
Az előző bejegyzésemben megnéztük, hogy mi is az a Machine Learning és egy kicsit bővebben tárgyaltuk a Supervised Learning elméletét is. (Most egy kicsit gyakorlatiasabb téma jön.)
Azure Machine Learning
A Microsoft Azure szolgáltatásban az ML rendkívül egyszerűen elérhető , és nagyon egyszerűen használható az Azure ML Studio webes környezet segítségével.
A rendszer egy “fogd és vidd” (maradjunk az angol drag-and-drop kifejezésnél) módszerrel lehet használni (azaz nem igényel túlzott kódolási tudást MÉG). A drag-and-drop módszerrel lehet egy “kísérletet” felépíteni, tesztelni és telepíteni, alkalmazni a saját adatainkon. A Studio képes a szépen felépített modellünket egy webes szolgáltatásként publikálni, így az könnyen felhasználható akár mások által is.
Mit kell tenni azért, hogy elkezdjük a munkát az Azure ML Studio felületén?
Hasznos ha rendelkezünk Azure accounttal, így csak egyszerűen bejelentkezünk (ha nem rendelkezünk windows LiveID-val akkor itt van lehetőség az elkészítésre). Azonban a rendszer ingyenesen kipróbálható egy hónapig. Mind a két opció a következő linken érhető el: Azure ML Studio
Bejelentkezés után, egy hasonló GUI-nek kell megjelennie (némi bemutatkozó anyag után):
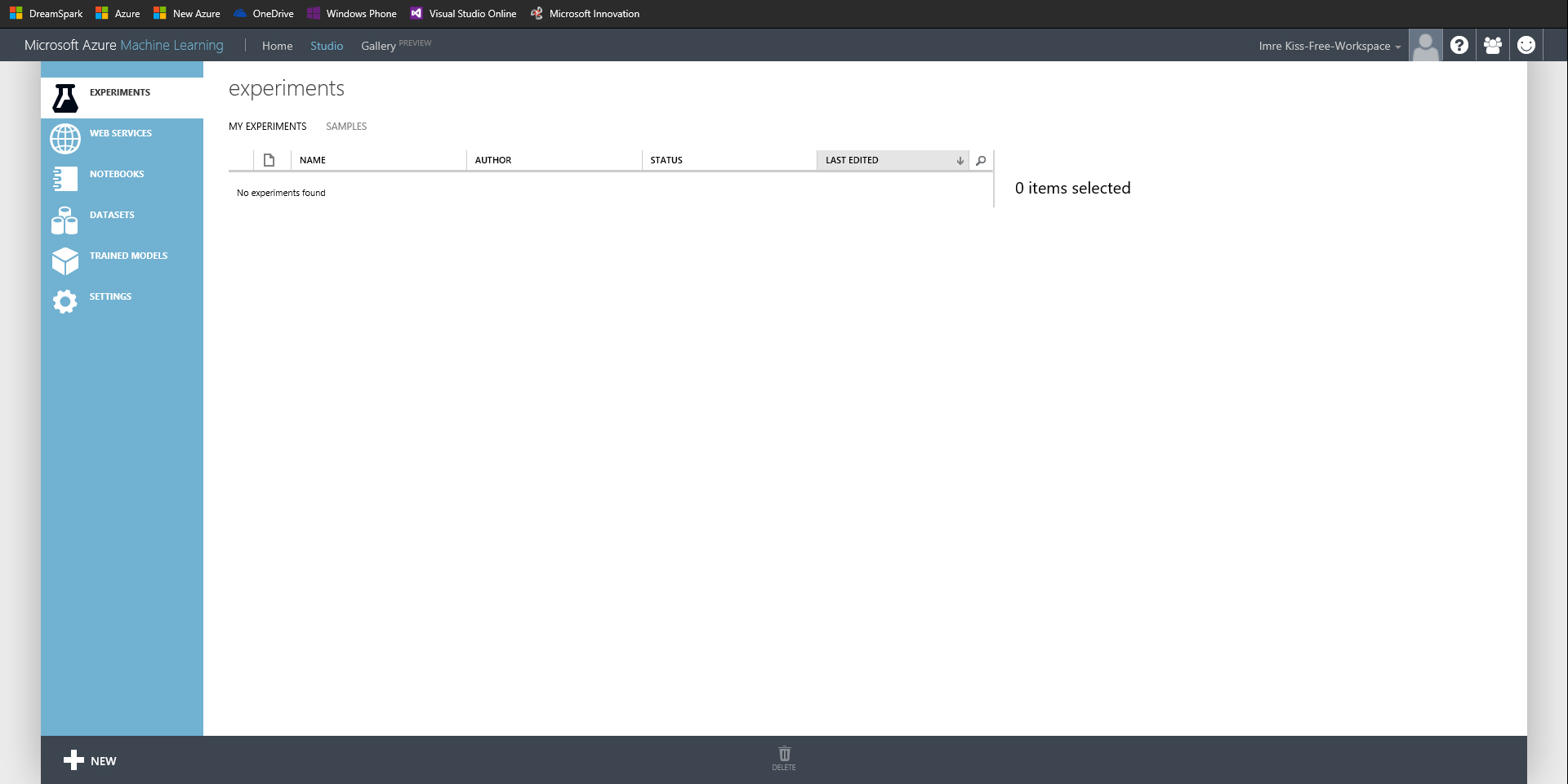
A bal oldalon található főbb menüpontok a következők:
- Experiments: “kísérletek” amik már elkészültek, futnak vagy egyszerűen csak piszkozatként el vannak mentve.
- Web Services: kísérletek amelyek már publikálva lettek.
- Datasets: adatok amelyek fel lettek töltve a Szudio-ba.
- Trained models: értelemszerűen a már “képzett” modellek.
- Settings: alapvető beállítások amelyek a felhasználói fiókot és a felhasznált forrásokat érintik.
Az oldal tetején található az accounthoz tartozó gyors menü. Itt elérhetjük a kezdőoldalt, magát a Stúdió felületét és böngészhetünk a már elkészített ML alkalmazások tárházában.
