok közül a Linear Regression kerül a munkaterületre. (Azért már megjegyzem, hogy nagyon sok alap beépített algoritmus található az egyes kategóriákban, el lehet böngészni az időt. A regressziós algoritmusokon belül is már több olyan névvel is találkozunk ami esetleg egyetemi tanulmányok alatt néhány kurzuson előfordult, ilyen pl. A Decision Forest, Neural Network vagy a Poisson regressziós algoritmusok.)
Ha hozzáadtuk a munkaterülethez a regressziós algoritmusunkat, akkor ezt még nem kell és nem is tudjuk hova bekötni, illetve ennek a modulnak nincs bemeneti portja. Ez a modul az algoritmust szolgáltatja, amit egy újabb modul segítségével össze kell rakni az adatokkal. Ez a modul a Train Model lesz, azaz a tanító modul. Ha a munkaterülethez adtuk, akkor kössük a Linear Regression modul kimenetét a Train Model bal oldali bemenetére (ez fontos, mert a jobb oldali szigorúan az adathalmaznak kell kerülnie), és a jobb oldali bemenetéhez pedig akkor kössük a Split Data modul egyik kimenetét. Ha megvagyunk akkor megint jön egy kis konfigurálás. Meg kell határozni, hogy a model mit akarjon megjósolni, mi legyen a kimenet. Ehhez menjünk a Train Model tulajdonságaihoz és indítsuk el a Launch column selector-t, ahol a már ismert módon kijelöljük, hogy egy oszlopot mi alapján szeretnénk hozzáadni a kiválasztáshoz, és adjuk meg a jósolni kívánt oszlop(ok) nevét (Itt egyértelműen azok közül választhatunk amik meg vannak adva a második Project Column modulban.). Ja igen! Mire ide jutunk már nem árt ha tudjuk, hogy mit is akarunk jósoltatni, mire vagyunk kíváncsiak, vagyis jóval előtte, mert a jellemzők kiválasztását is nagyban befolyásolja. Én most arra vagyok kíváncsi hogy egy beton nyomószilárdsága mekkora.
Ha minden megvan akkor valahogy így néz ki a dolog az én verzióm szerint:
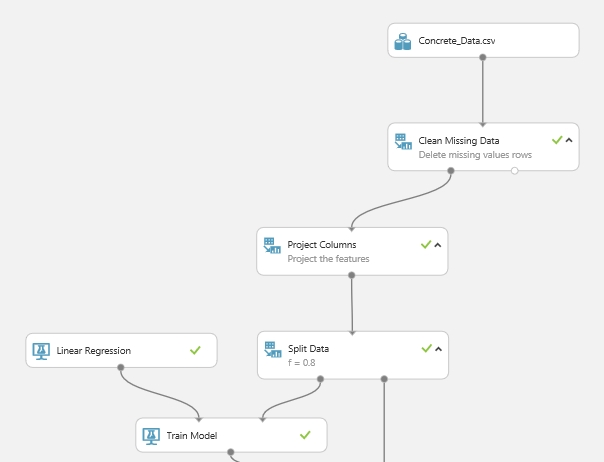
5. Jóslás
Végül jöhet amire vártunk, és végigszenvedtük ezt a hosszú leírást. Ez pedig, hogy “pontozzuk” az adathalmazunkat a megmaradt 20% alapján amit a split után meghagytunk.
Ehhez keressük meg a Score Model modult, és adjuk a munkaterülethez. A bekötés egyszerű, mert a bal oldali bemenetére kell kötni a kiképzett adathalmazt, azaz a Train Model kimenetét, a jobb oldali bemenetéhez pedig a Split Data jobb oldali (megmaradt 20%) kimenetét. Ha itt futtatjuk a kísérletet, akkor a Score Model kimenetét a Vizualize segítségével megnézhetjük mi lett az eredmény (A jósolt érték az utolsó oszlopban lesz, Scored label néven.).
