Miért a .Net, ha nincs „natív” képfelismerő?
Habár egyesek szerint van C#-nál jobb nyelv képfelismerő/feldolgozó alkalmazást írni, én a személyes (és munkahelyi) preferenciáim miatt inkább .Net vonalon képzelem el a programot. Mivel .NET Core használatával már Linux is célozható platformként, így amennyiben rendelkezésre áll egy megfelelő OpenCV wrappert vagy egy megfelelő képfelismerő alkalmazás, akkor multiplatformmá alakítható lehet az alkalmazás.
Továbbá, amennyiben iOS, Android, Windows Phone 10 eszközökön is elfogadható sebességgel fut a kérdőívek feldolgozása, akkor a Xamarin segítségével aránylag egyszerűen multiplatformosíthatóvá válik.
De természetesen ebben az esetben hatalmas időt is felemészthetne a QA, tehát ez a része nincs tervben, esetleg csak működő demo szintjén, összehasonlításban érdekes lenne, hogy a különböző operációs rendszerű telefonok miként viselkednek, illetve mennyivel lett gyorsabbak az újabb telefonok.
Miért az EmguCV?
A projekt kezdetekor én abban a hitben éltem, hogy van millió fajta képfelismerő C#/.NET-hez. Mint kicsit később kiderült tévedtem, jelentősen kevesebb van mint gondoltam. Néhányat már valamennyire ismertem, példának okáért a Matlab Image Processing Toolbox-ot, aminek a tudásán csak az ára tesz túl. Ugyanakkor, ha ezt használnám, akkor az ágyúval lőni bolhára eset állna fent: egyszerűen túl sokat tud, nekem pedig nem lesz annyira sokrétű az alkalmazásom, hogy a tudása tizedét is kihasználjam.
Open-source vizekre próbáltam evezni, már a (jellemzően) kedvezőbb licenszfeltételek miatt. Találtam is egy egészen korrektnek tűnő BSD licenszes segédletet: OpenCV.
Azonban ez csak C++-os library. De szerencsére, elég sok nyelven készül hozzá wrapper szerencsére C#-hoz is, ez lenne az EmguCV. Üröm, az örömben, hogy licenszfeltétele nem olyan engedékeny. Viszont támogatja az UWP-től kezdve a Xamarin-os appfejlesztést is, így ha esetleg multiplatformosítani akarnám az alkalmazást, akkor relatíve egyszerűen megtehetem.
Mi is az EmguCV?
Emgu CV is a cross platform .Net wrapper to the OpenCV image processing library. Allowing OpenCV functions to be called from .NET compatible languages such as C#, VB, VC++, IronPython etc. The wrapper can be compiled in Mono and run on Windows, Linux, Mac OS X, iPhone, iPad and Android devices.
Nos funkciók tekintetében ez az „image processing library” jött be leginkább, alább le is írom miért.
Kezdeném az OpenCL támogatással, ami eléggé meggyorsíthatja a képek feldolgozásának sebességét, ezt tesztek széleskörűen igazolják, persze kérdéses, hogy mennyit lehet majd az én programomban ebből kimérni. (Lesz majd összehasonlítás.) Egyetlen egy hátulütőről olvastam ezzel kapcsolatban, hogy figyeljek a grafikus meghajtókra, mert AMD kártyákon előfordultak lassulások, hibás eredmények.
Folytatva a sort, a CUDA támogatás is erősen plusz pont, de ez függ a programom használati helyétől, sajnos ezt az aspektust nem fogom tudni valószínűleg tesztelni, mivel otthoni számítógépemben Radeon van, munkahelyi GT210-es pedig annyira gyenge, hogy összehasonlítási alapnak rettenetes.
Tesseract OCR-t a listába belevenni kicsit fals dolog, mivel ez egy Google által szponzorált opensource library karakterfelismeréshez, amiről legtöbben elégedetten beszélnek, ugyanakkor része az EmguCV-s „csomagnak”, pluszban ez így lerövidítette az időt, amit OCR-ek keresésével kellett töltenem.