Az oldal alján mindig az aktuális műveletek érhetőek el (értelemszerűen függ a kijelölt elemtől).
Azok számára ismerős a terep, akik már korábban is használtak valamilyen Azure szolgáltatást (nem az új portálon).
A továbbiakban meg fogunk ismerkedni a Studio adta lehetőségekkel és megnézzük, hogy mit és hogyan kell használni.
Az adatok importálása!
Tanító adatbázisra van ahhoz szükség, hogy a prediktív analízis alapú fejlesztésünk használható legyen. Az Azure ML Stúdióban különböző forrásokból tölthetünk fel adatokat:
- Helyi fájlok importálása a saját merevlemezünkről egy adathalmaz modulba
- Ha a kísérletünk már fut, akkor hozzáférhetünk online adatokhoz is a Reader segítségével
- Végül használhatunk adatokat egy másik kísérletből is
Mielőtt ezeket sorban végig vesszük, fontos megemlíteni, hogy melyek azok az adatformátumok és típusok amiket az Azure ML Studio támogat.
A Stúdió arra lett tervezve, hogy olyan adatokkal lehessen benne dolgozni amelyek táblázatos vagy formázott megjelenésűek. Értem ezalatt az olyan adatokat mint pl. egyszerű szöveg tabulátorral elválasztva vagy egy adatbázisból kimentett strukturált adathalmaz. Bizonyos körülmények között használható ezektől eltérő szerkezete is.
A legjobb az ha az adatok amiket használni akarunk, “tisztán” állnak a rendelkezésünkre. Mielőtt használnánk az adatokat a Stúdióban meg kell róla győződnünk (amennyire lehetséges), hogy az esetleges szöveghibák, félrecsúszott elválasztó szimbólumok, stb. rendben vannak. Azonban az Azure ML Stúdióban is vannak olyan modulok amelyek képesek segíteni abban, hogy az adatok rendben legyen mielőtt felhasználnánk őket. Ezeknek a moduloknak a használata függ attól is, hogy milyen algoritmust fogunk használni az ML modellünkben, és attól is, hogy hogyan szeretnénk kezelni az esetleges hibákat az adatokban (pl. hiányzó mezők). Ezeket később a Data Transformation résznél fogjuk látni.
