
Mi is az a Machine Learning?
Mit jelent pontosan a Machine Learning (későbbeikben ML)? Ma az ML egy csomó dolgot jelent. A terület elég nagy, és gyorsan növekszik, mert folyamatosan megosztjuk és vég nélkül ágaztatjuk a különböző szakterületeket és az ML típusait.
Úgy lehetne megfogalmazni, mint egy olyan rendszer, ami a tapasztalatokból fejlődik, vagy egy olyan metódus, amely az adatot szoftverré alakítja. A lényeg minden szempontból ugyanaz, a modern adattudomány sikeresen kifejlesztette a szoftver modellek létrehozásának olyan folyamatát, amelyek óriási adathalmazokból tanulva pontos mintákat és értékeket “jósolnak” számunkra.
Tom Mitchel 1997-ben adott egy tökéletes megfogalmazást: “Egy számítógépes program tanul a tapasztalatokból, ha a programot a tapasztalati példák feldolgozása után ismételten lefuttatva bizonyos teszt feladatokon, a program teljesítménye javul.“
Tehát a program figyelembe tudja venni a korábbi tapasztalatokból összegyűjtött információt a működése során úgy, hogy a saját működését módosítja. (Ehhez persze kell egyfajta felügyelet, hogy megmondjuk a kiszámított eredmény helyes lett-e.)
Ebben nagy segítségünkre van a prediktív analízis. Az ML és a prediktív analízis jól általában csak bizonyos körülmények között használhatóak ott, ahol képesek messze túlmutatni az általános működési szabályokon vagy halandók által fejlesztett programozási logikán.
Ezek után könnyen összehasonlíthatjuk a ma használt hagyományos programozási paradigmákat az ML paradigmával, hogy jobban megértsük miről is van szó:
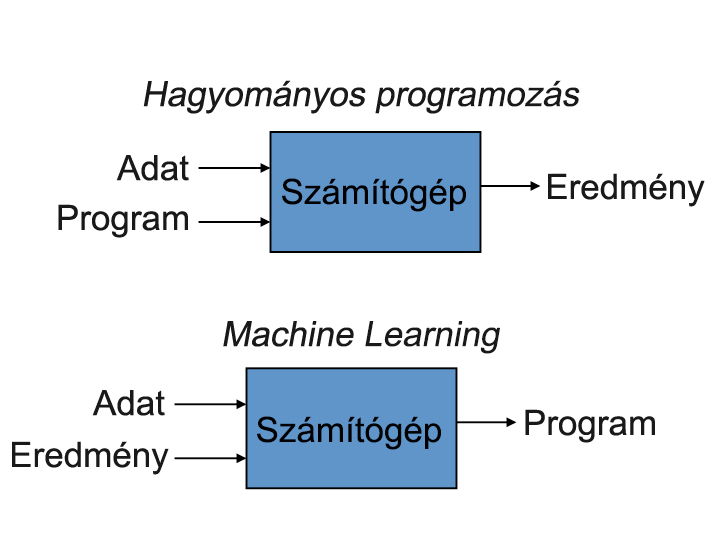
Ahogyan a mellékelt ábra is mutatja, a hagyományos programozási paradigmában, az adatok és a program feldolgozása adja a kívánt eredményt. Azonban az ML paradigmában az adatok és a kívánt eredmény “visszafejthetők” a számítógép által, amit felhasználunk egy új program létrehozására.
Az új programnak lesz egy olyan “erő” a birtokában, hogy képes hatékonyan megjósolni az eredményt, a rendelkezésre álló bemeneti adatok alapján. A fő előnye ennek a megközelítésnek az, hogy az eredményként kapott program már kitanított (vagy képzett) (a masszív mennyiségű tanulási adaton keresztül), finomhangolt (az eredmény adatainak visszacsatolásán keresztül) és képes arra, hogy megjósolja az elvárt eredménynek valószínűségét az előzőleg biztosított bemeneti adatok alapján.
A prediktív analízisre egy klasszikus példa az amazon.com. Minden egyes alkalommal, amikor keresünk valamit, az oldal felajánl nekünk még több eladásra váró terméket azzal az indokkal, hogy “akik vásároltak abból, amit keresel, szintén vásároltak ebből is” (nagyjából 🙂 ). Ez remek példája annak, hogy hogyan használjuk a prediktív analízist és az emberi vásárlási szokásokat arra, hogy egy jobb marketing stratégiát kapjunk.
