
A gépi tanulásra a Microsoft megoldása az ML Studio. Teljes mértékben a felhőben futó alkalmazás, így semmiféle telepítést nem igényel, bárhonnan elérhetjük a https://studio.azureml.net címen.
Nagyban megkönnyíti a munkát, hogy az egyes modulokat csak behúzzuk a munkaasztalunkra, és összekötjük őket, nem kell időt fecsérelni sok programozásra. Rengeteg gyakran használt összetevő készen van, csak paraméterezni kell őket:
Adat bemenet/kimenet, szűrők, szétválasztók, skálázók, illetve természetesen algoritmusok osztályozásra, regresszióra, klaszterizálásra, anomáliák felfedezésére.
Körbenézhetünk a Cortana Analytics Gallery-ben, ahol kész megoldásokat találhatunk gyakori problémákra:
arcfelismerés, lemorzsolódás, kézíráselemzés…
Természetesen, ha úgy érezzük, hogy nincsen számunkra megfelelő eszköz, mert egyedi dologra van szükségünk, bővíthetjük a programunkat R és Python szkriptekkel.
A továbbiakban megnézzük, hogyan lehet egy kísérletet megcsinálni elejétől a végéig, milyen alap egységeket lehet felhasználni a sikeres jóslás érdekében.
Egy ML Projekt elkészítése:
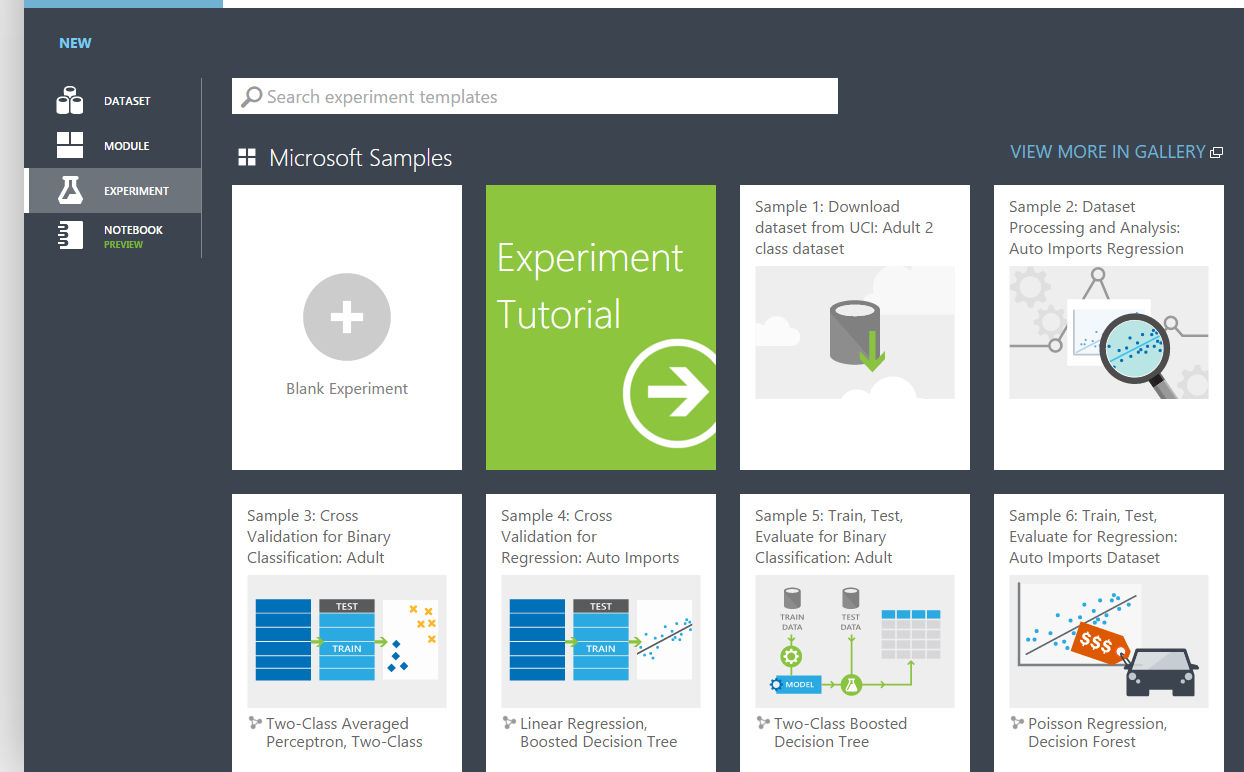
A New / Experiment / Blank Experiment-re kattintva kaphatunk egy üres munkaasztalt, amit felül elnevezhetünk kedvünkre.
Először is adatra van szükség. Rengeteg forrást támogat az ML Studio:
Megadhatunk távoli adatokat:
- Egy web URL-t, amin lehet CSV, TSV, ARFF, SVMLIGHT adat
- Egy HiveQL-t a Hadoop bejelentkezési adatok megadása után. Itt kiválaszthatjuk azt is, hogy a cluster, vagy az Azure tárolja az output adatokat.
- Azure SQL adatbázis / tábla
- Azure Blob storage – érdekes, hogy csak itt kínálja fel a program az Excel táblát, sehol máshol.
- OData (REST API)
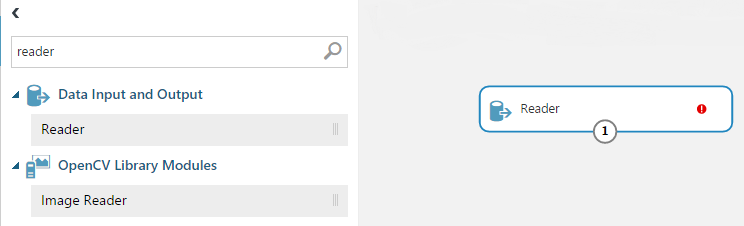 A kísérletünkben egy Reader modul beillesztésével elérhetőek a fenti távoli források. Mindössze baloldalról be kell húzni a munkaasztalra a Reader-t, és kiválasztani a forrásunkat, illetve megadni az ahhoz szükséges információkat (URL, bejelentkezési adatok, lekérdezés, stb…)
A kísérletünkben egy Reader modul beillesztésével elérhetőek a fenti távoli források. Mindössze baloldalról be kell húzni a munkaasztalra a Reader-t, és kiválasztani a forrásunkat, illetve megadni az ahhoz szükséges információkat (URL, bejelentkezési adatok, lekérdezés, stb…)
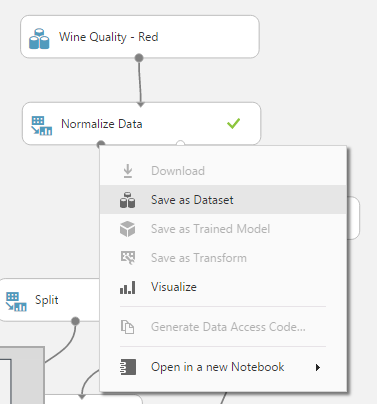
Már meglévő kísérlet (rész) eredményét is felhasználhatjuk valamelyik újabb kísérletünkben:
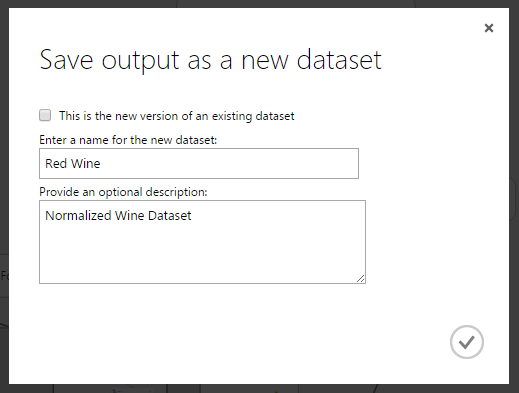
Ekkor a kívánt modul outputjára jobb egérrel kattintva kiválaszthatjuk a Save as Dataset opciót, ahol egy felugró ablakban megadhatjuk az új adathalmaz nevét és leírását. Itt szintén lehetőség van felülírni egy régebbi adathalmazt.
A saját gépünkről pedig feltölthetünk:
- vesszővel elválasztott (CSV)
- tabulátorral elválasztott (TSV)
- sima szöveg (TXT)
- Support Vector Machine (SVMLIGHT)
- WEKA fájl (ARFF)
- tömörített (ZIP)
- R Object vagy Workspace (RDATA)
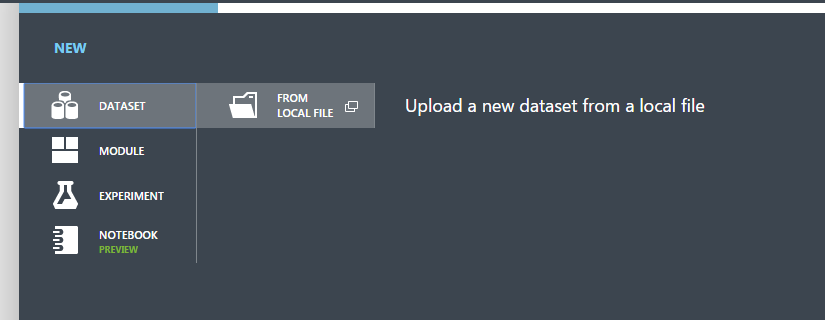
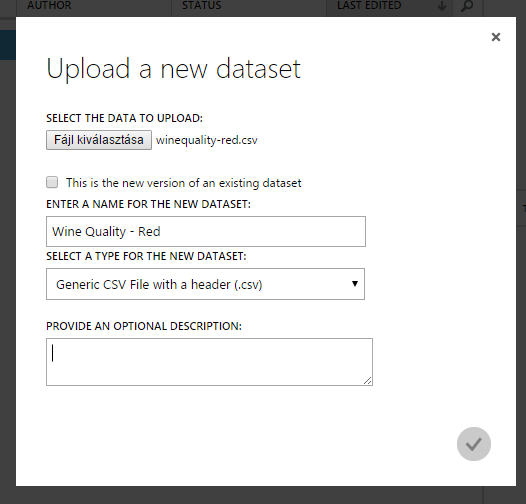 Az alul levő New / Dataset / From local file menüponttal adhatunk hozzá a számítógépünkről adatokat. Egy felugró ablakban tölthetjük fel, adhatjuk meg a nevét, típusát, és egy rövid leírást. Én az UCI Machine Learning repository-ból használtam fel a Wine Quality adatsort. Akár egy meglévő adathalmazt is frissíthetünk, ha bepipáljuk az ezt felajánló jelölőnégyzetet. A pipára kattintva elkezdi feltölteni az adatot, és amint kész, azt alul jelzi is, illetve megjelenik a listában is.
Az alul levő New / Dataset / From local file menüponttal adhatunk hozzá a számítógépünkről adatokat. Egy felugró ablakban tölthetjük fel, adhatjuk meg a nevét, típusát, és egy rövid leírást. Én az UCI Machine Learning repository-ból használtam fel a Wine Quality adatsort. Akár egy meglévő adathalmazt is frissíthetünk, ha bepipáljuk az ezt felajánló jelölőnégyzetet. A pipára kattintva elkezdi feltölteni az adatot, és amint kész, azt alul jelzi is, illetve megjelenik a listában is.
Figyeljünk rá oda, hogy a CSV fájloknál csak és kizárólag vesszőt vesz figyelembe tagolásként, a pontosvesszőt nem érti. Így ha esetleg pontosvessző az elválasztó a fájlban, akkor azokat ki kell cserélni sima vesszőre a gépünkön, még a feltöltés előtt!
 Amint feltöltöttük az adatunkat, csak be kell húzni a munkaterületre a jobb oldalról, és már használhatjuk is.
Amint feltöltöttük az adatunkat, csak be kell húzni a munkaterületre a jobb oldalról, és már használhatjuk is.
Megjegyezném, hogy lehetőségünk van akár begépelni adatokat az Enter Data nevezetű modullal. Nyilván kisebb terjedelmű próba adatokra alkalmas ez legfeljebb, hiszen ha van egy kész fájlunk, azt feltölthetjük kapásból.