A támogatott adatformátumok a következők:
- Sima text (.txt)
- Vesszővel elválasztott értékek (CSV) fejléccel (.csv) vagy fejléc nélkül (.nh.csv)
- Tabulátorral elválasztott értékek (TSV) fejléccel (.tsv) vagy fejléc nélkül (.nh.tsv)
- Hive tábla
- SQL adatbázis tábla
- OData értékek
- SVMLight adat (.svmlight)( SVMLight definíció)
- Attribútum relációs fájl formátum (ARFF) adatok (.arff) (ARFF definíció)
- Zip fájl (.zip)
- R objektum vagy munkaterület fájl (.RData)
Ha olyan adatokat importálunk be, amik rendelkeznek metainformációval (pl. ARFF), akkor a Stúdió ezeket az információkat fogja használni, hogy meghatározza minden oszlopnak a típusát ás fejlécét.
Ha olyan adatokat importálunk, amik nem rendelkeznek metainformációval (pl. TSV, CSV), akkor a Stúdió minden oszlopból egy mintavétel segítségével megpróbálja kikövetkeztetni az adott oszlop típusát, ill. ha nem rendelkezik az adat fejléccel akkor egy alapértelmezett fejléc név kerül a helyére.
Minden egyes ilyen döntést vagy automatikus kitöltést természetesen felül lehet definiálni manuálisan is (erre ad lehetőséget a Metadata Editor)
A támogatott adattípusok a következők:
- String
- Integer
- Double
- Boolean
- DateTime
- TimeSpan
A Stúdió egy belső adattípust használ arra, hogy az adatokat mozgassa a modulok között, ennek a neve Data table.
Arra is van lehetőség, hogy a saját adatunkat explicit erre a típusra konvertáljuk, a Convert to Dataset modul segítségével. Ha van egy olyan modulunk amely elfogad ettől eltérő adatformátumot is, akkor az a háttérben fogja a konverziót végrehajtani mielőtt még az továbbításra kerülne másik modulba. Amennyiben szükséges ezt a típust vissza is konvertálhatjuk az eredeti típusra.
Hogyan importáljunk adatokat a Stúdióba
Importálás helyi merevlemezről
- Lépés: Kattintsunk az Azure ML Studio alján látható +NEW gombra.
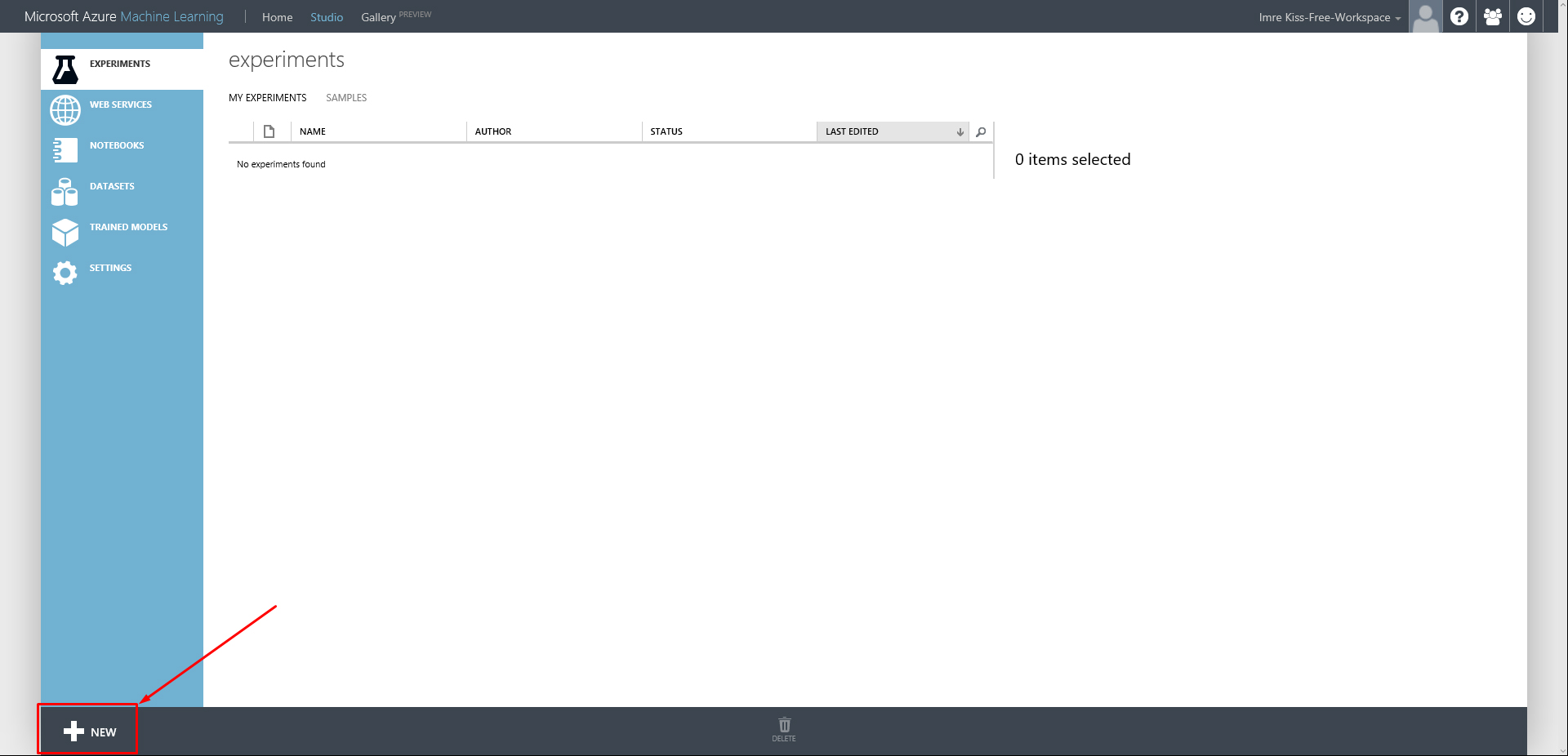
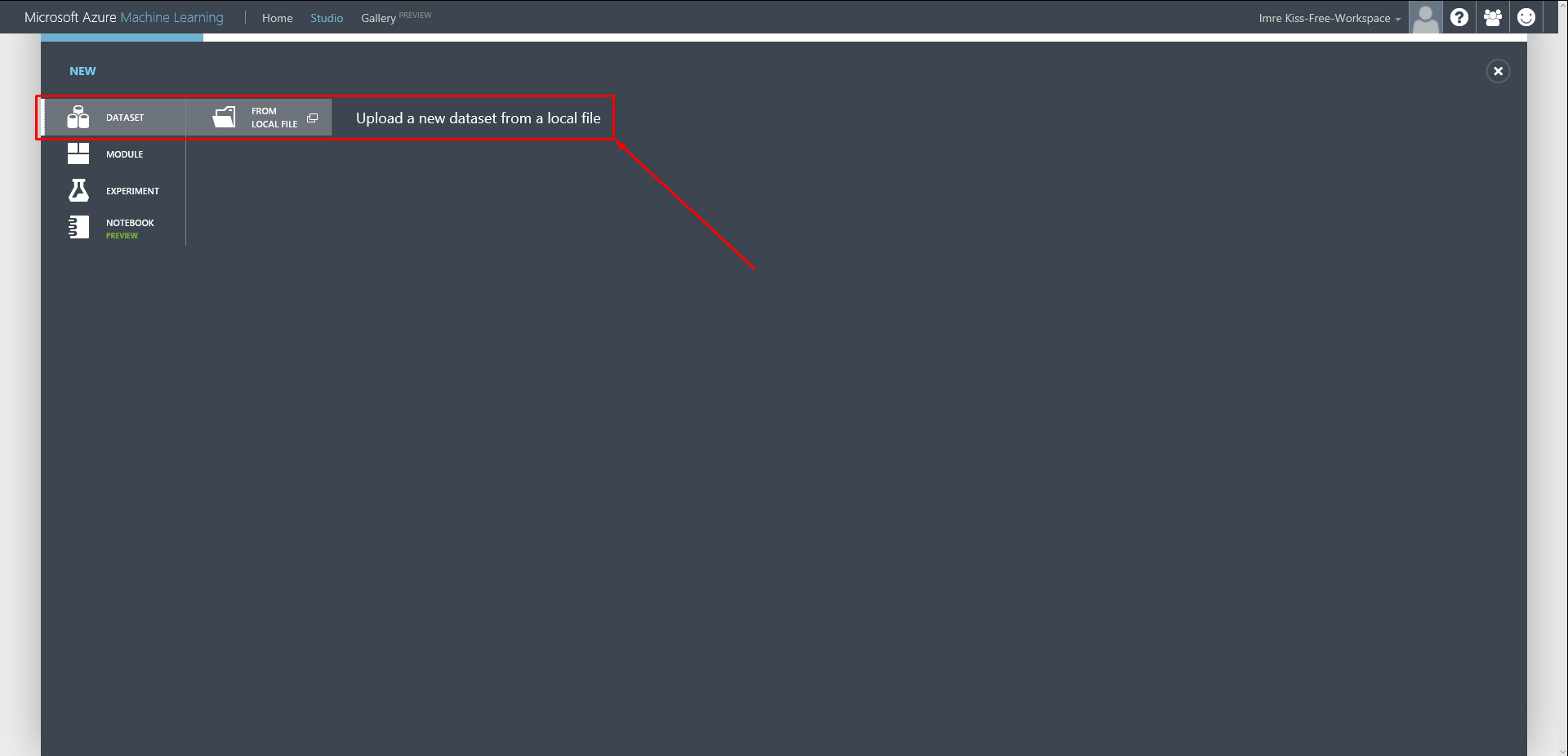
- Lépés: Válaszuk ki a DATASET és FROM LOCAL FILE opciókat.
- Lépés: A felnyíló Upload a new dataset ablakban keressük ki azt a fájlt amit fel szeretnénk tölteni (salary.txt állományt töltöttem fel, amely tabulátorral tagolt sima szöveges állomány).
- Lépés: Adjunk nevet az adathalmaznak, állítsuk be az adathalmaz típusát és opcionálisan adjunk meg valamilyen leírást is (erősen ajánlott akkor, ha később több adathalmazzal is szeretnénk dolgozni). Jelen példában megadtam milyen oszlopok találhatóak az adathalmazban.
- Lépés: A This is a new version of an existing dataset jelölőnégyzet segítségével engedélyezhetjük a rendszernek, hogy egy már meglévő adathalmazt akarunk frissíteni az aktuálisan kiválasztott állománnyal. Ha kipipáltuk, azután csak egyszerűen adjuk meg a létező adathalmazunk nevét. (Jelenleg egy teljesen új adathalmazt hozunk létre, tehát erre nincs szükség.)
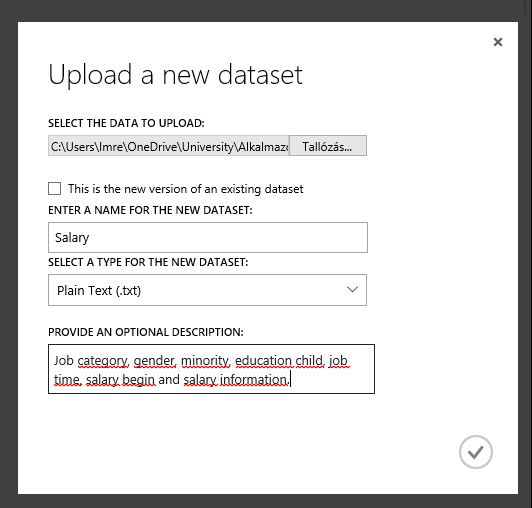
- Lépés: A jobb alsó sarokban található oké gombra kattintva a rendszer megkezdi az adatok feltöltését. Ez az adatok méretétől és a kapcsolati sebességünktől függően változhat.
Ha az adatok feltöltése befejeződött akkor az alsó menü szalagon kapunk értesítést arról, hogy sikeres vagy sikertelen volt-e a folyamat. (Az éppen futó folyamatok is itt találhatók.)
Amennyiben sikeres volt az adatok feltöltése, az újonnan létrehozott adathalmazunk a DATASET menüpont alatt rögtön megtalálható lesz, és léthatunk is néhány alap információt az adathalmazról.
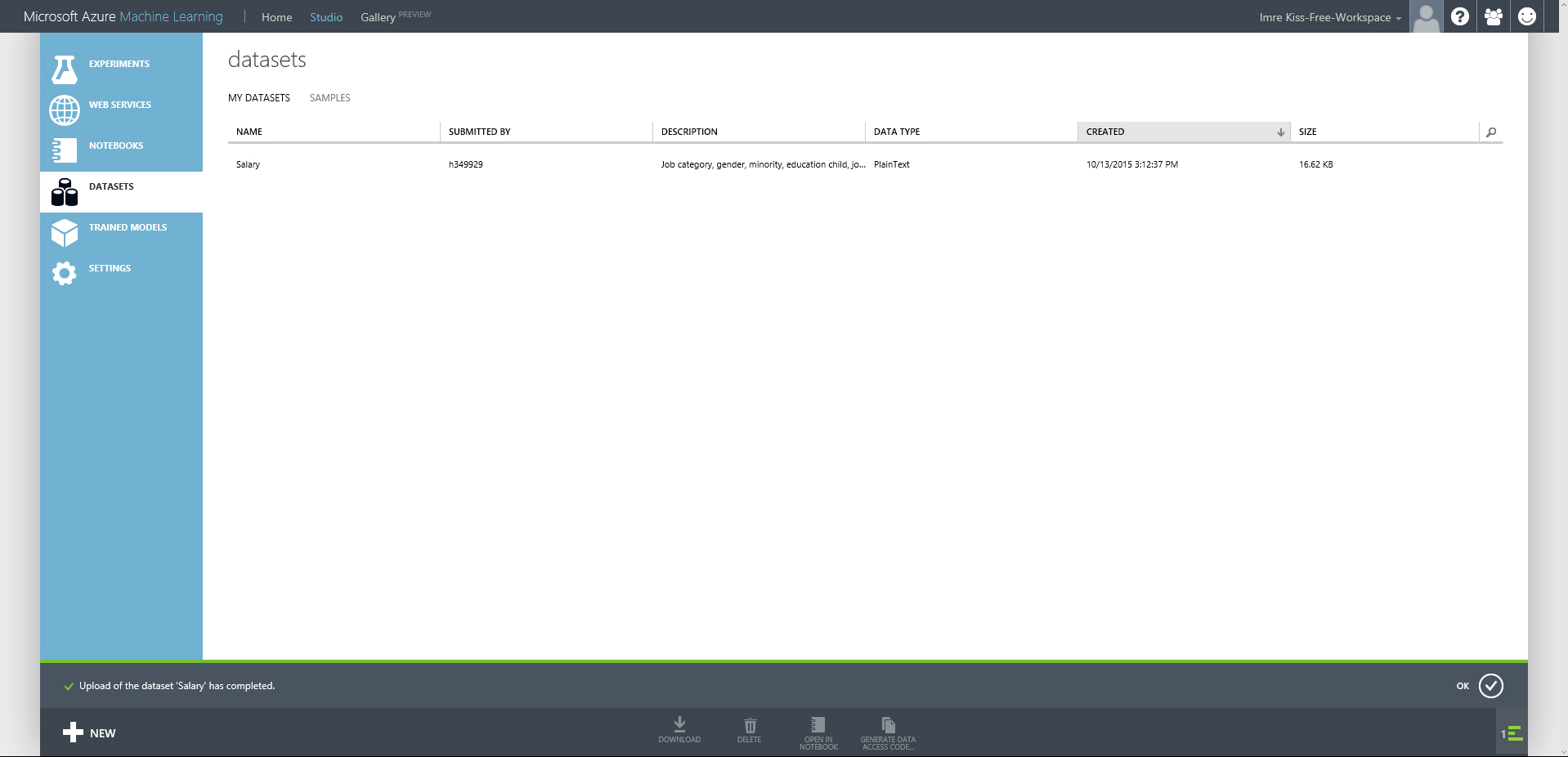
(Később amikor a kísérletünket állítjuk össze, a Saved Datasets menüpont alatt a bal oldali menüsávban megtalálható lesz az összes feltöltött adatunk és egyszerűen a drag-and-drop módszerrel használatba is vehetjük.)