Elmondhatjuk azt, hogy a prediktív analízis körülöttünk van nap mint nap. Nagy szerepet játszik a termelői-fogyasztói társadalom napi rutinjában. Lássunk még néhány példát, amelyek a prediktív analízis és az ML problémái közé tartoznak:
- “Ez rák?”,
- “Mi a kereskedelmi ára ennek a háznak?”,
- “Ezen emberek közül melyek a jó barátok?”,
- “Ez a rakéta hajtómű felrobban a felszálláskor?”,
- “Ez az ember szeretni fogja ezt a filmet?”
A valós problémák rendkívül összetett természete gyakran azt jelenti, hogy kitalálni egy speciális algoritmust, amely minden alkalommal tökéletesen megoldja a problémát, teljesíthetetlen, vagy lehetetlen.
Összességében arról van szó, hogy az ML megold problémákat, amiket nem lehet csak numerikus úton megoldani.
Jöhet az Azure…
(Azzal, hogy mi is az Azure, azt gondolom, nem igen kell foglalkozni egy olyan témában, ahol már célzottan az Azure ML-ről van szó, azonban ha mégis vannak felmerülő kérdések, akkor javaslom a következő link meglátogatását: Microsoft Azure )
Eddig átnéztük nagyjából, mi is az ML. Most beleássuk magunkat a mélyebb dolgokba, mindezt az Azure ML felől megközelítve.
Ahhoz, hogy később megfelelő döntéseket hozzunk a tervezésnél, tisztában kell lennünk néhány alapfogalommal és teóriával. Egyik központi témája az Azure ML-nek az volt, hogy gyorsan lehessen készíteni “kísérleteket”, majd azokat gyorsan ki lehessen értékelni azért, hogy előállíthassunk egy “jósló” modellt, ahol a végső cél az, hogy mindig egy kicsit jobb esélyünk legyen a sikerre (Ahogyan ezt eddig is láttuk.).
Az Azure ML magasszintű munkafolyamata:
A következő munkafolyamati ábra lépései sokat segítenek abban, hogy egy pillanat alatt hozhassunk létre prediktív analízis megoldásokat.
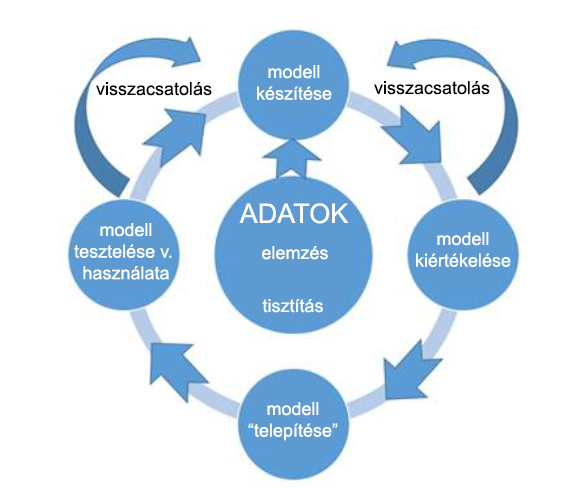
- Adatok: Minden erről szól! Ez a rész az, ahol összegyűjtjük, feldolgozzuk és elemezzük a tesztelési és tanulási adathalmazokat, hogy később felhasználjuk azokat az Azure ML prediktív modell létrehozásakor.
- Modell készítése: Számos ML algoritmus használható arra, hogy új modelleket hozzunk létre, amelyek képesek előrejelzéseket készíteni az adathalmazokból következtetve.
- A modell kiértékelése: Az új prediktív modell pontosságának vizsgálata a helyes eredmény jóslásának alapján, ha mind az input és output adatok értéke előre ismert.
- A modell finomítása és kiértékelése: Összehasonlítani és kombinálni kell váltakozó prediktív modellekkel, hogy megtaláljuk azt a megfelelő kombinációt, ami megadja számunkra a legpontosabb eredményt.
- Telepítés: Tegyük közzé a prediktív modellünket egy skálázható felhő alapú webszolgáltatásként, így könnyen elérhető bárhonnan az Interneten keresztül bármilyen böngészővel vagy mobil eszközzel mások számára is.
- Tesztelés és használat: Az új prediktív modell implementálása egy tesztelési vagy egy termelési elképzelésben. Hozzá kell adni a manuális vagy automatikus visszacsatolásokat, hogy a modell folyamatosan képes legyen fejlődni azáltal, hogy rögzíti a megfelelő részleteket, amikor egy pontos vagy pontatlan előrejelzést készített. Igen, a programnak lehetősége van arra, hogy rossz következtetést is hozhasson, azonban ebből is képes tanulni.
ML algoritmusok
Az ML algoritmusok tipikusan két csoportra oszthatók: ellenőrzött és ellenőrzés nélkül tanulás.
Ahogy egyre mélyebbre ásunk az Azure ML mögöttes adattudományába, fontos megjegyezni, hogy számos különböző ML algoritmus van (ezekről majd valamikor később).
- Osztályozó algoritmusok: Ezeket arra használják, hogy osztályozza az adatokat különböző kategóriákba, amit aztán fel lehet használni arra, hogy “megjósoljunk” egy vagy több diszkrét változót egyéb adathalmazban szereplő attribútumok alapján.
- Regressziós algoritmusok: “Megjósolnak” egy vagy több folyamatos változót, mint pl. profit vagy veszteség, egyéb adathalmazban szereplő attribútumok alapján.
- Klaszter algoritmusok: Ezek természetes csoportosításokat és mintákat határoznak meg adathalmazokon, és arra használják, hogy csoportosítási besorolásokat jósoljanak egy adott változóhoz.
Fontos, hogy megértsük a különbséget az Azure ML ellenőrzött és ellenőrzés nélküli tanulás fogalmai között. Az ellenőrzött tanulással a “jóslás” az “kitanított” az ismert input és output adatokkal. Ez a képzési folyamat készít egy olyan függvényt, ami aztán megjósolja jövőbeli output adatokat, amikor már csak az új input adatok állnak rendelkezésre. Ellenben az ellenőrzés nélküli tanulás esetén a rendszer kap egy köteg adatot, és meg kell találnia a mintát és a kapcsolatot közöttük.
Itt elsősorban az ellenőrzött tanulásra koncentrálunk, de a cikk végén kitérünk egy rövid áttekintés erejéig az ellenőrizetlen tanulásra is. 🙂
Ellenőrzött tanulás
Ez egy olyan típusa az ML algoritmusoknak, ahol ismert adathalmazt használnak a modell megalkotásához, amivel aztán képesek vagyunk előrejelzéseket készíteni. Az ismert adathalmazt másnéven kiképző vagy tanító adathalmaznak is hívjuk, és tartalmazza az input adatok mellett az ismert válaszértékeket (eredményeket) is. Ebből a tanító adathalmazból az ellenőrzött tanulás algoritmusa megpróbál építeni egy olyan új modellt, amely elkészíti az jövendölést az új input és ismert kimeneti eredmények alapján.
A következőkben három alapvető magasszintű lépést fogunk szemügyre venni, amelyek szükségesek ahhoz, hogy létrehozzuk, teszteljük és telepítsük az új ellenőrzött tanuláson alapuló Azure ML prediktív modellünket.
Az ellenőrzött tanulás további két általános algoritmus kategóriára bontható, osztályozó és regressziós algoritmusokra (Már volt róla szó, hogy mit is csinálnak ezek, nem fejtem ki újra 🙂 ).
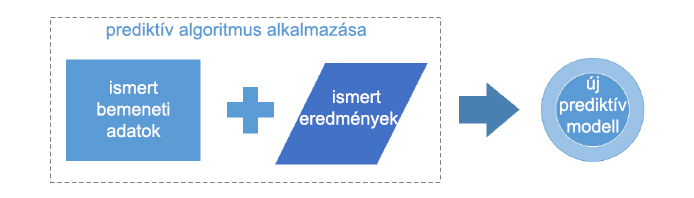
Az ábra egy új prediktív modell készítésének általános folyamatát illusztrálja, amely az ellenőrzött tanulást használja az ismert bemeneti adatelemekkel és ismert kimeneti eredményekkel azért, hogy egy teljesen új modellt alkosson. Az ellenőrzött tanulás elemzi az ismert bemeneti és ismert kimeneti eredményeket a tanító adathalmazból. Aztán ha az alkalmazott algoritmus alapján elkészítette a prediktív modellt, akkor az a modell képes lesz következtetéseket levonni az adatokból.
(Mostanra valamennyire tisztában kell lennünk az ellenőrzött tanulás fogalmával.)