Szerencsére cross-platform, így linuxon futtatás is szóbajöhet, bár személy szerint engem jobban érdekelne ennél, hogy Apple A8-A10 processzoron milyen sebességű a képfeldolgozás, illetve ugyanez Androidos/Windows Phone-os telefonokon az Adreno IGP-vel.

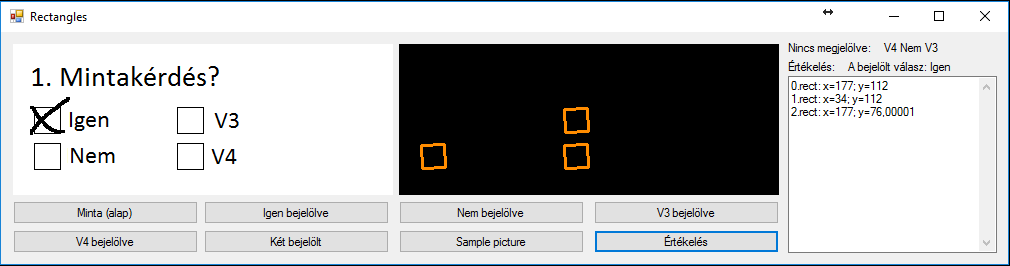
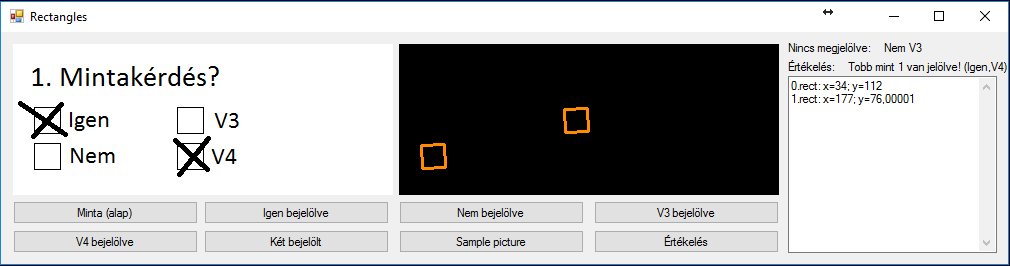
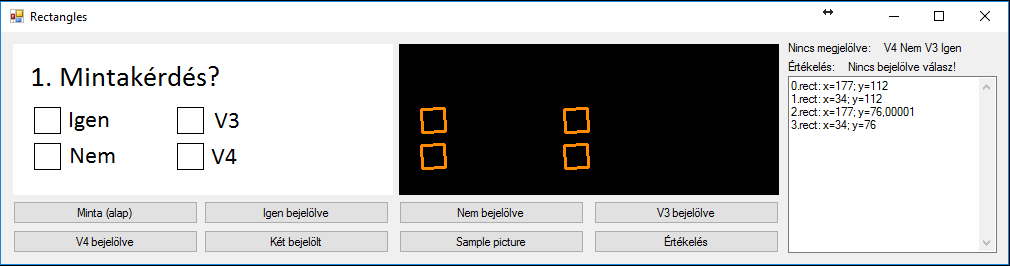 Jobb oldali TextBoxban pedig az algoritmusom munkája látszik, megnézi, hogy a négyzetek közül melyek vannak bejelölve, illetve kiírja a négyzetek középpontjainak a koordinátáit. Amennyiben be van jelölve egy opció, akkor a válaszhoz tartozó négyzetet nem látja a képfelismerő, ahogy az a következő példán is látszik:
Jobb oldali TextBoxban pedig az algoritmusom munkája látszik, megnézi, hogy a négyzetek közül melyek vannak bejelölve, illetve kiírja a négyzetek középpontjainak a koordinátáit. Amennyiben be van jelölve egy opció, akkor a válaszhoz tartozó négyzetet nem látja a képfelismerő, ahogy az a következő példán is látszik: