
 A Normalize Data modul segítségével az adatainkat azonos volumenűre hozhatjuk. Erre akkor van szükség, ha nagyságrendbeli különbségek vannak köztük. A kisebb skálájú adatokat kevésbé veszik fontosnak az algoritmusok, hiszen ott jóval kisebb eltérés van, így hajlamosak szinte „megfeledkezni” róluk. A normalizálással viszont azonos mértékűre hozhatjuk az egyes adatokat, így azonos lesz a „súlyuk” is.
A Normalize Data modul segítségével az adatainkat azonos volumenűre hozhatjuk. Erre akkor van szükség, ha nagyságrendbeli különbségek vannak köztük. A kisebb skálájú adatokat kevésbé veszik fontosnak az algoritmusok, hiszen ott jóval kisebb eltérés van, így hajlamosak szinte „megfeledkezni” róluk. A normalizálással viszont azonos mértékűre hozhatjuk az egyes adatokat, így azonos lesz a „súlyuk” is.
Több matematikai függvény is a rendelkezésünkre áll:
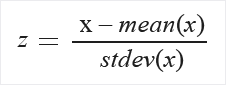 ZScore:
ZScore:
Minden oszlopnak külön kiszámolja az átlagát és a szórását, majd ez alapján normalizál. A végeredménynek 0 lesz az átlaga és 1 a szórása.
MinMax:
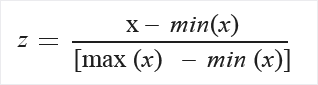 Lineárisan újraskáláz minden vonást 0 és 1 közé. A minimum érték lesz a nulla, és a maximum az 1.
Lineárisan újraskáláz minden vonást 0 és 1 közé. A minimum érték lesz a nulla, és a maximum az 1.
Logistic: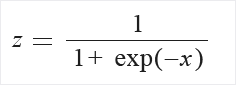
A következő formulával standardizál:
LogNormal:
A mű és a delta az empirikus eloszlás  paraméterei, amit minden oszlopra külön a maximum likelihood módszerrel közelít.
paraméterei, amit minden oszlopra külön a maximum likelihood módszerrel közelít.
Tanh: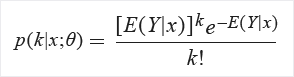
Minden értéket hiperbolikus tangenssé konvertál ezzel a formulával:
Egy modul csak egy módszert tud alkalmazni, ha egyes oszlopokat más-más algoritmussal szeretnénk normalizálni, akkor több példányt kell létrehoznunk, és mindegyikben csak a kívánt oszlopokat kell kijelölni.
A Split Data egy adathalmazt vár, és kimenete két darab adathalmaz, amiket szétválasztott. Akkor szoktuk használni, ha nem a teljes forrást szeretnénk felhasználni, csak egy bizonyos részét. Tipikusan a tanuló, teszt és a validációs halmazt szoktuk leválasztani vele.
Jelenleg 4 metódus érhető el a szétválasztáshoz:
Split rows:
A megadott százalékban 2 felé bontja az adathalmazt. Lehet teljesen véletlenszerűen, vagy akár megadhatunk egy oszlopot, ami szerint egyenletesen osztja el két részre az adatokat a program. Folytonos változó mentén természetesen nem lehet bontani, sőt, túlzottan sok egyedi értéket tartalmazó oszlop mentén sem érdemes.
Recommender Split:
Az ajánló motoroknak ez a szétválasztási modell a legjobb, a felhasználó-termék párokat (és esetleg az értékeléseket) egyenletesen bontja szét teszt és tréning halmazra.
Regular Expression:
Egy regex segítségével bonthatjuk szét az adatokat egy oszlop alapján. Például egy termék nevét keresve az egyik halmazban lesznek azok a sorok, ahol megemlítették az adott terméket, a másikban pedig azok, ahol nem.