Az egyik kulcsfogalom ahhoz, hogy megértsük az ellenőrzött tanulást használó megközelítést – azaz hogy tanítsuk a prediktív modellünket prediktív algoritmusokkal – az, hogy hogyan használjuk az ismert input adatok és az ismert eredmények elemeit, amelyek fel vannak “címkézve”. Minden egyes bemeneti sorban az adatelemeket megjelölik attól függően, hogy mire használják őket.
Alapvetően minden sor tanító adat tartalmazza az input adatelemeket, az azokra az adatokra ismert kimeneti eredményekkel együtt. Tipikusan a legtöbb input oszlop fel van “címkézve” mint jellemző vagy vektor változó. Ezek a címkézett oszlopok jelölik azokat az oszlopokat, amelyeket figyelembe kellene vennie a prediktív algoritmusnak, vagyis amiknek hatással kellene lenniük egy pontosabb jóslás elkészítésében.
Nagyon fontos, hogy az input adat minden sora tartalmaz egy oszlopot, ami megjelöli az ismert eredményt az input adatok jellemzőinek vagy vektorainak kombinációja alapján (mert itt természetesen a “tanító” adathalmazról van szó). Az input adat megmaradt oszlopait tekinthetnénk akár nem használtnak is. Ezeket a nem használt oszlopokat teljes biztonsággal ott hagyhatjuk az adatfolyamban későbbi felhasználásra, ha mondjuk úgy ítéljük meg egyszer, hogy azoknak az adatoknak jelentős hatásai lehetnek az eredményekre vagy a jósló folyamatra.
Összegzésül, ahhoz, hogy ellenőrzött tanulással közelítsünk meg egy új prediktív modell készítését szükségünk van “tanító” adatokra. Szükséges továbbá, hogy a “tanító” adathalmaz minden egyes oszlopa a következő három opció közül valahova be legyen sorolva:
- Jellemző vagy vektor: ismert adat, amit használunk mint bemeneti adat a jövendölés készítésekor.
- Címkék vagy felügyeleti jelek: az input rekord megfelelő jellemzőjét reprezentáló ismert eredmény.
- Nem használt (alapértelmezett): amiket nem használ a prediktív algoritmus.
A következő ábra azt illusztrálja, hogyan is néz ki egy ilyen bemeneti adathalmaz, az ismert bemeneti adatjellemzőkkel és az ismert eredményekkel együtt. ( Ez a példa az Azure Machine Learning “bináris fizetési osztályozás” mentett adatbázisából van. )
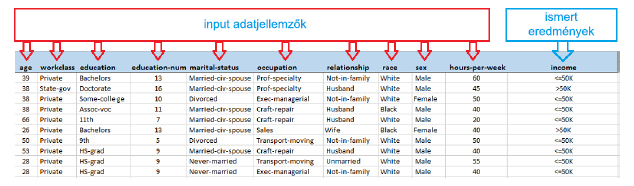
Ez a bináris fizetési osztályozás lehetne a tanító adathalmaz, amit használhatnánk egy olyan prediktív modell létrehozásához, amely megjósolja, hogy vajon egy személy fizetése nagyobb vagy kevesebb lesz-e mint 50k dollár. Ez a jóslás olyan bemeneti adatokon alapulna, mint pl. életkor, megszerzett tudás, munka típusa, családi állapot, nem és heti munkaórák száma.
Egy fontos dolog, amit meg kell jegyezni, hogy ebben a példában a “bináris” eredmény definiálva van az átadott bemeneti adatnak. A bemeneti elemek alapján egy személy fizetésének megjóslása a következő két eshetőség közül valamelyik lesz:
- A fizetés kevesebb vagy egyenlő, mint 50k egy évben.
- A fizetés nagyobb, mint 50k egy évben.
Ha ezt a tanító adathalmazt böngésszük mondjuk egy Microsoft Excel programban, akkor akár már most is könnyen találhatunk benne mintákat, amik hatással vannak az eredményre, ezeket a mai tudásunkra alapozva is láthatjuk, hogy különösen az oktatás és a munkahelyi elhelyezkedés a legfőbb tényező az eredmények becslésében. Ez szintén ugyanaz az alapvető folyamat, amit az ellenőrizett tanulási jóslatalgoritmusok megpróbálnak megvalósítani: meghatározni a következtetésnek egy olyan ismétlődő mintáját, amit felhasználhatnak egy új input adathalmazban.
Itt jön az, hogy az egyszer legenerált modell pontosabb lesz a “tanító” adathalmaz miatt. Ez a pont az, ahol a dolgok kezdenek végre érdekesebbek lenni azáltal, hogy ha nagyobb és változatosabb “tanító” adathalmazt használunk, akkor a prediktív modellünk hatványozottan képes megnöveli hatékonyságát és képes tanulni tovább és tovább.
A prediktív modellek általában jobb pontosságot képesek elérni, ha biztosítunk a számukra új ( és sokkal inkább aktuális ) adathalmazt. A következő ábra a jóslat kiértékelő folyamatát mutatja.

Az ellenőrzött tanulást használó új prediktív modellek kiértékelésének folyamata elsősorban az új generált modell pontosságának meghatározásából áll. Ebben az esetben a prediktív modell pontossága könnyen meghatározható, mert a bemeneti adatok és az eredmények már ismertek. A kérdés már az, hogy hogyan közelíthető a modell jóslata az ismert bemeneti és kimeneti értékek alapján.
Minden egyes alkalommal, amikor a prediktív modellt legeneráljuk, az első lépésnek mindig annak kell lennie, hogy kiértékeljük az végeredményt, azért, hogy meghatározzuk a modell pontosságát. Ez ad egy természetes visszacsatolást, ami segít folyamatos fejlődési módban tartani a mi kis prediktív modellünket. A “gép” így most tanul a “tapasztalatokból”.
ITT fontos megjegyezni azt, hogy a modell SOHA nem lesz 100%-ban tökéletes. Fontos és kritikus része a folyamatnak, hogy a pontosság elfogadható szintjét meg kell határozni. A végén a bizalmi tényező a pontozási százalék alapján 0 és 1 között fog alakulni. Elérni a 100százalékos pontosságot általában azt jelenti, hogy előtesztelned kell a prediktív modelledet az összes ismert input és outputtal, azután meg tudod jósolni azokat az összes input példánnyal.
Az igazi trükk az abban van, hogy úgy készíts jóslást, hogy az adatelemek újak, hiányosak vagy befejezetlenek. Ezért, mindig számításba kell venni egy olyan pontossági tartomány meghatározását, ami realisztikus a modelled eredményéhez mérten. Persze a tökéletes pontosságra való törekvés szép dolog, de a mai rohanó világban, főleg az üzleti világban, a “közeli” eredmények mindig jobbak.
Miután a prediktív modell elkészült a jó adathalmazból, és gondosan ki lett értékelve a pontosság növelése érdekében, azután telepíthető tesztelés vagy termelés céljából.
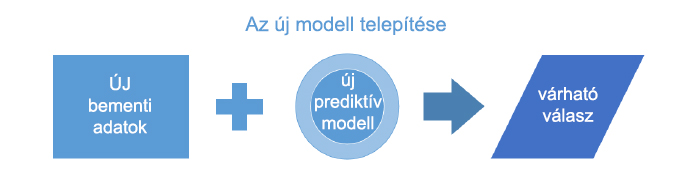
Ebben a fázisban az új prediktív modell tesztelve van a pontosság miatt, és elég jónak minősített ahhoz, hogy felhasználható legyen tesztelési vagy termelési elképzelésekhez. Az új bemeneti adatok prezentálva lettek az új modellhez, amely ezért készít egy kiszámított jóslatot korábbi adatok és következtetések alapján. Végül a várható válasz vagy jóslat használható a teszt vagy termelési elképzelésben ahhoz, hogy jobb döntést hozzunk.
Végül nézzük az ellenőrzés nélküli tanulást.
Tipikusan arról van itt szó, hogy megkeressük a kapcsolatot az adatok között. Nem használunk kiképző adatokat a folyamatok alatt. Helyette a rendszernek átadunk egy adathalmazt, és azokban keresi meg a mintákat és kapcsolatokat. Egy jó példa erre a szorosan összefüggő baráti csoportok azonosítása egy szociális hálózatban.
Azok az algoritmusok amiket itt használunk nagyon különböznek azoktól, amiket az ellenőrzött ML-ben használtunk.
Néhány példa:
- csoportosítási algoritmusok
- dimenzionalitás csökkentő rednszer, mint pl főkomponens elemzés
Nos amiről itt szó volt, az kiemeli a tapasztalati úton történő tanulás alapelveit és azt, hogy mi teszi az Azure ML-t olyan erőssé és izgalmassá.