Most, hogy van adatunk, vizsgáljuk azt felül:
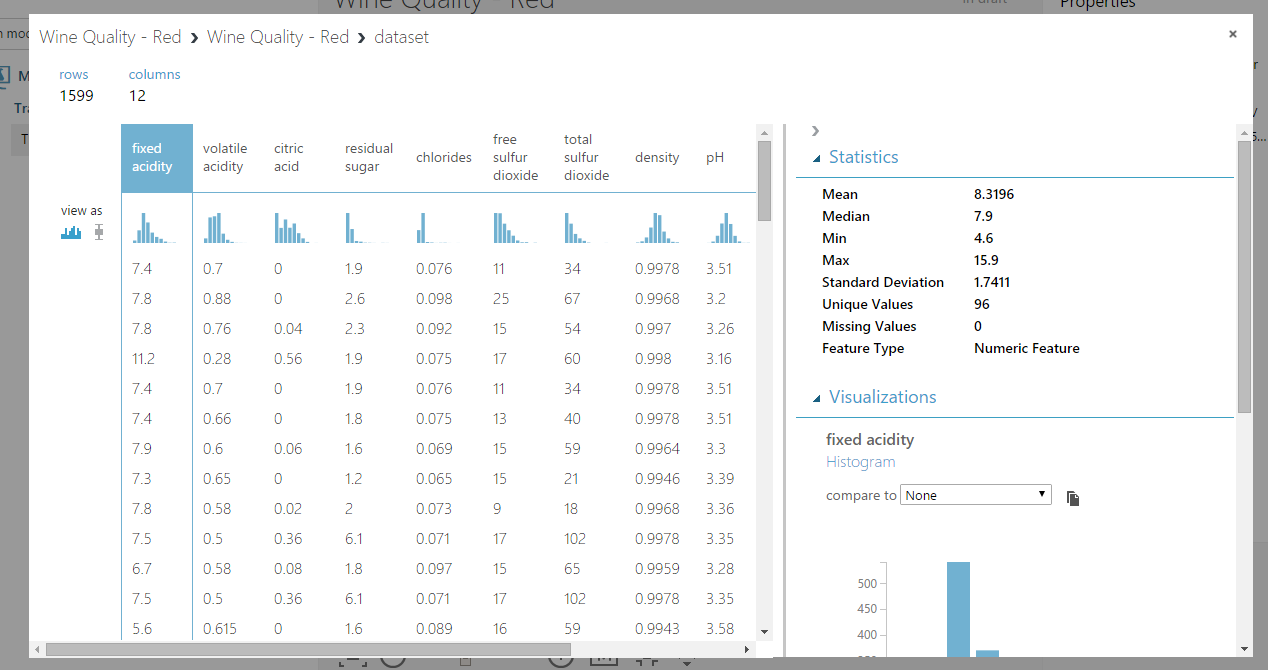
Az adathalmaz outputjára jobb egérrel kattintva a Visualize opció megmutatja nekünk az adatok különböző eloszlását, így megérthetjük, hogy mivel állunk szemben.
Szükségünk lehet az adatok megfelelő alakúra hozására:
- Azoknak a soroknak a törlése, amelyikből hiányzik valamennyi adat: a Clean missing values elemmel kiválaszthatjuk, hogy hány hiányzó adatnál törölje a sort.
- A felesleges oszlopokat törölhetjük a Project Columns segítségével. Így a nem releváns oszlopokból nem akar majd (téves) következtetéseket levonni a programunk.
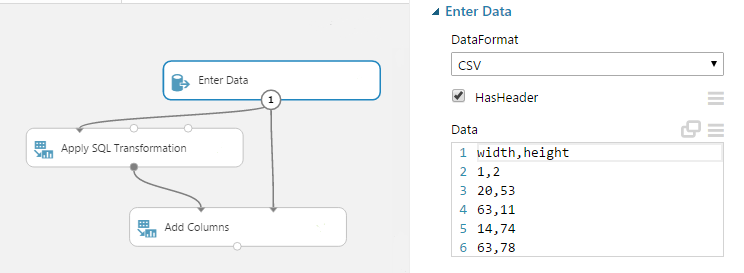
- Új oszlopokat is létrehozhatunk, például ha egy téglalap szélességét és hosszát tudjuk, de nekünk a területére van szükségünk:
 Először megadtam kézzel néhány sor adatot az Enter Data modulban
Először megadtam kézzel néhány sor adatot az Enter Data modulban- Aztán az Apply SQL Transformation modul segítségével egy egyszerű lekérdezéssel elvégeztem a szorzást:
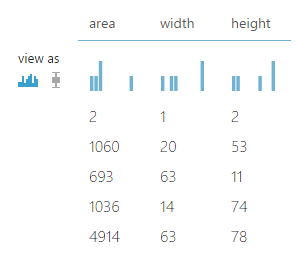
SELECT width * height AS area FROM t1; - Majd az Add Columns segítségével hozzáfűztem az eredeti adathalmazhoz az új oszlopot
- A SMOTE modul képes arra, hogy az alacsony előfordulású adatokat sokszorozza, ezáltal hangsúlyosabbá tegye azokat. Ennek tipikusan a csalás felderítésénél van jelentősége, hiszen például sok ezer biztosítási kárból csak néhány csalás van, viszont rendkívül fontos, hogy azt a néhányat felismerjük!