Az alábbi regex az IP nevű oszlopban kiszűri a 10-zel kezdődő IP címeket:
(\IP) ^[10]
Relative Expression:
Egy feltételt alkalmazhatunk egy számokat vagy dátumokat tartalmazó oszlopra. Például a vevőket kor szerint, vagy a termékeket ár szerint csoportosíthatjuk kétfelé.
A &, |, <, >, <=, >=, ==, != jelek használhatóak értelem szerint, csoportosítani azonban nem lehet zárójelekkel.
Az alábbi relatív kifejezés a 2010-nél régebbi gyártású autókat szűri ki:
\”Built_year” > 2010

A Partition and Sample modullal partíciókat hozhatunk létre, illetve mintát vehetünk az input halmazból. Utóbbi kifejezetten fontos, hiszen ezáltal lényegesen csökkenthetjük az adathalmaz méretét, megtartva az arányokat. Több forgatókönyv is elképzelhető az egységgel:
Assign to Folds:
Több partíciót készít, tipikusan a keresztvalidáció miatt hasznos. Egy ugyan ilyen modul Pick Fold módjának választásával nyerhetjük ki az egyes partíciókat.
Alapértelmezetten azonos méretű részeket kapunk, ám megadhatjuk a szétosztás mértékét is, pl:
.25, .5, .25
Kérhetjük, hogy egy sort akár több partícióban is felhasználjon, illetve egy oszlop alapján egyenletesen elosztva is kérhetjük az adatokat, hasonlóan, mint a Split modulban.
Pick Fold:
A már korábban particionált adathalmazból választ egyet, így nem kell külön adathalmazt létrehozni, ha csak egy részével szeretnénk dolgozni az összes adatnak.
Opcionálisan megadhatjuk, hogy a kiválasztott partíció komplementerét vegye, így gyakorlatilag kizártunk egy partíciót.
Sampling:
Mintát vesz az adathalmazból, a megadott százalékú részhalmazát kapjuk meg az adatoknak. Itt is lehet egy oszlop alapján egyenletes elosztást kérni, de random mód is megoldható.
Head:
A megadott darabszámú rekordot adja vissza, az input elejétől kezdve. Hasznos lehet a fejlesztés elején, majd a modell tanításánál érdemes csak áttérni a teljes adathalmazra.
Amennyiben szeretnénk egyenletes eloszlást készíteni egy oszlop alapján, akkor az oszlopnak kategorikusnak kell lennie, tehát nem lehet folytonos. Amennyiben igaz/hamis értékeket szeretnénk így felhasználni, akkor a Metadata Editorban állítsuk át kategorikusra az oszlop típusát.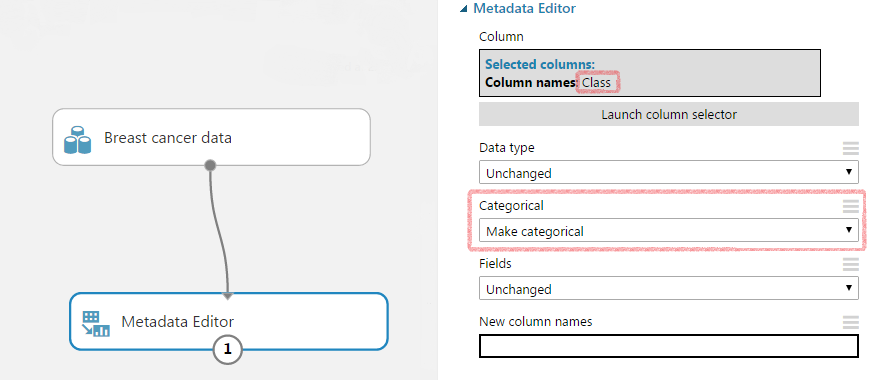
A Split Data csak két részre tudja bontani az adatokat, viszont több ilyen modul is egymás után láncolható. A Partition and Sample modul képes több részre is bontani, és felhasználni azokat. Amennyiben bármiféle mintavétel vagy partícionálás kell, és nem szükséges az összes adatot megtartani, a Partition and Sample a megfelelő modul a munkára.