
Egy képről megállapítani, hogy mi látható rajta, az emberek számára nem bonyolult feladat. Különös erőfeszítés nélkül képesek vagyunk a körülöttünk levő tárgyakat címkékkel ellátni. A számítógépek viszont nem rendelkeznek ilyen tulajdonsággal. Ahhoz hogy mégis képesek legyenek ezekre a dolgokra, neurális hálók segítségével kell megtanítani őket.
Képek osztályozására használatos konvolúciós neurális hálók területe 2012-től robbanásszerűen kezdett fejlődni, amikor Alex Krizhevsky megnyerte az ImageNet versenyét azzal, hogy a hibázási rátát 26%-ról 15%-ra csökkentette.
CNN(Convolutional Neural Network) használatakor a gép egy képet kap inputként, amit pixelértékekből álló tömbként tud feldolgozni. Ennek a tömbnek a mérete függ a kép felbontásától és méretétől. Tehát ha veszünk egy színes 480×480-as JPG formátumú képet a számítógépünk egy 480x480x3-as tömböt fog látni, melynek értékei 0 és 255 közötti intervallumban helyezkednek el. A tanulási folyamat végén pedig megkapjuk milyen valószínűséggel tartozik az input kép az egyes kategóriákba. Ahhoz, hogy az inputból megkapjuk az outputot, a képet a CNN-t alkotó rétegek sorozatán juttatjuk keresztül. Ezek a rétegek különböző feladatot látnak el, így jutunk el például egy kutya esetén az egyenes illetve görbe vonalaktól a mancson, orron keresztül a teljes élőlény felismeréséig.
De mik is ezek a rétegek és hogyan működnek?
Convolutional Layers:
Ahogyan fent említettem van egy pixelértékekből álló input tömb, amit ez a réteg kap meg bemenetként. Emellett vannak filtereink, melyek ugyancsak számokból álló tömbök.
A filtert az input “fölé” helyezve, annak bal felső sarkából horizontális és vertikális csúsztatásokkal a jobb alsó sarkába jutunk. A csúsztatások során az eredeti kép adott részének pixelértékeinek és a filter értékeinek összeszorozzuk, majd összeadjuk, így kapva egy újabb tömb egy elemét.
Fontos megjegyezni, hogy a filter mélységének meg kell egyeznie az input mélységével.
Tehát ha van egy 32x32x3-as inputunk és egy 5x5x3-as filterünk és egy egységenként mozgatjuk a filterünk, akkor 784 különböző pozícióban lesz az inputon belül, ezáltal egy 28×28-as úgynevezett activation mapet kapunk.
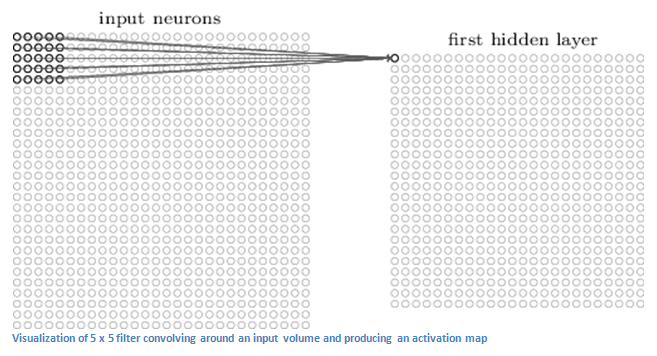
Természetesen a mozgatás mértéke lehet nagyobb is, ekkor viszont kisebb activation mapet kapunk.
Miért jó ez nekünk? A különböző filterek egyszerű alakzatok, színek, úgynevezett low level feature felismerését teszi lehetővé.
ReLU (Rectified Linear Units) Layers:
Általában conv layerek után valamilyen nonlinear layert szokás alkalmazni. A kutatások alapján a ReLu jobbnak bizonyult, mint például a sigmoid így a neurális hálózatunk sokkal gyorsabban képes tanulni. Egyszerűen fogalmazva egy függvényt alkalmaz a réteg az inputra, mely a negatív számokat nullává alakítja.
Pooling Layers:
Ennél a rétegnél is találunk filtert, mellyel csökkentjük az inputként kapott tömb méretét. Ebben a rétegben a filtert a nagyságával megegyező méretű egységekkel csúsztatjuk keresztül. Különböző módszerek alapján lehet létrehozni az inputot.
Az egyik legnépszerűbb a maxpooling, az input filterrel meghatározott részterületének legnagyobb értékét veszi. Itt kevésbé lesz fontos a feature abszolút helyzete, mint a relatív pozíciója a többi feature-höz képest.
Vigyázni kell viszont az overfitting kialakulásának veszélyére. Overfitting esetén a modell a tanulási példákon 99-100%-os sikert ér el, viszont a validációs illetve teszt adatokon jóval kisebbet, 50% környéki eredményt. Ennek oka, hogy a háló súlyai túlságosan a teszt adatokra lett hangolva.
Ennek megoldására találták ki a dropout layert.
Dropout Layers:
Az overfitting problémáját nagyon egyszerűen oldja meg. Az input tömb véletlenszerű elemeit nullára állítja, így megakadályozva hogy túlságosan a teszt adatokra igazodjon a modell.
Ezáltal a neurális hálónak redundánsnak kell lennie, azaz bizonyos információ kiesése esetén is helyes osztályozást kell hoznia. Ez a réteg csak a tanítási folyamatban használható.
Fully Connected Layers:
Ennek a rétegnek a feladata az előző rétegek által meghatározott bonyolultabb alakzatok, high level feature alapján osztályba sorolni a képet. Outputként egy n-dimenziós vektort ad, ahol n azon osztályok száma, amelyekből a programnak választania kell.
Eredményként tizedestörtek tömbjét kapunk, mely megmondja mekkora a valószínűsége, hogy az adott osztályba tartozik a kép.
Ezen rétegek sorozatával lehet megalkotni a konvolúciós neurális hálózatunkat. De honnan tudja a modell, hogy milyen filtereket kell használni? Ezt a tanulási folyamat adja meg, amit backpropagationnek hívunk.
Backpropagation:
Négy részből áll: forward pass, loss function, backward pass, és a weight update.
Forward pass: Az a folyamat amikor a tanítás során a képet legelőször adjuk meg a modellünknek. A filterek és súlyok véletlenszerűen lettek inicializálva, így semmilyen következtetést nem tud adni a háló.
Loss function: A forward passt követő szakasz. A kép mellé tartozó címkével meghatározzunk a következő függvényt:
![]()
A veszteség mértéke eleinte magas lesz.
Backward pass: A loss értékét minimalizálni szeretnénk, tehát kideríteni visszafelé lépegetve a hálóban, melyik súlyok vezettek ehhez az állapothoz.
Weight update: A súlyokat itt módosítjuk. A learning rate megválasztása a mi feladatunk, a magasabb érték gyorsabban vezethet az optimális súlybeállításokhoz. Azonban túl nagy érték esetén nem lesz elég precíz, hogy elérje az optimális pontot.
![]()
Ezeknek a lépéseknek egy sorozata egy tanulási iteráció. Egy általunk megadott számú iterációig fog folyni a tanulás. Ha végetért, remélhetőleg helyes osztályozásra lesz képes a neurális hálónk a beállított súlyokkal.
Részletesebb leírásért és további információkért a következő weboldalakat tudom ajánlani:
https://adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/
http://neuralnetworksanddeeplearning.com/
Az előbbi weboldalak megértéséhez nagy segítséget nyújtottak az alábbi videók:
https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi
https://www.youtube.com/watch?v=FmpDIaiMIeA