- A Normalize Data segítségével azonos nagyságrendűre (tipikusan -1 és 1 közé) hozhatjuk az egyes oszlopok értékeit, ezzel egyenlő súlyúak lesznek. Kiválaszthatjuk, hogy melyik oszlopokat normalizáljuk, én a minőségen kívül minden normalizálok most. (A minőség a kiszámított osztály, nyilván az marad 1-10 között.
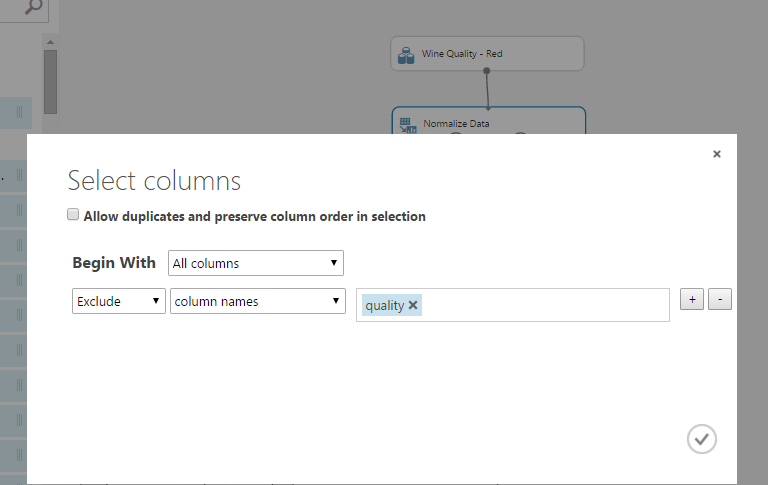
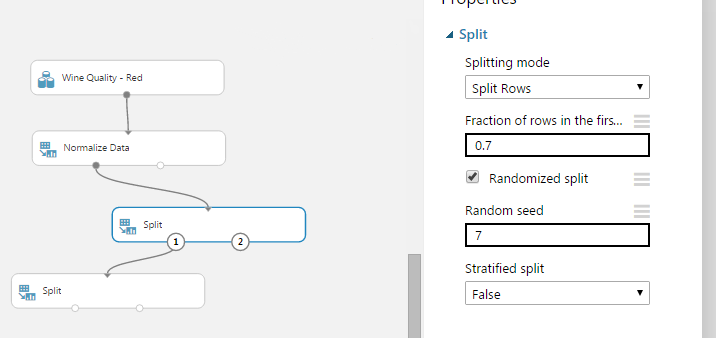
Amint feldolgoztuk az adatainkat, a Split egységgel szétválaszthatjuk kiképző és tesztelő halmazra. Én 30%-ot hagytam tesztelésre, a 70%-ot pedig további két részre osztottam.
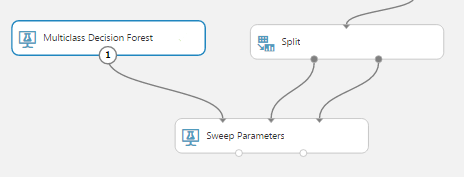
Szükségünk van egy algoritmusra, amit tanítani fogunk. A probléma típusára rákeresve könnyen felfedezhetjük, hogy milyen lehetőségeink vannak. A bor osztályozása egy multiclass probléma, így erre a kulcsszóra rákeresve egyből felajánlja a Studio a beépített algoritmusokat. Én egy döntési erdőt választottam.
Most össze kellene kötnünk az adatot az algoritmussal. Erre szolgál a Train Model. Azonban lehetőségünk van Sweep Parameters-t is használni, ami megmondja nekünk a legfontosabb oszlopokat automatikusan, így nem nekünk kell azt kitalálni. Természetesen utólag még módosíthatunk rajta, ha nem megfelelő a számunkra. Ebbe a modulba bekötöttem az algoritmust és a két adathalmazt, egyikkel tanítja, másikkal teszteli a modellt.
