
Az előző bejegyzésben eljutottam addig, hogy megvan a tisztán csak feature selection modul által javasolt feature listám. Ez rendben is van. Ebben a bejegyzésben viszont egy kis kitérőt fogok tenni, amiben csak annyit szeretnék elvégezni, hogy a rendelkezésre álló adatokat normalizáljuk (elsősorban azért, mert mint említettem egy kis utána olvasás után és nálam komolyabban a témához értő emberek iránymutatása azt az eredményt adta nekem, hogy a leginkább célravezető feature selection method ilyen esetben az a mutual information, amihez – és egyébként is – jobb a normalizált adathalmaz).
Normalizálás
Ehhez a Normalize Data modult használntam. Mit is csinál ez a modul? Egyszerűen fogja az adathalmazt és a megadott oszlopokban (igen, lehet egy vagy akár több oszlopot is egyszerre ugyanabban az adathalmazban manipulálni a modul segítségével) a nagyon eltérő értékeket – amik nagy valószínűséggel elég sok gondot okoznának, amikor dolgozni szeretnénk velük a modellezés során – egy általános, közös intervallumba fogja őket konvertálni. Természetesen itt numerikus adatok normalizálásáról van szó. Ha más jellegű adatokat is szeretnénk normalizálni, akkor bizony ki kell találni, hogy hogyan csinálok belőle valami numerikus alapú értéket.
Hogyan állítottam be a modult?
Miután hozzáadtam a munkaterülethez a modult, fogtam a tesztelésre szánt adathalmazomat (és természetesen majd külön-külön mindegyiket, mert jelenleg szét vannak bontva), és bekötöttem a modul bemenetére. A column Selector segítségével egyszerűen ki tudtam volna válogatni azokat az oszlopokat amiket normalizálni szertettem volna (ismét kiemelem, hogy ezek mind numerikus típusú adatok), de erre nincs szükség abban az esetben ha nincs extra igényünk, ugyanis alapjáraton a modul rögtön fogja az összes numerikus adatunkat és beteszi a listába. Ezután kiválasztottam, hogy melyik matematikai függvényt használjam. Több lehetőség áll a rendelkezésünkre:
- Zscore: minden egyes érték egy z-score értékre lesz konvertálva a következő képlet alapján:
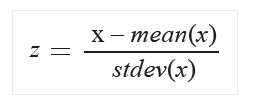
A mean (azaz az átlag) és a stdev (azaz a szórás) minden egyes oszlopra külön-külön kiszámításra kerül (és ebben az esetben populáció alapú szórást használ az algoritmus). - MinMax: egyszerű, lineárisan újraskáláz minden feture-t a [0,1] intervallumban, a következő képlet alapján:
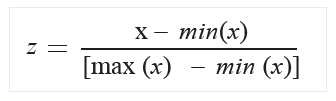
Nem gondolnám, hogy ezt nagyon részleteznem kellene. - Logistic: hát, ehhez a hivatalos oldalon csupán a képletet találtam, de ez sem bonyolult:
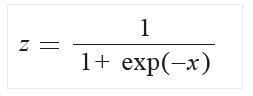
- LogNormal: itt a képlet felhasználja az eloszlást és az emirikusan kiszámított maximum likelihood becslést minden egyes oszlopra, amelyeket a mű és a szigma képvisel:
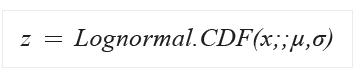
- TanH: egy hiberbola tangens segít a művelet elvégésében:
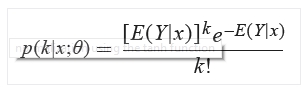
Ezek alapján első nekifutásra a LogNormal opciót választottam.