Ha pontoztuk a megoldásunkat, akkor már csak ki kell értékelni, hogy tökéletes legyen a vége a dolognak. Ehhez fogjuk használni az Evaluate Model modullt. Adjuk a munkaterülethez, és kössük a bal/jobb oldali bemenetére a Score Model kimenetét. Az Evaluate Model-nek két bemenete van, ez azért jó, mert nem csak egyetlen forrást képes kiértékelni, hanem két különböző forrást is képes összehasonlítani.
Ha futtatjuk a kísérletet akkor a végén az Evaulate Model kimenetén megnézhetjük, hogy mi lett a kiértékelés. Ha úgy gondoljuk ez nekünk jó, akkor már mehet is a Set up web service és használatba is vehetjük a megadott API és kulcsok segítségével a modellünket.
6. plusz infó, lehetőségek…
Tehát, adatmanipulálásról bővebben:
Nyilván azzal tisztában vagyunk, hogy bármi megeshet, és szükség lehet az adatok módosítására, bővítésére vagy tisztítására (erre már van is példa fentebb).
Lehetőségeink tárháza:
 Add Columns: A modulnak két bemenete és egy kimenete van, mindegyik egy adathalmazt vár el vagy ad vissza. Az egyik bemeneti adathalmaz egy oszlophalmazát hozzárendeli a másik adathalmazhoz és ezt adja vissza az outputon.
Add Columns: A modulnak két bemenete és egy kimenete van, mindegyik egy adathalmazt vár el vagy ad vissza. Az egyik bemeneti adathalmaz egy oszlophalmazát hozzárendeli a másik adathalmazhoz és ezt adja vissza az outputon.
- Add Rows: A helyzet ugyanaz a be és kimeneteket illetően, csak itt lényegében egymás után fűzi a két adathalmaz sorait.
- Apply SQL Tranformation: Három bemeneti táblát köthetünk rá a modulra (természetesen aztán a modul eredménye egy másik ugyanilyen modulba beköthető és fokozhatjuk a dolgokat 😀 ), amelyeken aztán tetszés szerint bármilyen SQL lekérdezést, műveletet végrehajthatunk, aminek az eredményét a kimenetre egy új adathalmazként ad vissza.
- Clean Missing Data: már fentebb láttuk, beszéltem róla.
- Convert to Indicator Values: kijelölt oszlopokban a kategórikus értékeket jelzőértékekre konvertálja. Ki és bemenet egy adathalmaz.
- Group Categorical Values: Több kategóriát csoportosít össze egy új kategóriába. A ki és bemenet itt is egy-egy adathalmaz.
- Join Data: összekapcsol két adathalmazt kijelölt kulcsok alapján. Lényegében külső kulcsok használata. Ki és bemenetek adathalmazos megint csak.
- Metadata Editor: Magáért beszél, metainformációk szerkesztése.
- Project Columns: a fenti példából ez is ismerős, használattal együtt.
- Remove Duplicated Rows: A neve ennek is egyértelmű, a duplikált sorokat távolítja el az adathalmazból. Ki és bemenet adathalmaz.
- SMOTE: Megkeresi azokat az adatokat amelyek nagyon kicsi az előfordulási száma, és feljavítja ezt az arányt, hogy egyenlő mértékben legyenek képesek a modellünket befolyásolni a többi adattal.
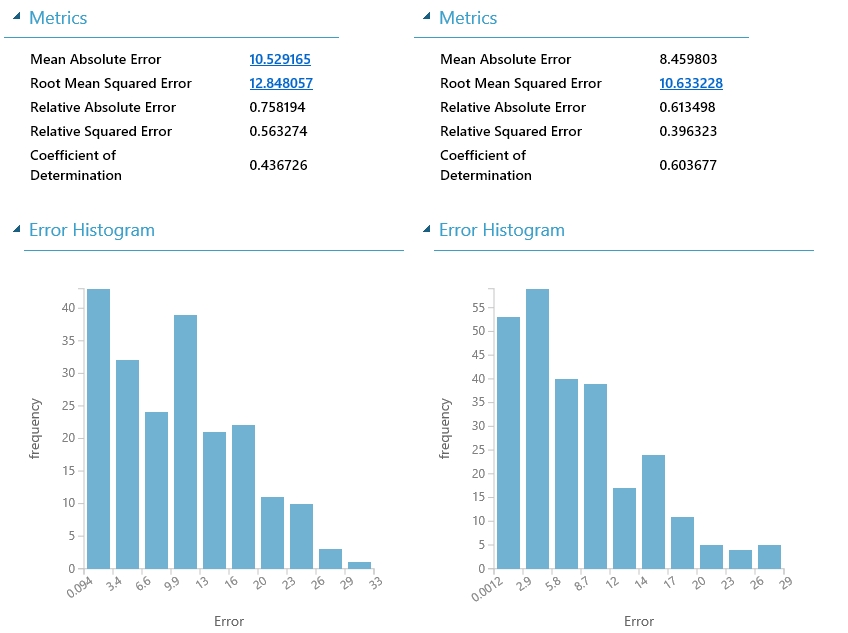
Példa a modell kiértékelések összehasonlítására: a fenti példa mellé egy ugyanazt a lineáris regressziót használó algoritmust készítettem, csupán itt a jellemzőket nem manuálisan a Project Column-al választottam ki, hanem a Train Model helyett alkalmazott Sweep Parameters tanító modell végzi az ehhez tartozó nehézségeket helyettem. Ennek a modulnak ugyanúgy megadjuk, hogy melyik tanító algoritmust akarjuk használni, majd a többi bemenetére szintén hasonló módon egy adathalmaz kerül, illetve egy ellenőrző adathalmaz. Ezt hasonlóan oldottam meg mint kollégám az előző cikkében, az adathalmazomat kétszer vágtam szét.
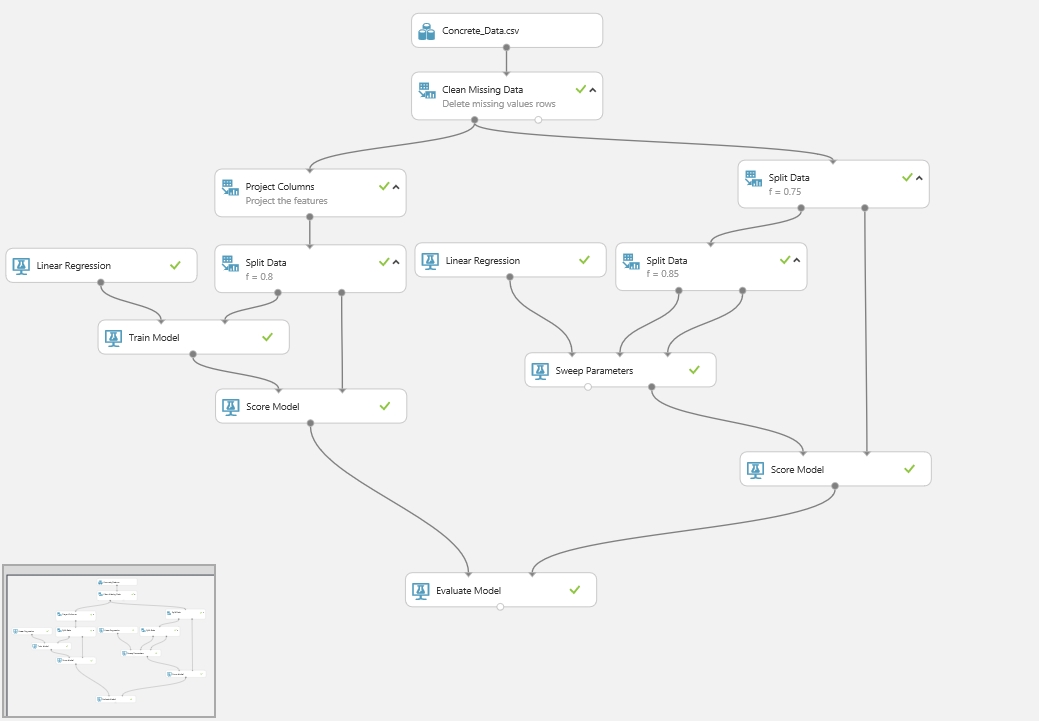
Végül az Evaulate egybeilleszti a két oldal eredményét és könnyen láthatjuk mi is a helyzet, melyik megoldás a jobb.