
Miután az adatainkat rendeztük, szétvágtuk, alakítottuk, kezdhetjük a megfelelő Feature halmaz meghatározását. Mint már tudjuk, ehhez maga az Azure is számos megoldást kínál, de csinálhatjuk ezt manuálisan is (ha tudunk valami olyat amit a gép nem 😀 ). Tehát az anyajegyek adathalmazunkban jelenleg mik lesznek a meghatározó feature elemek, amelyeket az osztályozáshoz fogunk használni?
Azure Feature Selection
Korábban már mutattam néhány modult, ami a Feature Selection-al (illetve Péter bejegyzései között is találtok hasonló hasznos leírást). Ehhez a kísérlethez több oldalról is meg szerettem volna vizsgálni, hogy mi lesz az ideális feature halmaz. Ehhez a Filter Based Feature Selection modult használtam fel. Ez a modul segít meghatározni a bemeneti adathalmaz legerőteljesebb prediktív képességgel bíró feature halmazt. A modulban használt algoritmushoz meg lehet adni, hogy milyen pontozási metódus segítse a munkát, ezek:
- Pearson Correlation
- Mutual Information
- Kendall Correlation
- Spearman Correlation
- Chi Squared
- Fisher Score
- Count Based
Szerettem volna egy valóban központi magot megkapni az adatokból, teljes manipuláció nélkül. Ehhez fogtam 6 darab ilyen modult és külön-külön majdnem mindegyik pontozási metódust lefuttattam az adathalmazon. Az összevont adathalmaz kimenetét rákötöttem mind a 6 modul bemenetére majd a modulok tulajdonságainál megadtam, hogy 10 feature-t szeretnék eredmény kapni (ezt a Number of desired feature mezőben tehetjük meg). Majd kiválasztottam a Target column segítségével, hogy a Diagnosis oszlop tartalmazza a címkéket, illetve megadtam, hogy aktuálisan a modul melyik pontozási metódust használja (ezt a tulajdonságok tetején állíthatjuk be a Feature scoring method legördülő listából).
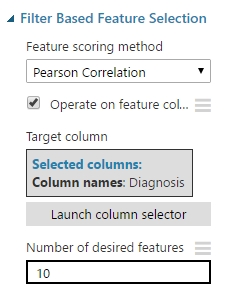
Miután a képeken látható módon beállítottam minden egyes modult, és a kísérletet le is futtattam akkor minden egyes FBFS modul kimenetén megkaptam, hogy az adott pontozási metódus alapján melyik 10 oszlopot választotta a rendszer feature-nek. (Az eredményt megtekinthetjük ha a modul bal oldalsó kimenetére kattintunk, majd a Vizualize opciót használjuk).
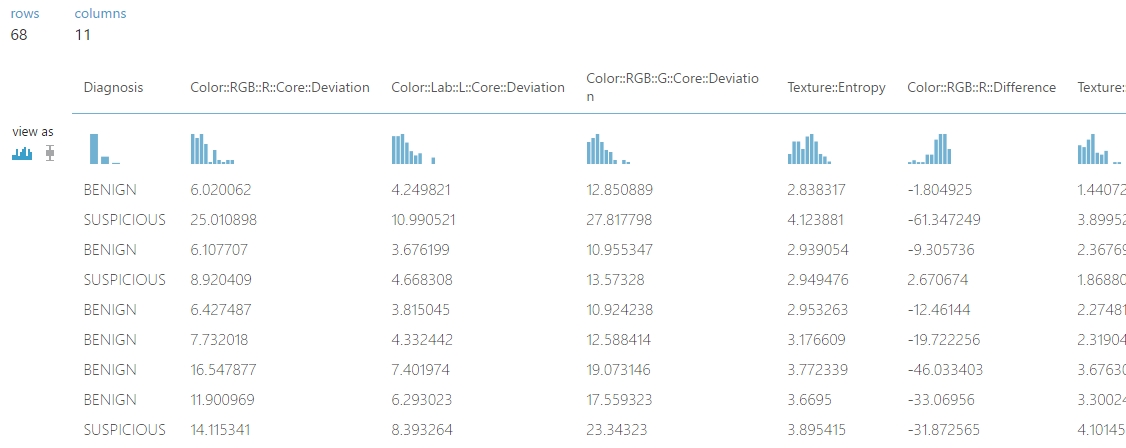
(11 oszlopot jelöl a kimenet, holott csak 10 feature-t kértünk, ez csak azért van, mert a target column azaz a címnke is bekerül a listába.)
Miután az összes modul kiválogatta a szerinte leginkább fontos fetaureöket, fogtam és egy excel táblában kigyűjtöttem, hogy egy adott pontozási módszer melyik oszlopot választotta:
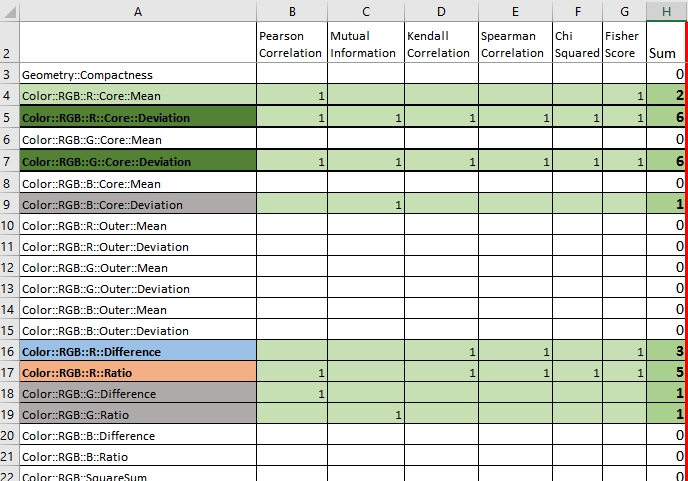
Minden egyes (az adathalmazban fellelhető) oszlophoz bejelöltem, hogy az adott módszer megjelölte-e, majd összegeztem, hogy az adott oszlop hányszor lett megjelölve mint Feature. Majd egy elég gyenge prioritási listában összeszedtem azokat, amelyek legalább egyszer meg lettek jelölve, így kaptam egy szűkebb keresztmetszetet:
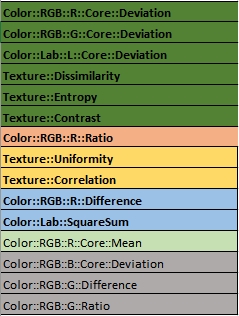 Jól látszik, hogy melyek azok amik mindegyik vagy majdnem mindegyik modul megjelölt, illetve melyek azok amik épphogy belekerültek a listába. Ezzel a listával egy általánosabb 15 elemből álló Feature listát kaptam az adathalmazomról.
Jól látszik, hogy melyek azok amik mindegyik vagy majdnem mindegyik modul megjelölt, illetve melyek azok amik épphogy belekerültek a listába. Ezzel a listával egy általánosabb 15 elemből álló Feature listát kaptam az adathalmazomról.
Természetesen a megfelelő szűrő alapú feature kereséshez használható egyetlen pontozó algoritmus is, ha tudjuk az adataink milyen jellegűek és, hogy mi az amit meg akarunk majd “jósolni” akkor egy algoritmus is nagyon jó eredményeket adhat. Ez jelen esetben egy ilyen jellegű adathalmaznál és a kétosztályos tanulás miatt, a Mutual Information pontozó metódus egy jó választásnak tűnik.
Megjegyzés: a gyakorlatban az adathalmaz oszlopainak a számának 10%-a szokott lenni a kiválasztott feature-ök száma. (sok esetben, de ezt nem kötelező tartani)