Összehasonlításképpen a teszt adathalmaz a normalizálás előtt így nézett ki (természetesen részlet kép következik):
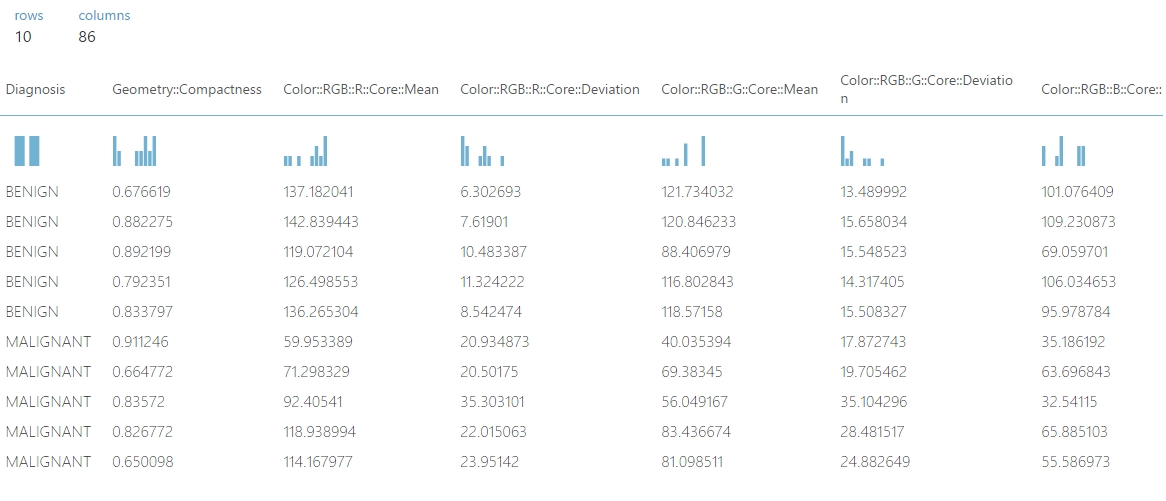
Majd a normalizálás után ez lett belőle:
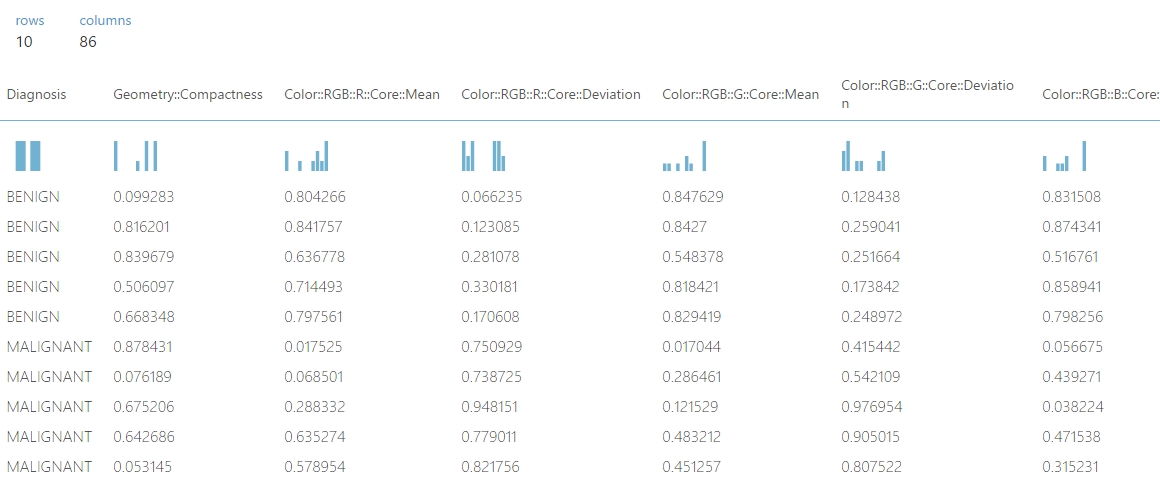
Ha jobban szemügyre vesszük az egyes értékek változását, akkor szépen látszik, hogy arányaihoz képest minden tökéletes.
A normalize data modulhoz még annyit fűznék hozzá, hogy egy ilyen normalizálás után, a modul jobb kimenetén a normalizáló transzformációt el tudjuk menteni, amit a későbbiek során egy Apply Transformation modul segítségével bárhol újra fel tudunk használni.
Az adathalmaz globális felkészítéséről egyenlőre ennyit, ezentúl már ha módosításokra kerül sor, azok részhalmazokon fog történni.