Ezután le kell pontoznunk a modellt a Score Model segítségével, majd értékelni azt az Evaluate Model-lel. Végül így néz ki nálam a kész projekt:
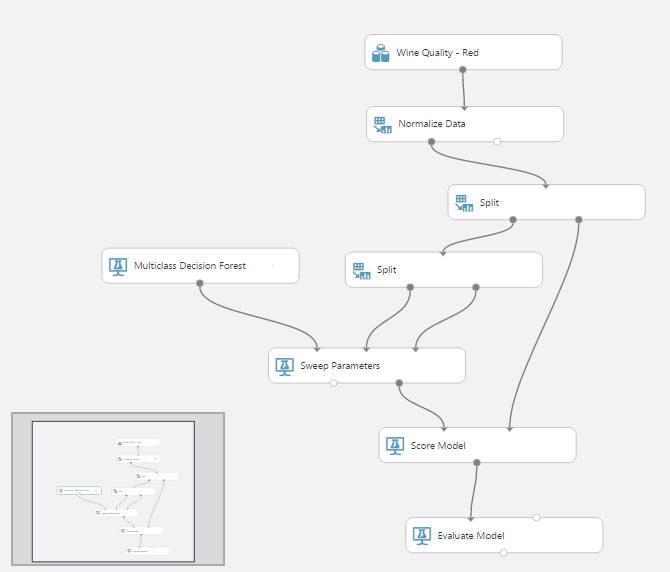
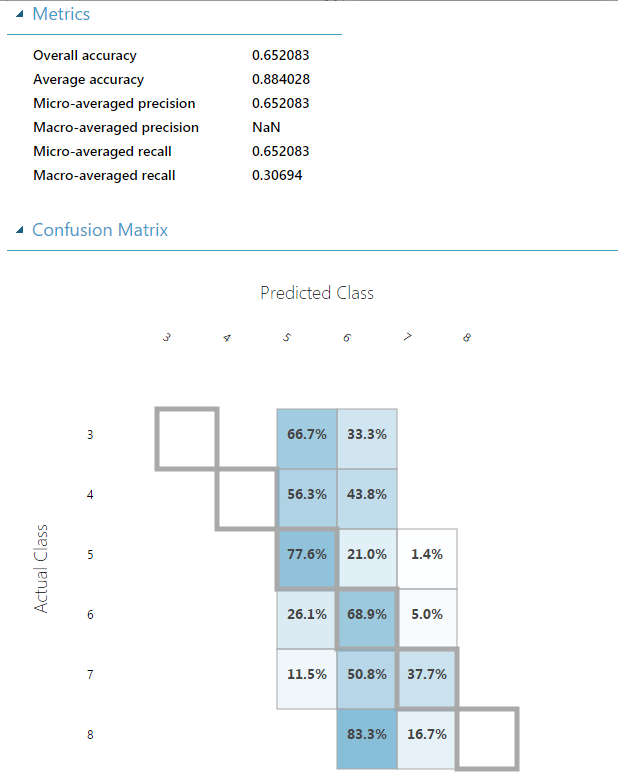 A Run gombbal lefuttathatjuk, majd ha végzett, az utolsó outputra jobb egérrel kattintva a Visualize menüpont megmutatja, hogy milyen eredményeket ért el a modellünk. Akár két modellt is beköthetünk egy Evaluate Model-be, és megmondja, hogy melyiket válasszuk.
A Run gombbal lefuttathatjuk, majd ha végzett, az utolsó outputra jobb egérrel kattintva a Visualize menüpont megmutatja, hogy milyen eredményeket ért el a modellünk. Akár két modellt is beköthetünk egy Evaluate Model-be, és megmondja, hogy melyiket válasszuk.
Amennyiben megtaláltuk a megfelelő modellt és beállításokat, és úgy érezzük, hogy szeretnénk élesben használni a programunkat, akkor a Set up web service gombbal megkapjuk a prediktív kísérletünket, amit aztán deploy-olhatunk. Ezt már a felület által kiírt API kulcsokkal el is tudjuk érni, és használatba vehetjük.