Importálás Online forrásból
Az online források felhasználására már futó kísérlet közben van lehetőség. Ebben segít a Reader modul.
Használható források:
- A Web URL, HTTP használatával
- Hadoop, HiveQL használatával
- Azure blob tárhely
- Azure tábla
- Azure SQL adatbázis vagy Azure VM-en futó SQL Szerver
- Adathalmaz szolgáltató, jelenleg csak OData
Az adatforrások eléréséhez a kísérletben el kell helyezni egy Reader modult, amelynek csak megadjuk a hozzáférési paramétereket.
A következő linken a támogatott online adatforrások részletes leírásai találhatóak meg.
A későbbiekben fogunk még ezzel foglalkozni, amikor a HDInsight lesz a forrásunk.
Importálás meglévő kísérletből
Ha van már egy kísérletünk, és az abban felhasznált adathalmaz egy állapotát szeretnénk mondjuk használni a jelenlegi kísérletünkben, akkor a következő lépéseket kell tennünk ehhez:
- Lépés: Jobb gombbal kattintsunk arra a modulra, amelyiket el szeretnénk menteni mint adathalmaz.
- Lépés: A modul kimeneténél ki kell választani a Save as Dataset opciót.

- Lépés: A felugró ablakban adjunk nevet az adathalmaznak, amivel később könnyen tudjuk azonosítani.
- Lépés: Hagyjuk jóvá a mentést!
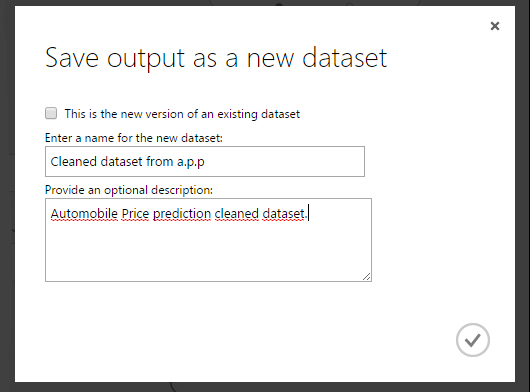
(Itt egy beépített példa kísérletet használtam fel arra, hogy bemutathassam hogyan működik az adatok kimentése.)
A folyamat végrehajtása után a mentett adathalmazunk szintén elérhető lesz a DATASETS menüpont alatt, és bármikor használhatjuk az új kísérletünkben (ugyanún a Saved Datasets menüpont alatt lesz elérhető a modul listában).
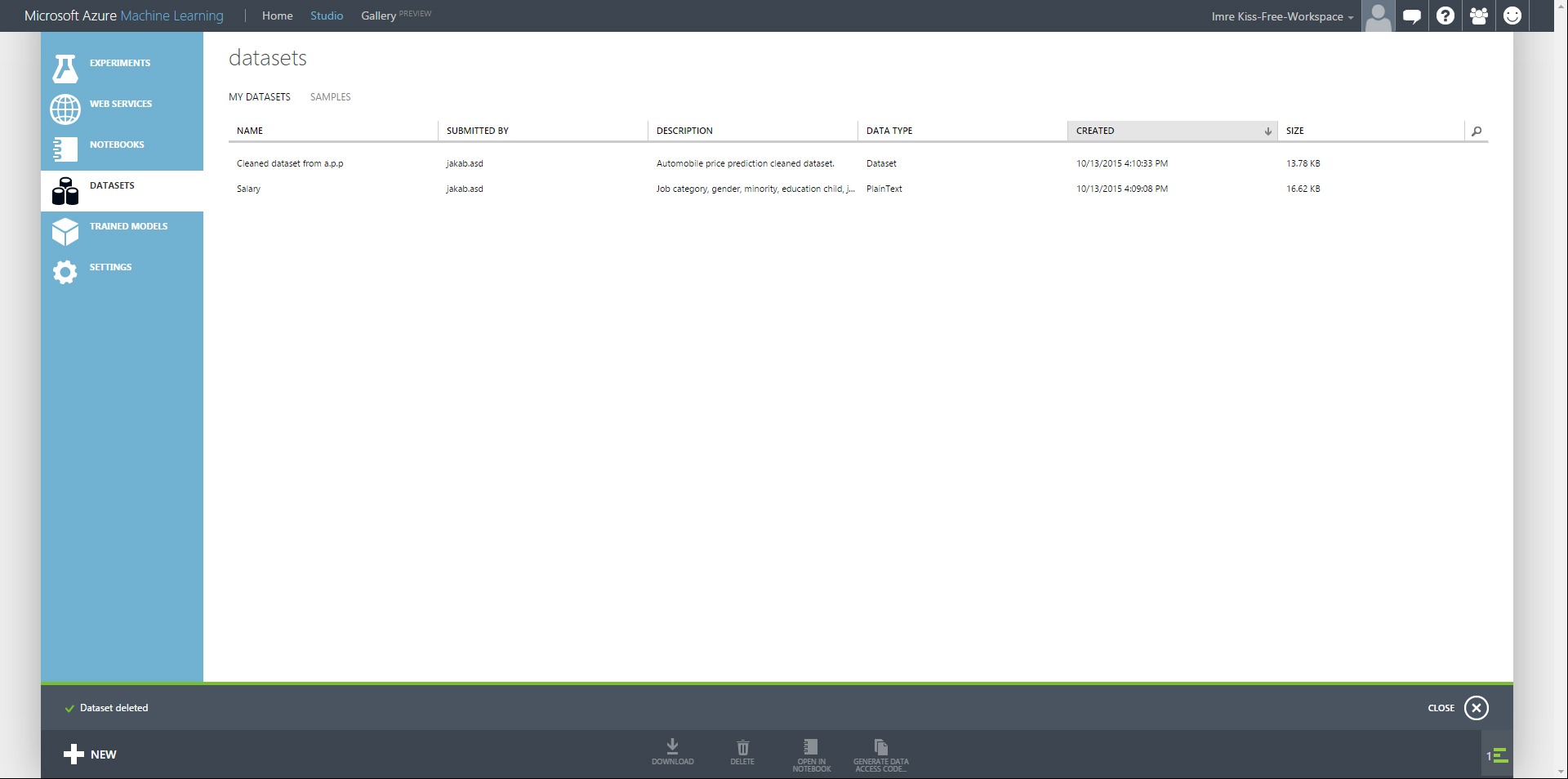
Megismerkedtünk az Azure ML Studio kínálta adatimportálási lehetőségekkel, támogatott formátumokat és típusokat is átvettük, majd megnéztük hogyan kell bizonyos területekről adatokat importálni. A következő bejegyzésben bővebben kifejtésre kerül az online forrásból történő adatimportálás.
Felhasznált forrás, a hivatalos Azure ML dokumentáció.